Modeling
- nn.Sequential
- Sub-class of nn.Module
import torch
from torch import nn
import torch.nn.functional as Fnn의 모듈
nn.Conv2d(
in_channels=3,
out_channels=32,
kernel_size=3,
stride=1,
padding=1,
bias=False
)nn.Linear(
in_features=784,
out_features=500,
bias=False
)nn.Sequential
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = nn.Sequential(
nn.Linear(784, 15),
nn.Sigmoid(),
nn.Linear(15, 10),
nn.Sigmoid()
).to(device)print(model)#!pip install torchsummaryimport torchsummarytorchsummary.summary(model, (784, ))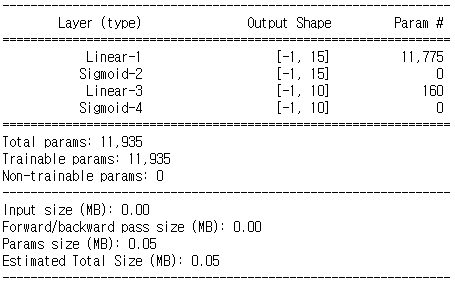
nn.module sub class
- init() 에서 Layers를 초기화 함.
- forward 함수를 구현
# (1, 28, 28)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(20, 50, kernel_size=3, padding=1)
self.fc1 = nn.Linear(4900, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4900)
x = F.relu(self.fc1(x))
x = F.log_softmax(self.fc2(x), dim=1)
return xmodel = Net()
model.to(device)torchsummary.summary(model, (1, 28, 28))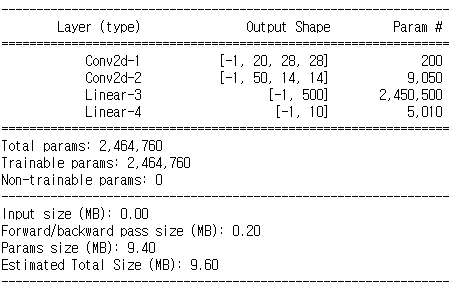
간단한 ResNet 구현
class ResidualBlock(nn.Module):
def __init__(self, in_channel, out_channel):
self.in_channel, self.out_channel = in_channel, out_channel
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channel, out_channel, kernel_size=1, padding=0)
if in_channel != out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out += self.shortcut(x)
return outclass ResNet(nn.Module):
def __init__(self, color = 'gray'):
super(ResNet, self).__init__()
if color == 'gray':
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
elif color == "rgb":
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.resblock1 = ResidualBlock(32, 64)
self.resblock2 = ResidualBlock(64, 64)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = self.resblock1(x)
x = self.resblock2(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return xmodel = ResNet()
model.to(device)print(model)torchsummary.summary(model, (1, 28, 28))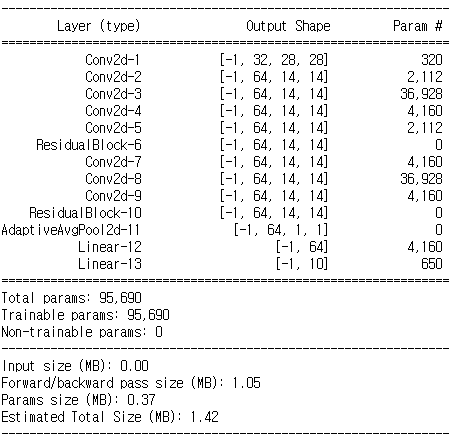
전체 딥러닝 플로우 구현 해보기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline데이터 Load 와 전처리
import torch
from torchvision import datasets,transformsbatch_size = 32train_loader = torch.utils.data.DataLoader(
datasets.MNIST('dataset/', download = True, train = True,
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std = (0.5, ))]
)),
batch_size = batch_size,
shuffle = True
)test_loader = torch.utils.data.DataLoader(
datasets.MNIST('dataset/', train = False,
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std = (0.5, ))]
)),
batch_size = batch_size,
shuffle = False
)데이터 확인
PyTorch에서는 TF와 이미지를 표현하는데 있어서 차이점이 있음.
- TF - (batch, height, width, channel)
- PyTorch - (batch, channel, height, width)
images, labels = next(iter(train_loader))images.shape, images.dtypeimages[1].shapetorch_image = torch.squeeze(images[1])image = torch_image.numpy()label = labels[1].numpy()plt.title(label)
plt.imshow(image)
plt.show()모델 정의
from torch import nn # 학습할 파라미터가 있는 것들
import torch.nn.functional as F # 학습할 파라미터가 없는 것들class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim = -1)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = Net().to(device)print(model)학습 로직
- PyTorch에서는 model을 Training 모드로 변경 후 Training 할 수 있다.
# epoch
# - batch
# - model
# - loss
# - gram
# - model update import torch.optim as optimopt = optim.SGD(model.parameters(), lr = 0.03)model.parameters()for epoch in range(1):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
opt.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target) # 예측, 정답
loss.backward()
opt.step()
print('batch {} loss : {}' .format(batch_idx, loss.item()))
model.eval()
test_loss = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target).item()
test_loss /= len(test_loader.dataset)
print('Epoch {} test loss : {}' .format(epoch, test_loss))
Training logic
import torch, gc
gc.collect()
torch.cuda.empty_cache()import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transformsdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')batch_size = 16
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('dataset/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])),
batch_size=batch_size,
shuffle=True)class ResidualBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(ResidualBlock, self).__init__()
self.in_channel, self.out_channel = in_channel, out_channel
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channel, out_channel, kernel_size=1, padding=0)
if in_channel != out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out = out + self.shortcut(x)
return out
class ResNet(nn.Module):
def __init__(self, color='gray'):
super(ResNet, self).__init__()
if color == "gray":
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
elif color == "rgb":
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.resblock1 = ResidualBlock(32, 64)
self.resblock2 = ResidualBlock(64, 64)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = self.resblock1(x)
x = self.resblock2(x)
x = self.avgpool(x)
x = torch.flatten(x,1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return xmodel = ResNet().to(device)Learning Rate Scheduler
optimizer = optim.Adam(model.parameters(), lr = 0.03)from torch.optim.lr_scheduler import ReduceLROnPlateauscheduler = ReduceLROnPlateau(optimizer, mode = 'min', verbose=True)def train_loop(dataloader, model, loss_fn, opimizer, scheduler, epoch):
model.train()
size = len(dataloader)
for batch, (x, y) in enumerate(dataloader):
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss = loss.item()
print(f'Epoch {epoch} : [{batch}/{size}] loss : {loss}')
scheduler.step(loss)
return loss.item()for epoch in range(3):
loss = train_loop(train_loader, model, F.nll_loss, optimizer, scheduler, epoch)
print(f'epoch : {epoch} loss : {loss}')weight만 저장
torch.save(model.state_dict(), 'model_wights.pth')model.load_state_dict(torch.load('model_wights.pth'))구조도 함께 저장
torch.save(model, 'model.pth')model = torch.load('model.pth')save, load, resuming training
checkpoint_path = 'checkpoint.pth'torch.save({
'epoch' : epoch,
'model_state_dict' : model.state_dict(),
'optimizer_state_dict' : optimizer.state_dict(),
'loss' : loss,
}, checkpoint_path)model = ResNet().to(device)
optimizer = optim.SGD(model.parameters(), lr = 0.03)checkpoint = torch.load(checkpoint_path)
checkpointcheckpoint.keys()model.load_state_dict(checkpoint['model_state_dict'])
epoch = checkpoint['epoch']
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
loss = checkpoint['loss']어렵다...
💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅