PDF를 중심으로 요약 및 정리해보았다.
1. Introduction
머신러닝을 이용한 정적 malware detection system인 Hidost를 소개한다. Hidost는 이전에 존재했던 연구들을 확장시켜 logical structure 파일인PDF, SWF에서 효과적으로 동작하게 설계되었다.
- 파일 문서에 malware를 심는 이유
- 일반 사용자들에게 실행 파일을 열게하는 것 보다, 문서 파일을 열게하는 것이 더 쉽다.
- 문서파일은 복잡한 구조로 인해 취약점이 발견되고 있다.
- 문서파일의 융통성을 이용하여 악성프로그램을 심기 용이하다.
2. Hierarchically structured file formats
계층 구조 파일의 예는 다음과 같다.
- SWF
- XML
- HTML
3. System design
여섯 개의 main stage로 system이 구성되어 있다.
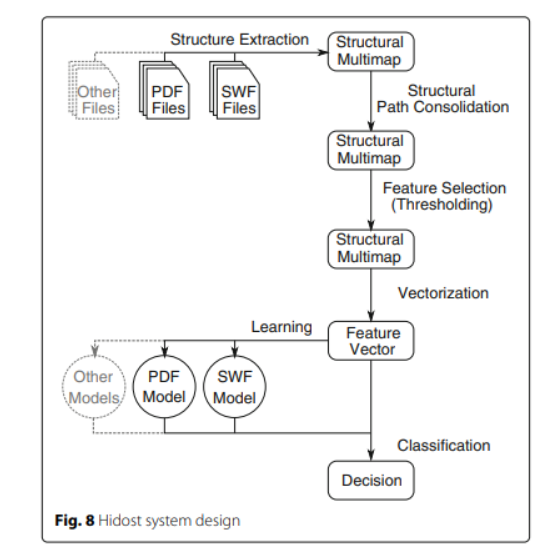
(1) Structure extraction : 일반적인 data structure로 변경
(2) Structural path consolidation : (1)의 결과물을 좀 더 일반적인 form으로 변환
(3) Feature selection : 중요한 feature 선정
(4) Vectorization transform : 학습을 위해 vectorization
(5) Learning : 학습
(6) Classification : 분류
3.1 File structure extraction
path와 그 값을 key와 value 형태로 변환

3.2 Structural path consolidation
File structure extraction의 결과물에서 중복 등 불필요한 Feature들을 일반화 시키기 위한 과정. 의미론적으로 동일한 path들을 통일시킨다.
EX)
/Pages/Kids/Resources => /Pages/Resources
/Pages/Kids/Kids/Resources => /Pages/Resources

3.3 Feature selection
모든 path들을 학습에 사용하는 것은 적합하지않다. PDF는 user-dfined name이 많기 때문이다. 이에 학습 파일 중 1000개 파일 이상에서 나타나는 path들만을 학습 Feature로 선정하였다.
3.4 Vectorization
machin learning으로 학습시키기 위하여 Feature 들을 vectorization 한다. 이에 사용되는 수식은 다음과 같다.
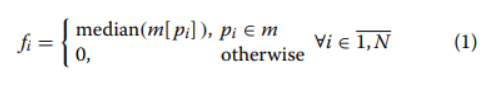
위의 수식을 적용시킨 Feature들의 값은 아래 보이는 그림과같이 나타난다.

3.5 Learning and classification
decision tree를 사용한 앙상블 방식인 Random forest 모델을 이용하여 학습 및 분류
4. Experimental evaluation
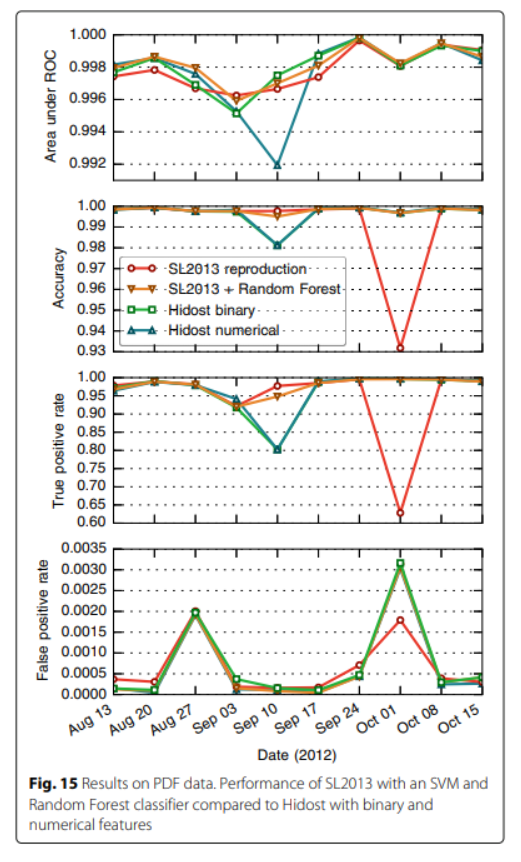
binary와 numerical의 차이점은 binary는 path의 존재 유무에 따라 binary로 feature들을 나타내고, numerical은 위에서 언급한 vectorization 방식을 이용한 것으로 보여진다.
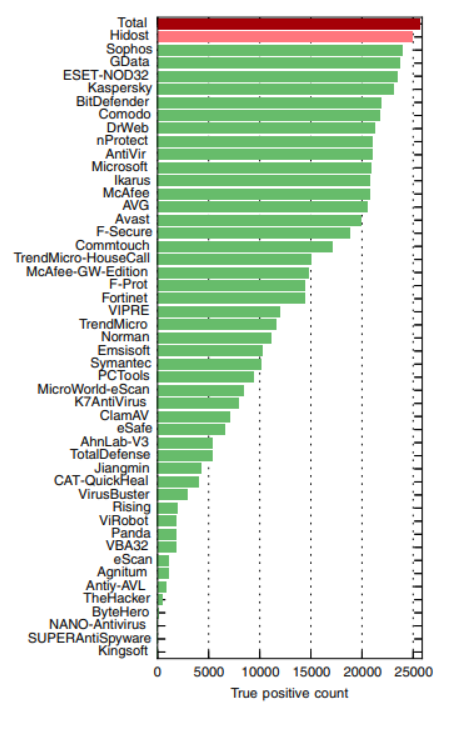
Hidost의 결과는 virustotal에서 우수한 성적을 기록했다.
Reference
-
Hidost: a static machine-learning-based detector of malicious files
저자 : Nedim Srndic, Pavel Laskov
