1. Introduction
생략
2. Structure of PDF files
생략
3. Techniques and possible attacks via PDF files
3.1 JavaScript code attack
PDF 파일에 악성 JavaScript code를 난독화하여 공격하는 경우가 많음.
3.2 Embedded files attack
Embedded : 하드웨어나 소프트웨어가 다른 하드웨어, 소프트웨어의 일부로 내재되어있는 것.
4. Advanced methods for detection of malicious PDF files
-
static analysis
- 파일 또는 어플리케이션을 실행시키지않고 단지 코드만으로 조사, 평가하는 방법
- 특징
- 컴퓨터 자원이 적게 든다.
- 일반적으로 embedded JavaScript code 또는 metadata를 분석한다.
- runtime 도중 실행되는 악의적인 well-obfuscated code에 약하다는 단점이 있다.
-
dynamic analysis
- JavaScript를 분석하는 방법으로, JavaScript 추출 방식에 따라 두 가지로 나뉜다.
- Static JavaScript Extraction : PDF안의 JavaScript code를 실행시키지않고 추출하는 방법.
- Dynamic JavaScript Extraction : PDF안의 JavaScript codefmf 실행시켜 추출하는 방법.
- 특징
- static analysis와 반대되는 특징을 가진다.
- JavaScript를 분석하는 방법으로, JavaScript 추출 방식에 따라 두 가지로 나뉜다.
4.1 Detection methods based on static analysis
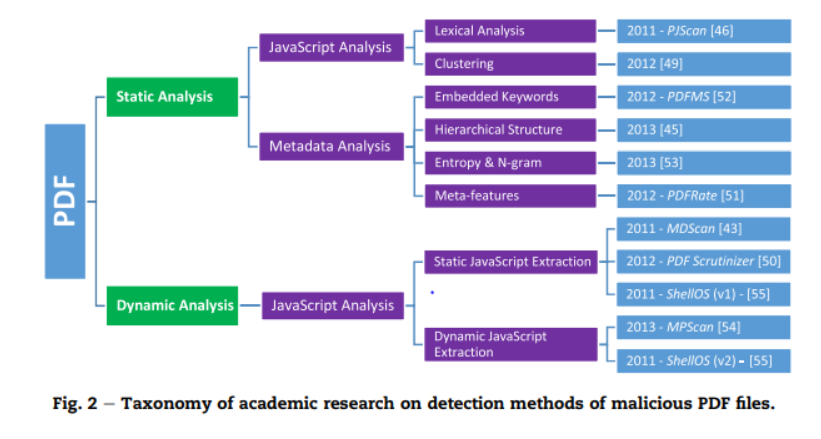
4.1.1 JavaScript analysis
machine learning algorithm을 적용시키기 위해 JavaScript code를 토큰화 시킨다. 토큰화된 JavaScript에는 사용된 변수 타입, 함수 이름, operator 등이 있다.
4.1.1.1 Lexical analysis
PJScan으로 불림
POPPLER 라이브러리를 사용하여 JavaScript code를 찾고, feature extraction을 진행한다. 그 후, JavaScript interpreter인 Mozilla SpiderMonkey를 사용하여 lexical analysis를 진행한다. Lexical analysis는 JavaScript code를 토큰의 연속물로 표현하여 classification을 진행한다. PJScan은 TPR 85%, FPR 16-17%의 performance를 보여주었다.
4.1.1.2 Clustering
다양한 obfuscattion techniques를 사용하여 난독화된 비슷한 script들을 식별하는 방법이다. 식별한다는 것의 의미가 잘 이해가 되지 않는다...malware들은 비슷한 특징을 띌것이니 함께 클러스터링 될 것이다, 이런 개념인가?
tokenization하는 방식에 따라 두 가지로 나뉘게 된다.
- hierarchical bottom up clustering
- hash table clustering
위의 방법을 적용해본 결과, 악성 PDF의 93%는 JavaScript를 포함하였고 정상 PDF는 5%만이 JavaScript를 포함하였다. 또한 hash table clustering 방법이 large data set에서는 더 효율적이었다.
4.1.2 Metadata analysis
4.1.2.1 Keywords analysis
특정 PDF 파일을 embedded keywords와 그들의 나타남을 통하여 집합으로 묶는 방법. Naive Bayes, SVM, Decision tree 등의 머신러닝 기법을 사용
4.1.2.2 Hierarchical structure analysis
path 등을 이용하는 것으로 생각됨. Hidost가 여기에 포함되지 않을까?
4.1.2.3 Content metadata analysis
Hierarchical structure을 머신러닝 알고리즘에 사용될 수 있도록 표현된 feature들의 리스트로 바꾼는 것.
4.1.2.4 Term frequency and entropy analysis
앞서 언급했던 방식들은 embedded objects에서 적절한 데이터를 추출하기 위해 PDF parser를 사용하였는데 지금 소개할 두 가지 방식들은 PDF parser를 사용하지 않는다.
- entropy based method
- entropy는 주어진 데이터의 불확실성과 무작위성의 수치를 나타냄.
- 이 방법을 고안한 사람은 악성 파일일수록 불확실성이 작을 것이라고 생각.
- 다른 feature들과 결합하여 사용하면 유용하다.
- 실제로 malicious dataset의 average entropy가 benign에 비해 유의미하게 작았다.
- n-gram based approach
- 이 방법을 고안한 저자는 PDF 파일의 hexadecimal dumps에서 2-grams를 발생시켰다. 그리고 2-grams은 TF, TFIDF로 표현되었다. J48 알고리즘이 TF, TFIDF를 통해 모델을 생성하는데 사용되었다.
4,2 Detection methods based on dynamic analysis
생략
4.3 Advanced methods and coping with exiting attacks
앞서 언급한 static, dynamic analysis는 장점과 단점이 있다. 이를 결합한 hybrid detection framwork는 악성 PDF 파일을 놓칠 가능성을 줄여줄 것이다.
의심스러운 PDF파일을 재귀적으로 세 가지 analyses를 진행해보는 방법을 고안한 학자(Maiorca et al., 2013)가 존재한다. 그는 embedded JavaScript code analysis, PDF structural analysis, analysis of the embedded EXE or SWF 파일 방식을 세 가지 방법으로 선정하였다.
5. Dataset collection and preliminary
생략
6. Our suggested active learning based framework
이 논문에서는 기본적으로 machine learning 접근방식을 채택했다. 기존의 detection model의 문제점은 새로운 악성 PDF 파일에 대해 학습하고, 통합할 수 없다는 것이다. detection model은 반드시 지속가능해야하고 새로운 파일들에 대해 업데이트 되어야 한다.
이 논문은 detection model의 능력 향상에 가장 기대가 되는 중요한 새로운 PDF파일에 대해 우선순위를 매겨 전문가에게 보내 수동 분석을 하기 위한 active learning method를 제안한다.
이 모델은 detection model의 수정능력 유지를 통해 새로운 악성 PDF파일들을 찾고, 익숙해질 것이다.
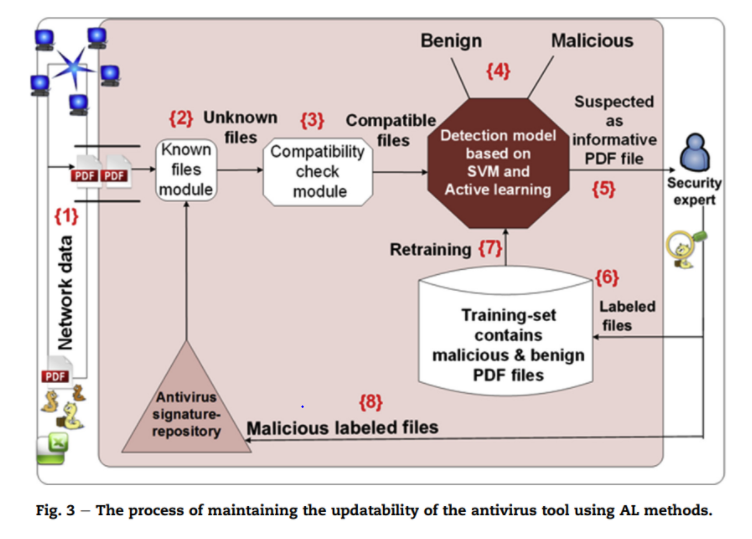
{1} 데이터가 입력
{2} repository를 통해 이미 학습된 파일인지 확인
{3} 학습된 파일이 아니라면 호환성을 확인
{4} detection model 가동
{5} 중요한 파일이라고 생각되면 전문가가 classification
{6} 라벨링된 데이터를 training set에 넣고 repository에 저장함
{7} 새로운 training set으로 모델 업데이트
Reference
-
Detection of malicious PDF files and directions for enhancements: A state-of-the art survey
저자 : Nir Nissim, Aviad Cohen, Chanan Glezer, Yuval Elovici
