학습내용
Keras validation set
sklearn의 train_test_split 대신, 케라스에는 validation_data라는 편리한 기능이 있다.
모델을 학습할 때 validation_data에 테스트 데이터를 입력하면 케라스에서 자동으로 테스트셋의 일정 부분을 검증용 데이터로 사용.
model.fit(X_train, y_train, validation_data=(X_test, y_test))하이퍼파라미터 튜닝
용어 정리
- 파라미터 : 모델 및 데이터의 특성을 나타내는 것(ex. 정규분포의 평균)
- 하이퍼 파라미터 : 모델 학습 시 사용자가 조정할 수 있는 값(ex. ANN의 learning_rate)
하이퍼파라미터 튜닝
- grid search
- random search
- bayesian methods : 이전 탐색 결과를 반영해서 이후의 하이퍼 파라미터 튜닝의 성능을 높이는 전략, keras-tuner를 쓰면 간단하게 구현가능
튜닝 가능한 파라미터 옵션
- batch size
- training epochs
- optimization algorithms
- learning rate
- momentum
- activation functinos
- dropout regularization
- hidden layer의 neuron 수
keras에서 GridSearchCV 사용하기
keras.wrapper를 활용
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
import keras
import tensorflow as tf
import IPython
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import GridSearchCV
def create_model():
# 모델 제작
model = Sequential()
model.add(Dense(100, input_dim=8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일링
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# keras.wrapper를 활용하여 분류기를 만듭니다
model = KerasClassifier(build_fn=create_model, verbose=0)
# GridSearch
batch_size = [10, 20, 40, 60, 80, 100]
epochs = [30]
param_grid = dict(batch_size=batch_size)
# GridSearch CV를 만듭니다
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=1)
grid_result = grid.fit(X, Y)
# 최적의 결과값을 낸 파라미터를 출력합니다
print(f"Best: {grid_result.best_score_} using {grid_result.best_params_}")
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print(f"Means: {mean}, Stdev: {stdev} with: {param}")Keras Tuner 사용
tuner에는 RandomSearch, Hyperband, BayesianOptimization이 있다.
각 tuner의 특징 꼭 알아보기!
# 모델 만들기
def model_builder(hp):
model = Sequential()
# Dense layer에서 노드 수를 조정(32-512)
hp_units = hp.Int('units', min_value = 32, max_value = 512, step = 32)
model.add(Dense(units = hp_units, activation='relu'))
model.add(Dense(units = hp_units, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 이진분류니까 노드수 1, 활성함수로는 시그모이드
# Optimizer의 학습률(learning rate)을 조정[0.01, 0.001, 0.0001]합니다.
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
# 컴파일 단계, 옵티마이저와 손실함수, 측정지표를 연결해서 계산 그래프를 구성함
model.compile(optimizer=keras.optimizers.Adam(learning_rate = hp_learning_rate),
loss=keras.losses.BinaryCrossentropy(from_logits = True), #from_logits = True : y_pred가 logit의 형태인지 결정,
metrics=['accuracy'])
return model# 튜너를 인스턴스화하고 하이퍼 튜닝을 수행
tuner = kt.Hyperband(model_builder,
objective = 'val_accuracy',
max_epochs = 30, #early stopping 시켜줌
factor = 3,
directory = 'my_dir',
project_name = 'intro_to_kt')# callback 정의 : 하이퍼 파라미터 검색을 실행하기 전에 모든 교육 단계가 끝날 때마다 교육 출력을 지우도록 콜백을 정의합니다.
class ClearTrainingOutput(tf.keras.callbacks.Callback):
def on_train_end(*args, **kwargs):
# *args : 파라미터를 몇개 받을지 모르는 경우 사용, 튜플형태로 전달됨
# **kwargs : 파라미터 명을 같이 보낼 수 있음, 딕셔너리 형태로 전달
IPython.display.clear_output(wait = True)tuner.search(X_train_scaled, y_train, epochs = 30, batch_size=50, validation_data = (X_test_scaled,y_test), callbacks = [ClearTrainingOutput()])
# Get the optimal hyperparameters
best_hps = tuner.get_best_hyperparameters(num_trials = 1)[0]
print(f"""
최적화된 Dense 노드 수 : {best_hps.get('units')}
최적화된 Learning Rate : {best_hps.get('learning_rate')}
""")Batch
batch 정규화
미니배치의 평균과 분산을 이용해서 정규화 한 뒤에, scale 및 shift 를 감마(γ) 값, 베타(β) 값을 통해 실행

batch 정규화를 거치면 보통 모델의 성능이 더 좋아진다고 알려져있다. 최근에는 성능과 관련이 없다는 연구결과가 있기도 하다. 그래도 아직까지는 batch 정규화를 많이 사용하는 추세이다.
batch size를 보통 2의 제곱수로 사용함. 왜?
GPU의 physical processors가 2의 제곱개인 경우가 많다. 여기서 GPU의 virtual processors를 통해 병렬적으로 모델학습을 진행 시에, physical processors에 맞지않은 수를 사용하게 되면 performance가 떨어지는 경향이 있기 때문이다.
Initialize
Network Weight Initialization
Xavier normal : activation function이 sigmoid, tanh일때 효과적
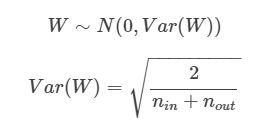
He normal : activation funcion이 relu일때 효과적
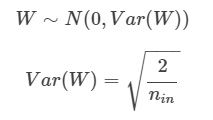
relu는 0이하의 값들은 다 0으로 만들어버리기때문에 표준편차가 더 적은 normal로 변환시키는 He가 좀 더 적합한 것으로 생각됨.
