
20210927
1. 머신러닝 알고리즘
머신 러닝의 알고리즘은 크게 3 종류로 나눌 수 있다.
지도학습,비지도학습,강화학습
-
라벨(정답)의 존재 유무에 따라 머신러닝을 지도학습과 비지도학습으로 나눠진다. -
정답 유무,데이터의 종류,특성,문제 정의에 따라 머신러닝 알고리즘은 복합적으로 사용 -
알고리즘은 상황에 따라 변경하거나 중복하여 사용할 수 있다.
지도학습 (Supervised Learning)
- 대표적인 알고리즘
분류(Classification): 예측해야할 데이터가 범주형(categorical) 변수일때회귀(Regression): 예측해야할 데이터가 연속적인 값 일때예측(Forecasting): 과거 및 현재 데이터를 기반으로 미래를 예측하는 과정
비지도학습 (Unsupervised Learning)
- 대표적인 알고리즘
클러스터링: 특정 기준에 따라 유사한 데이터끼리 그룹화함차원축소: 고려해야할 변수를 줄이는 작업, 변수와 대상간 진정한 관계를 도출하기 용이
강화학습 (Reinforcement Learning)
환경을 관찰해서 에이전트가 스스로 행동하게 한다.
모델은 그 결과로보상을 받고, 이 보상을 최대화 하도록 학습한다.
에이전트(Agent): 학습 주체 (혹은 actor, controller)
환경(Environment): 에이전트에게 주어진 환경, 상황, 조건
행동(Action): 환경으로부터 주어진 정보를 바탕으로 에이전트가 판단한 행동
보상(Reward): 행동에 대한 보상을 머신러닝 엔지니어가 설계
강화학습 알고리즘: Monte Carlo methods, Q-Learning, Policy Gradient methods
2. Scikit-Learn
파이썬 기반 머신러닝 라이브러리.
- 사이킷런의 알고리즘 Task:
Classification,Regression,Clustering,Dimensionality Reduction
- 사이킷런 알고리즘 구분 기준
- 데이터 수량
- 라벨의 유무(정답의 유무, 라벨 = 레이블 = 정답)
- 데이터의 종류 (수치형 데이터(quantity), 범주형 데이터(category) 등)
Classification용 알고리즘- SGD Classifier
- KNeighborsClassifier
- LinearSVC
- NaiveBayes
- SVC
- Kernel approximation
- EnsembleClassifiers
Regression용 알고리즘- SGD Regressor
- Lasso, ElasticNet
- RidgeRegression
- SVR(kernel='linear')
- SVR(kernel='rbf')
- EnsembelRegressor
# 사이킷런 설치
!pip install scikit-learn
#!conda install scikit-learn
# import
import sklearntrain_test_split : Scikit-Learn에서 훈련 데이터와 테스트 데이터를 나누는 기능을 제공하는 함수
transformer(): ETL(Extract Transform Load) 기능을 수행하는 함수
Estimator: 모델(Model)로 표현되는 클래스
(메소드 fit(), predict()가 있다)
Pipeline, meta-estimator: Estimator와 transformer() 2가지 기능을 수행하는 scikit-learn의 API
훈련과 예측이 끝나면 이 2가지 작업을 Pipeline으로 묶어 검증을 수행
3. 사이킷런 주요 모듈 - 데이터 표현법
데이터셋은 NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 이용해 나타낼 수 있다.
-
CoreAPI:
fit(),transfomer(),predict()(훈련, 예측 등 머신 러닝 모델을 다룰 때 사용) -
사이킷런에서는 데이터 표현 방식:
특성행렬(Feature Matrix),타겟벡터(Target Vector)

주로 사용하는 API (출처: AIFFEL FUNDAMENTAL_SSAC2 11. 사이킷런으로 구현해보는 머신러닝)
특성 행렬(Feature Matrix)
입력 데이터를 의미
-
특성(feature): 데이터에서 수치 값, 이산 값, 불리언 값으로 표현되는 개별 관측치를 의미.
특성 행렬에서는 열에 해당하는 값 -
표본(sample): 입력 데이터, 특성 행렬의 행에 해당하는 값 -
n_samples: 행의 개수(표본의 개수) -
n_features: 열의 개수(특성의 개수) -
X: 통상 특성 행렬은 변수명 X로 표기 -
[n_samples, n_features]은[행, 열]형태의 2차원 배열 구조를 사용- 이는 NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 사용하여 나타낼 수 있다.
타겟 벡터 (Target Vector)
입력 데이터의 라벨(정답) 을 의미
-
표(Target): 라벨, 타겟값, 목표값이라고도 부르며 특성 행렬(Feature Matrix)로부터 예측하고자 하는 것 -
n_samples: 벡터의 길이(라벨의 개수) -
타겟 벡터에서
n_features는 없다. -
y: 통상 타겟 벡터는 변수명 y로 표기 -
타겟 벡터는 보통
1차원 벡터로 나타냄-
이는 NumPy의 ndarray, Pandas의 Series를 사용하여 나타낼 수 있다.
-
타겟 벡터는 경우에 따라 1차원으로 나타내지 않을 수도 있다.
-
특성행렬 X의 n_samples와 타겟벡터 y의 n_samples는 동일해야 한다.
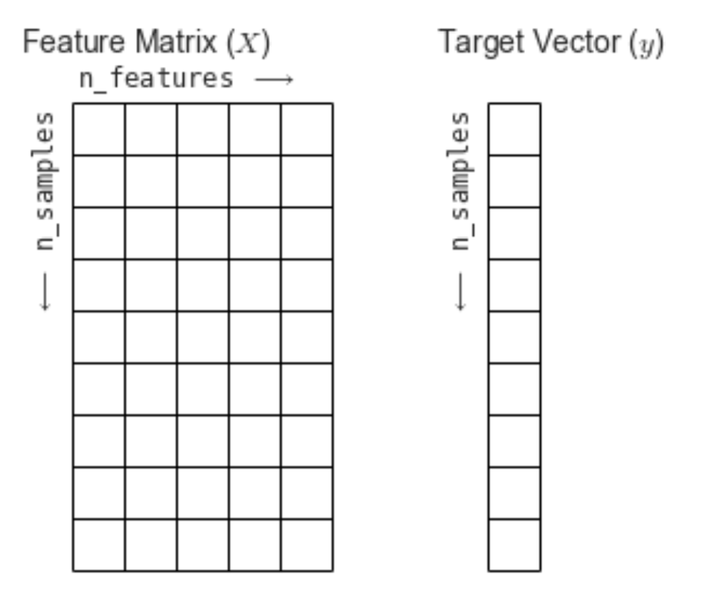
[출처: https://jakevdp.github.io/PythonDataScienceHandbook/06.00-figure-code.html#Features-and-Labels-Grid]
4. 모델 실습
사이킷런 머신러닝 모델을 사용을 위해 모델 객체를 생성
회귀 모델
-
LinearRegression: 회귀 모델
(Estimator객체) -
fit(): 훈련 메소드. 인자로 특성 행렬, 타겟 벡터를 받음 -
Reshape()를 통해 ndarray 타입 입력값을 행렬록 변환하기
(나머지 숫자를 -1로 넣으면 자동으로 남은 숫자를 계산) -
rand(): 0 이상 1 미만의 실수인 난수를 반환 -
linspace(start, stop, num): start를 배열의 시작값, stop을 배열의 끝값으로 하여 start와 stop 사이를 num개의 일정한 간격으로 1차원 배열로 반환 -
성능 평가 관련 모듈은
sklearn.metrics에 저장 -
회귀 모델의 경우 성능 평가에
RMSE(Root Mean Square Error)를 사용 -
RMSE가 낮을수록 정확도가 높다고 판단 -
mean_squared_error
# 행렬 변환
X = x.reshape(100,1)
## RMSE 구하기
from sklearn.metrics import mean_squared_error
RMSE = mean_squared_error(y, y_pred)**0.5
분류
RandomForestClassifier: 분류 모델
(Estimator 객체)
sklearn.metrics로 성능 평가를 한다
(분류 문제는classification_report, accuracy_score 사용)
# 성능 평가를 위한 모듈 import
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
print(classification_report(라벨y, 예측값y))
# 정확도 확인
print("accuracy = ", accuracy_score(라벨y, 예측값y))
5. datasets 모듈
sklearn.datasets모듈: dataset loaders, dataset fetchers
(각각 Toy dataset, Real World dataset 제공)
-
sklearn.utils.Bunch-
빌트인 (Built-in) 데이터셋의 자료구조.
-
key-value형식으로 구성,사전(dict)형타입과 유사한 구조 -
keys()메소드 사용 가능 -
.을 사용해 키에 접근
-
DESCR(describe): 데이터에 대한 설명
6. Estimator
Estimator 객체: 데이터셋을 기반으로 하여 머신러닝 모델의 파라미터를 추정
Estimator 객체 사용 시 비지도학습, 지도학습에 관계 없이 학습과 예측 가능
비지도 학습은 정답데이터가 없기 때문에 훈련 Target Vector가 인자(fit 메소드)로 들어가지 않음
7. 데이터 분리
훈련에 쓰이는 데이터와 예측에 쓰이는 데이터를 구분하여 사용하여야 한다.
일반적으로 train: test = 8:2 비율로 많이 설정한다고 한다.
슬라이싱
- 직접 훈련 데이터와 테스트 데이터를 분리할 때는 슬라이싱을 이용할 수 있다.
(데이터가 ndarray type일 때)
# 훈련 데이터와 테스트 데이터 분리하기
X_train = data.data[:원하는 슬라이싱 기준치]
X_test = data.data[원하는 슬라이싱 기준치:]
print(X_train.shape, X_test.shape)
y_train = data.data[:원하는 슬라이싱 기준치]
y_test = data.data[원하는 슬라이싱 기준치:]
print(y_train.shape, y_test.shap
# 훈련하기
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 예측하기
y_pred = model.predict(X_test)
train_test_split()
# train_test_split 사용을 위한 모듈 import
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=원하는 비율, random_state=seed번호)
추가학습 링크
Scikit-learn: Choosing the right estimator
np.random.RandomState(seed)를 이용해서 난수를 생성합시다.
Scikit-learn: Mean Squared Error
