
쉬운 코드님의 강의 내용을 정리한 글입니다.
강의가 궁금하시다면, 최하단의 링크를 참고해주세요.
오늘 작성한 글은MySQL기준으로 작성한 점 참고 부탁드립니다.
개요
우리가 아래 쿼리문을 실행한다고 가정해보자.
-- customer 테이블의 컬럼은 id(PK), last_name, first_name, address, birth_date 가 있다고 가정
SELECT *
FROM customer
WHERE first_name = 'Minsoo'
;만약 first_name에 index가 걸려있지 않다면, full scan(=table scan)으로 찾아야한다.
이 때, N개의 데이터가 존재한다면, 시간 복잡도는 O(N) 이 된다.
하지만 만약 first_name에 index가 걸려 있다면, full scan 보다 더 빨리 찾을 수 있다.
(index가 B-tree 기반의 인덱스라면 O(logN)의 시간 복잡도를 가진다.
Index를 사용하는 이유
- 인덱스를 사용하여 조건을 만족하는 튜플(들)을 빠르게 조회할 수 있다.
- 인덱스를 사용하여 빠르게 정렬(
order by)하거나 그룹핑(group by) 할 수 있다.
인덱스 생성
2개 이상의 컬럼을 이용하는 인덱스를
multicolumn index또는composite index라고 한다.
대부분의 RDBMS에서는 테이블을 생성할 때,primary key에 대한 인덱스가 자동으로 생성 된다.
1. 이미 있는 테이블에 대한 인덱스를 생성하는 방법
-- 중복이 가능한 경우 그냥 INDEX 명령어 사용
CREATE INDEX 인덱스명 ON 테이블명 (어트리뷰트명);
CREATE INDEX player_name_idx ON player (name);
-- 2개의 어트리뷰트로 유니크한 index를 만드는 경우
CREATE UNIQUE INDEX team_id_backnumber_idx ON player (team_id, backnumber);
2. 테이블을 생성할 때 인덱스를 거는 방법
CREATE TABLE player (
id int primary key,
name varchar(20) not null,
team_id int,
backnumber int,
INDEX player_name_idx (name),
UNIQUE INDEX team_id_backnumber_idx (team_id, backnumber)
);생성한 인덱스는 아래 SQL문으로 확인 가능하다.
SHOW INDEX FROM 테이블명;
SHOW INDEX FROM player;위 명령어를 실행하면 아래와 같은 결과를 얻을 수 있다.
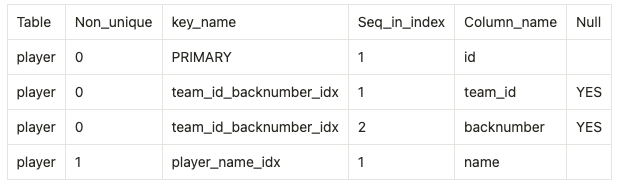
key_name 은 index Name을 의미한다.
이 때, 동일한 key_name을 가지고 seq_in_index 가 여러개면 multicolumn index인 것이다.
애트리뷰트가 궁금하면 column_name을 확인하면 되고, 해당 애트리뷰트가 null을 허용하는지도 확인 할수도 있다.
B-tree 기반 인덱스
B-tree 기반 인덱스는 데이터를 정렬해서 가지고 있다. 그리고 실제 테이블에 있는 튜플을 가리키는 데이터인 ptr (pointer)를 가지고 있다.
B-tree 기반 인덱스는 먼저 binary search를 이용해서 데이터를 찾고, 해당하는 데이터들의 ptr을 확인한다.
그런데 만약 조건이 2개이고, 두 조건 중 하나에만 인덱스가 걸려있다면, 결국 풀스캔을 해야해서 비효율적일 수 있다.
그리고 B-tree 기반 인덱스는 작성한 컬럼들을 순차적으로 정렬하기 때문에, 멀티 컬럼 인덱스를 생성할 때 애트리뷰트 순서가 매우 중요하다.
예제를 통해 이해하기
Player 테이블에 id, name, team_id, backnumber 컬럼이 존재한다고 가정한다.
그리고 id, name, team_id & backnumber 이렇게 3개의 index가 존재한다고 가정한다.
이 경우 아래 SQL문을 실행하면 인덱스를 이용해서 빠르게 데이터를 조회할 수 있을 것이다.
SELECT * FROM player WHERE team_id = 110;
SELECT * FROM player WHERE team_id = 110 AND backnumber = 7;하지만 아래의 경우 어떨까?
-- 아래 쿼리는 인덱스를 사용하지 않거나, 성능이 매우 안 좋을 것이다.
SELECT * FROM player WHERE backnumber = 7;
-- or로 연결되어 있기 때문에 backnumber 에 대해서는 index없이 풀스캔을 사용한다.
SELECT * FROM player WHERE team_id = 110 OR backnumber = 7;
위 예시들의 성능을 개선하기 위해서는 backnumber에 대한 index를 만들어줘야 할 것 이다.
이 예제에서 알 수 있는 것은 무조건 인덱스를 사용하는 것이 아니라, 사용되는 쿼리를 정확하게 이해하고 적절하게 index를 걸어줘야 쿼리를 빠르게 수행할 수 있다는 것이다.
index의 적용
만약 실행할 쿼리가 어떤 인덱스를 사용하는지 궁금하다면 아래처럼 EXPLAIN을 이용할 수 있다.
EXPLAIN 실행할 쿼리문;
EXPLAIN SELECT * FROM player WHERE backnumber = 7;
그런데 어떤 인덱스를 사용할지 명시해주지 않았는데 어떻게 인덱스를 선택해서 적용했을까?
우리가 사용하는 RDBMS의 optimizer가 적절한 index를 선택해준다. 하지만 직접 index를 고르고 싶다면 아래처럼 명시해줄 수 있다.
-- 권장
-- 이 쿼리문에서 사용하면 좋을 idx를 적는 것 (안 적으면 풀스캔으로 작동)
SELECT * FROM player
USE INDEX (backnumber_idx)
WHERE backnumber = 7;
-- 강제
-- 옵티마이저가 판단했을 때, 해당 인덱스를 사용해서 데이터를 가져올 수 없다면 풀스캔하지만
-- 그게 아니라면 해당 인덱스를 사용함
SELECT * FROM player
FORCE INDEX (backnumber_idx)
WHERE backnumber = 7;
-- index를 사용하고 싶지 않다면 IGNORE INDEX 키워드 사용
SELECT * FROM player
IGNORE INDEX (backnumber_idx)
WHERE backnumber = 7;인덱스는 만들수록 좋다?
그렇다면 인덱스는 많이 만들수록 좋을까? 인덱스를 생성할 때 아래 사항들을 고려해보고, 불필요한 인덱스를 만들지 않아야 한다.
-
인덱스를 생성할 때마다 부가적인 데이터도 생성된다.
-
테이블에 write할 때마다 index에도 변경이 발생한다.
- 관련 인덱스에 데이터를 모두 추가해야 하고, B-tree 구조도 조정해야하기 때문에 시간이 소요된다.
- 인덱스가 많아질수록, 데이터의 write가 발생할수록 오버헤드가 발생할 가능성이 높다.
-
추가적인 저장공간을 차지한다.
그 외 알면 좋을 정보
커버링 인덱스(Covering index)
인덱스 안에 있는 정보만이 필요하다면, 쿼리문을 커버하는 것이 가능하다.
실제 테이블에도 가지 않아도 되기 때문에 속도가 더 빠르다.
-
조회하는 attribute(s)를 index가 모두 cover할 때, 커버링 인덱스라고 한다.
-
조회 성능이 더 빠르다.
Hash index
hash table을 사용해서 구현한 인덱스이다.
- 시간 복잡도 O(1)의 성능을 가진다.
- rehashing에 대한 부담이 있다(데이터 변동에 따른 사이즈 조정 부담).
- equality 비교만 가능하며, range 비교가 불가능하다(같거나 작을 때 등에 대한 비교가 불가능).
- multicolumn index의 경우 전체 attributes에 대한 조회만 가능하다.
Full scan이 더 좋은 경우
- table에 데이터가 조금 있을 때 (몇 십, 몇 백건 정도 일 때)
- 데이터가 많은 상태에서 풀스캔이 좋은 경우 → 조회하려는 데이터가 테이블의 상당 부분을 차지할 때
그 외
- order by, group by 에도 index 가 사용될 수 있다.
- foreign key에는 index가 자동으로 생성되지 않을 수 있다 (join 관련 성능 영향이 있을 수 있음)
- mysql은 자동생성해주지만, 다른 RDBMS에서는 아닐 수 있으니 주의
- 이미 데이터가 몇 백만건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 몇분 이상 소요될 수 있고, DB 성능에 안 좋은 영향을 줄 수 있다.
- 인덱스가 생성되는 동안 write 가 발생하면 안좋은 영향을 줄 수 있기 때문에, 이를 고려해야 한다.
참고 자료
