.png)
NLP란?
자연어 처리(自然語處理)는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다.
...
구현을 위해 수학적 통계적 도구를 많이 활용하며 특히 기계학습 도구를 많이 사용하는 대표적인 분야이다.
-위키백과-
- 인간의 언어 데이터를 기계가 학습
- 언어를 이용한 인간의 판단, 행위 등을 기계가 가능하도록 하는 것
- 크게 NLU(Natural Language Understanding)과 NLG(Natural Language Generation)으로 구분할 수 있으며 이들 또한 세부 분야로 구성됨
해당 게시물에서는
NLU의 한 분야인 Semantic Textual Similarity(STS)와
NLG의 한 분야인 Dialogue Generation에 대해 다루고자 한다.
📌Semantic Textual Similarity(STS)
Semantic textual similarity deals with determining how similar two pieces of texts are.
This can take the form of assigning a score from 1 to 5. Related tasks are paraphrase or duplicate identification.
-papers with code-
🧐문제정의
STS가 해결하고자 하는 문제는 무엇일까?
이름에서 알 수 있듯이, 주어진 두 텍스트에 대해 얼마나 비슷한지를 수치적으로 나타내는 것이 주 목적이다.
방식은 두 가지 정도로 구분지을 수 있는데,
- 두 텍스트에 대한 label은 0(dissimilar)부터 5(similar)까지의 수로 표현되어 있고 학습시킨 모델에 두 텍스트를 넣으면 0부터 5 사이의 숫자로 유사성을 판단한다. (회귀)
- 두 텍스트가 유사한지 아닌지를 0 또는 1로 구분한다. (분류)
등으로 볼 수 있다.
정리하면 Semantic Textual Similarity, 즉 의미론적 유사도 측정은 두 텍스트 간 유사성의 정도를 측정하는 task이다.
그러면 STS를 가지고 비즈니스적으로 어떤 문제를 해결할 수 있는지에 대해 생각해보자.
1) 고객의 문의 대응
- 고객의 문의 사항은 다양하지만 기업 입장에서 유사한 문의에 대해 비슷한 대처를 해야하는 경우 존재
- 훈련된 모델에 새로운 고객의 문의를 입력하여 가장 유사한 문의와 매칭
👉 해당 메뉴얼을 참고 하여 고객에게 알맞는 응대 가능 - 기업 입장에선 업무 효율 증대와 애매한 문의에 대한 대응 레퍼런스를 쉽게 체크 가능
2) 고객 리뷰 분석
- 감성 분석과 같이 주어진 label이 아닌 새로운 insight를 도출하고자 할 때
- 고객의 리뷰를 각 유사도를 기반으로 하여 군집화
👉각 군집의 특성을 파악하며 또 다른 insight 도출 - 기업 입장에선 새로운 인사이트 도출이 가능
💾데이터 소개: STS-B
STS에 사용되는 가장 대표적인 데이터셋은 Sementic Textual Similarity Benchmark(STS-B)이다.
STS-B는 다음과 같은 특징을 가지고 있다.
- 영어로 구성
- 2012년과 2017년 사이 SemEval의 문맥으로 구성
- 이미지 캡션, 뉴스 헤드라인, 사용자 포럼의 텍스트가 포함되어있음
- 8628개의 문장 쌍으로 구성되어 있으며, train - dev - test 세트로 구성
각 장르와 train - dev - test는 다음과 같은 비율로 분배되어있다.
| train | dev | test | total | |
|---|---|---|---|---|
| news | 3299 | 500 | 500 | 4299 |
| caption | 2000 | 625 | 625 | 3250 |
| forum | 450 | 375 | 254 | 1079 |
| total | 5749 | 1500 | 1379 | 8628 |
🏆SOTA 모델 소개: SMART-RoBERTa Large
배경
- pre-trained 모델을 fine-tuning하는 것은 때때로 fine-tuning에 사용된 데이터에 강하게 적합되고 있음
원인1) pre-trained 모델의 용량이 너무 큼
원인2) fine-tuning 시 사용되는 데이터의 리소스가 제한됨
메인 아이디어
1) 모델의 용량을 효과적으로 관리하는 Smoothness-including regularization
2) pre-trained 정보의 망각을 방지하기 위한 Bregman proximal point optimization
📌Dialogue Generation
Dialogue Generation is a fundamental component for real-world virtual assistants such as Siri and Alexa. It is the text generation task that automatically generate a response given a post by the user.
-papers with code-
🧐문제정의
- Dialogue generation은 주어진 텍스트에 대한 응답을 자동으로 생성하는 task
- 이미 세계적으로 챗봇 서비스는 상용화되어있고, 이를 구현하기 위한 task
결론적으로, Dialogue generation는 사용자들의 대화를 학습하여 상대의 말에 적절한 대답을 생성하는 것이 최종적인 목표이자 해결하고자 하는 문제이다.
💾데이터 소개: persona-chat
Dialogue generation에 사용되는 대표적인 데이터셋은 persona-chat이다.
persona-chat은 다음과 같은 특징을 가지고 있다.
- 페르소나: 최소 5개의 프로필 문장으로 구성
📍 train : validation : test = 1155 : 100 : 100 - 두 명의 대화 참여자에게 페르소나를 할당 후 채팅
📍 10907번의 대화, 162064개의 발언 생성
📍 총 발언의 15602개는 validation, 15024개가 test 세트로 지정
🏆SOTA 모델 소개: P^2 Bot
Bot은 앞서 언급했던 persona-chat을 이용하여 학습된 모델이다.
배경
- 대부분의 Dialoue generation은 단순히 인간의 대화를 학습하여 이를 모방하는 것이 목적
- 즉, 대화 참여자의 정보가 고려되지 않은 채 일반화 된 대화만 생성
메인 아이디어
- Bot은 대화 참여자의 페르소나를 고려한 대화를 생성
- Bot은 대화 참여자가 상호 간의 페르소나를 파악하는 것을 목적으로 학습됨
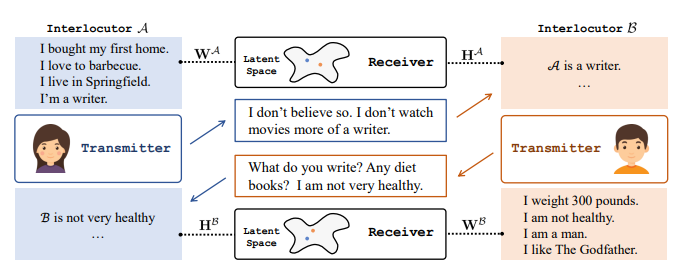
이미지 출처: Liu, Qian, et al. "You impress me: Dialogue generation via mutual persona perception." arXiv preprint arXiv:2004.05388 (2020).





좋은글 감사합니다