
20220716 공부 기록
(1) 데이터 분석 공부 기록
-
infomation is beautiful : 오늘 접근할 UI 접속 주소
-
Coronavirus Riskiest Activities
활동에 따른 코로나 바이러스의 위험도를 시각적으로 표현해준다.
(1) 소제목 : 어떤 자료를 사용했는지 명시, 타인이 봤을 때 객관적인 자료를 사용했는지 알 수 있는 지표가 될 것이다.
(2) 왼쪽 위 : 어떤 요소를 이용했는지 명시. (== 위험도 체크를 할 때, 어떤 기준으로 했는지 명시.)
(3) 색상, 구간, 원의 크기 : 위험도의 정도를 보기좋게 나열해주는 요소가 될 것이다.
따라서, 이러한 시각 자료로 사람들이 어떤 행동이 위험하고 덜 위험한지 금방 알 수 있게 도와준다. 이러한 방식의 디자인은 "어떤 것들의 정도"를 표현할 때 도움이 많이 되는 디자인 방식인 것 같다. 다음에 이러한 자료를 도출해야 하는 경우에 꼭 떠올려보자. -
git crlf auto : 참고 블로그
개행 부분에서 문제가 생겨서 나타나는 경고창이다.
- 필요한 패키지 및 환경 설치하기.
pip install numpy
pip install pandas
pip install matplotlib
pip install seaborn
pip upgrade document # pip upgrade-
dataframe + copy
(1) dataframe
dict을 이용해서 생성하거나, 이중 리스트를 이용해서 생성할 수 있다. 나는 dict으로 만드는 것을 더 선호한다. 두 가지 방식은 출력에서 다른 점이 있다.
(2) copy : 새로운 변수명으로 바꿔도 이전 dataframe을 변경하면 새로운 변수로 바꾼 dataframe도 변경된다.
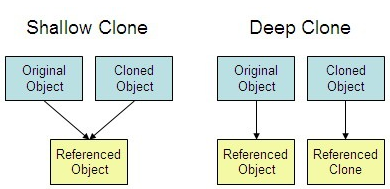
얕은 복사 copy.copy() vs 깊은 복사
copy.deepcopy() : 어떤 차원인지에 따라서 다르다. 1차원은 얕은 복사, 2차원은 깊은 복사를 이용하기. 데이터 전처리 하기 전에 반드시 원본 보존을 위해서 복사한 뒤에 전처리 해주기. -
series
index 수정 시에는 반드시 인덱스의 개수와 값의 개수가 동일해야한다. -
loc & iloc + 조건을 이용한 데이터 추출하기
(1) loc & iloc : 여러 개를 가져오고 싶은 경우에는, 이중으로 대괄호 이용하기.
(2) 조건에 맞는 데이터 추출 : True / False 시리즈 중 True를 뽑기. 여러 조건인 경우에는 괄호를 꼭 씌어주기. 파이썬은 알아서 조건을 잘 묶어내지 못하기 때문에, 사용자가 알아서 묶어줘야한다. -
정렬 + 결측치 처리 + 타입 변환
(1) 정렬하기 : 오름차순, 내림차순
기본적으로 오름차순으로 정렬된다.
ascending=False # 내림차순 정렬
inplace=True # 변수 없이도 알아서 변경
sort_index()
reset_index()
# drop=True를 해주면 제거한 인덱스를 값에 넣어주지 않는다.
sort_values()
# by를 이용해서 기준을 넣어주기.
# 어떤 기준으로 값을 정렬하는지?sort_values를 이용해서 여러개 정렬하는 경우에는 첫 번째 경우는 잘 정렬되지만, 두 번째 경우부터는 첫 번째 경우에 영향을 받으면서 정렬된다.
(2) 결측치
1st : 결측치 유무 확인하기.
sum != count
결측치 유무 확인 시에는, sum 이용하기. sum이 True의 개수를 세어주기 때문이다.
2nd : 결측치를 어떻게 처리할 것 인가???
(2-1) 결측치가 포함된 행 또는 열 지우기.
df.dropna(axis=0) # 행 제거하기
df.dropna(axis=1) # 열 제거하기행은 axis=0 이라고 생각하고, 열은 axis=1 이라고 생각하면 편하다.
(2-2) 결측치를 다른 값으로 대체하기. (평균 또는 0으로 채우기.)
1. 0으로 채우기.
df.dropna(0)
2. 평균으로 채우기.
전체 평균인 경우
df.dropna(df.mean())(2-3) 결측치를 앞 또는 뒤의 값으로 채워주기.
method="bfill" # 뒤의 값으로 채우기.
method="ffill" # 앞의 값으로 채우기.
limit=n
# n개 까지 정해줄 것인지 선택하는 요소이다.(3) 타입 변환
dtypes # 타입 확인하기.
object
to_numeric # 문자형에서 숫자형으로 변경시키기.
# 문자형이 변환이 안되는 경우, 추가적인 요소 이용해서 원하는 방식으로 변경하기.
to_datetime # format 적어주기.
astype # dict 형태로 적어주기.- 추가 + 삭제 + map & apply
(1) 추가
(1-1) append
(1-2) concat
(1-3) 대괄호 이용하기 : 열 추가하기.
(1-4) loc 이용하기 : 행 또는 열 추가하기.
(2) 삭제 : drop, axis 이용하기.
슬라이싱 대신에 리스트 컴프리헨션 을 이용해도 좋다.
그리고, 인덱스로 행 또는 열 삭제가 가능하다. 왜냐하면 인덱스로 행과 열을 삭제하기 때문에, 인덱스를 구해서 제거하는 경우 많다.
drop과 인덱스는 서로 관련이 굉장히 깊다. 꼭 기억하기~! 개발할 때에도 인덱스 이용해서 추가, 제거하는 경우가 많았었다. 추가는 loc, iloc 이용해서 원하는 위치에 잘 넣어주면 된다.
(3) map & apply
map은 간단하게 함수를 적용해서 변경하고 싶은 경우에 이용하고, apply는 좀 더 복잡한 형태를 변경하고 싶은 경우에 이용한다.
기억해야되는 부분
- 정렬하기.
- 결측치 관리하기.
- 추가하기.
- 삭제하기.
- 복잡한 경우에는 map, apply 이용하기.
(2) 프론트엔드 공부 기록
일요일에는 프론트엔드는 공부 못함.
