4학년 '캡스톤 디자인' 과목을 진행하면서 한 고민과 생각의 과정을 담아보았습니다!
프로젝트 선정 과정
프로젝트의 조건
프로젝트 주제를 선정할 때 교수님께서 제시한 조건은 '데이터 분석'을 활용해야 하는 것 이었다. 예를 들어 대학교 주변 공공 데이터를 이용하여 자취방을 추천해준다거나, 경마장 경기 데이터를 활용하여 경기 예측 서비스를 만들어야 했다.
인터넷 리뷰
팀원 중 하나가 시계와 전자 제품에 관심이 많았다. 이 팀원은 평소 이러한것들의 블로그 리뷰를 자주 보는데, 광고 느낌이 물씬 나는 포스팅들이 매우 거슬렸다는 경험을 공유했다. 동시에 이러한 리뷰 광고들을 걸러 주는 서비스를 만드는게 어떻냐는 아이디어를 제안했다.
상당히 괜찮아 보이는 아이디어였다. 나는 과거 pytorch를 이용한 자연어 처리 관련 인터넷 강의를 들은 적이 있었고, 그때 사용한 텍스트 감성분석 코드를 이용하면 효율적인 프로젝트 진행이 가능해 보였다.
소정의 광고료
하지만 '모든 블로그 리뷰' 는 범위가 너무 컸다.
문득 특정 지역의 맛집을 찾고 싶어 네이버에 '홍대 맛집'을 검색하면, 블로그 하단에 '해당 포스팅은 소정의 원고료를 받고 작성되었습니다'와 같은 문구가 적혀져 있던 것이 기억났다. 
동시에 '내돈내산 포스팅입니다!'와 같은 글이 적혀져 있는 블로그도 있었다. 이들을 활용하면 쉽게 레이블링이 가능할 것이라 예상했다.
프로젝트 계획
데이터 수집
- 2만건의 네이버 맛집 블로그 리뷰 크롤링
- 광고 레이블: '해당 포스팅은 소정의 원고료를 받아 작성되었습니다'와 같은 텍스트가 포함된 포스팅 1만건
- 비광고 레이블: '내돈내산의 포스팅입니다'와 같은 텍스트가 포함된 포스팅 1만건
2만건을 목표로 잡은 근거는, 과거 기사 제목을 6개의 주제로 분류하는 프로젝트를 진행한 적이 있는데 이때 데이터가 약 4만건이었고 괜찮은 accuracy를 보여주겄기 때문이다.
모델 학습
비정형 데이터에서 높은 성능을 보여주는 딥러닝을 이용하여 모델을 학습할 예정이다. 기본적인 LSTM과 BERT등을 시도해보면서 높은 성능을 보이는 모델을 선택할 예정이다.
전체적인 구조
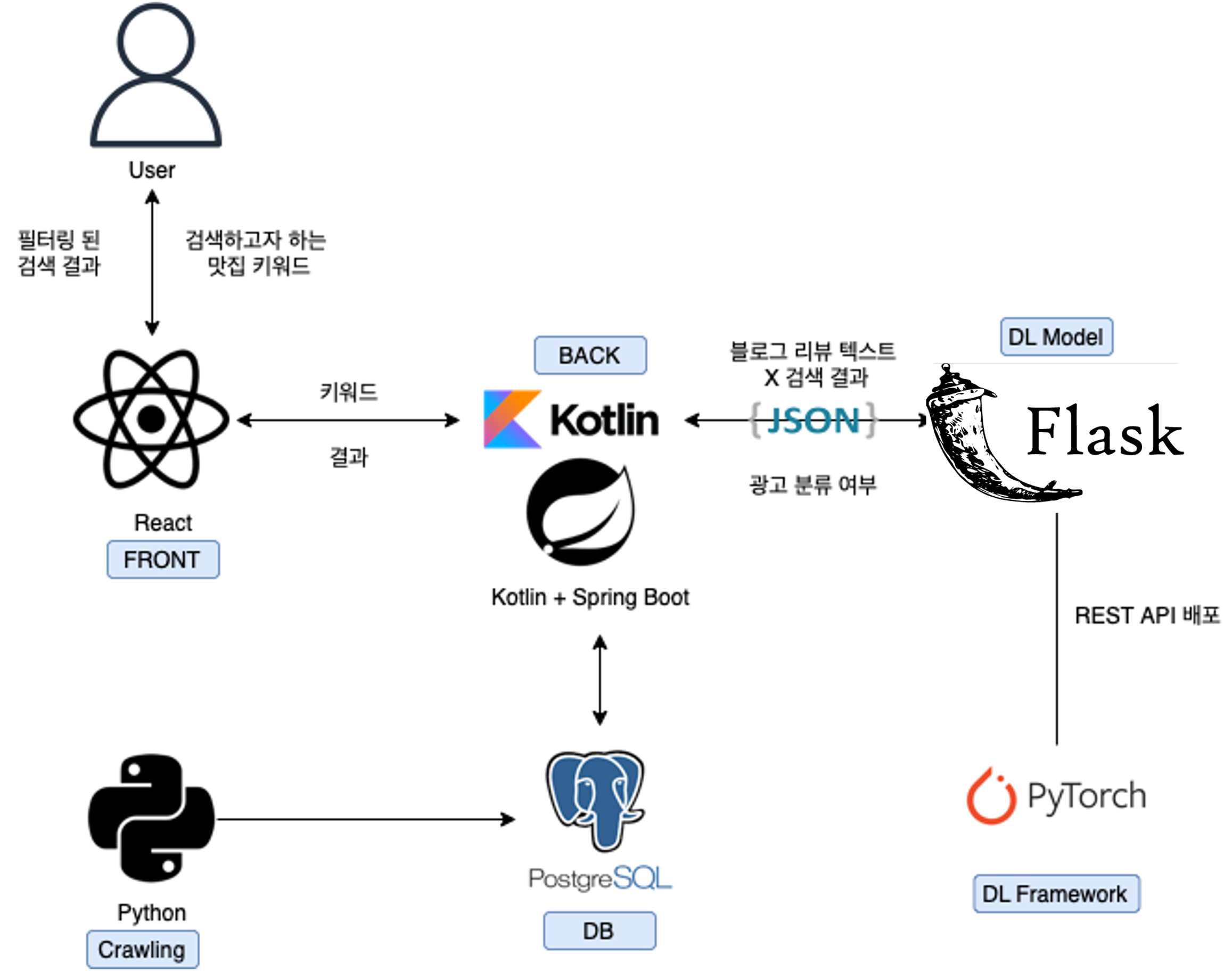
'너무나 단순한 웹페이지에 굳이 React를?' 이라고 생각할 수도 있다. 또한 '백엔드 어플리케이션을 굳이 flask와 Spring Boot로 나누어야 하나?'라고 생각할 수도 있다.
이렇게 나눈 이유는 캡스톤 디자인 프로젝트 기간이 그렇게 길지 않았기 때문이다. 각 팀원들이 사용해본 경험이 있는 기술들을 토대로 역할을 나누어 프로젝트가 효율적으로 진행될 수 있도록 했다!
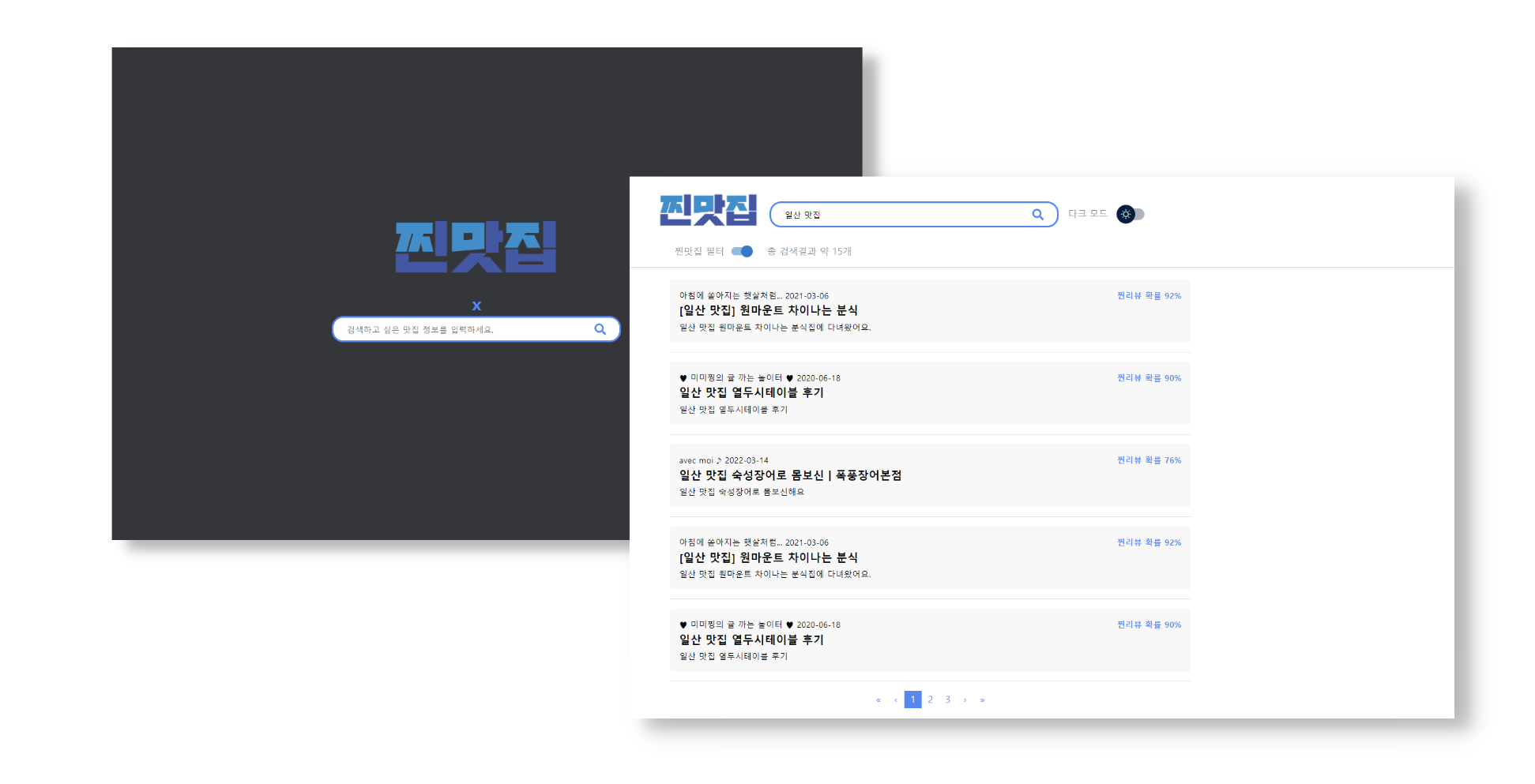
서비스는 검색 엔진과 같은 형태이다. 사용자가 네이버에 '홍대 맛집'을 검색하는 것 처럼, 이 키워드를 우리의 웹페이지에 검색하면 광고 가능성이 높아 보이는 포스팅들을 필터링하여 보여주는 것 이다.
