❔❓ 그게 뭔데 ❔❓
그래프는 어떤 현상이나 사물을 정점과 간선으로 표현한 것 이다. 정점(Vertex)은 대상을, 간선(Edge)는 이들 간의 관계를 나타낸다. 우리는 특정 그래프의 모든 정점들을 확인하고싶을 때가 있다. 이를 위한 대표적인 방법 2가지가 BFS와 DFS이다.
BFS와 DFS는 각각 Breadth-First Search(너비 우선 탐색), Depth-First Search(깊이 우선 탐색)의 약자다.
해당 탐색들이 어떻게 정점들을 확인하는지 직관적으로 알아보기 위해 다음 트리를 살펴보자.
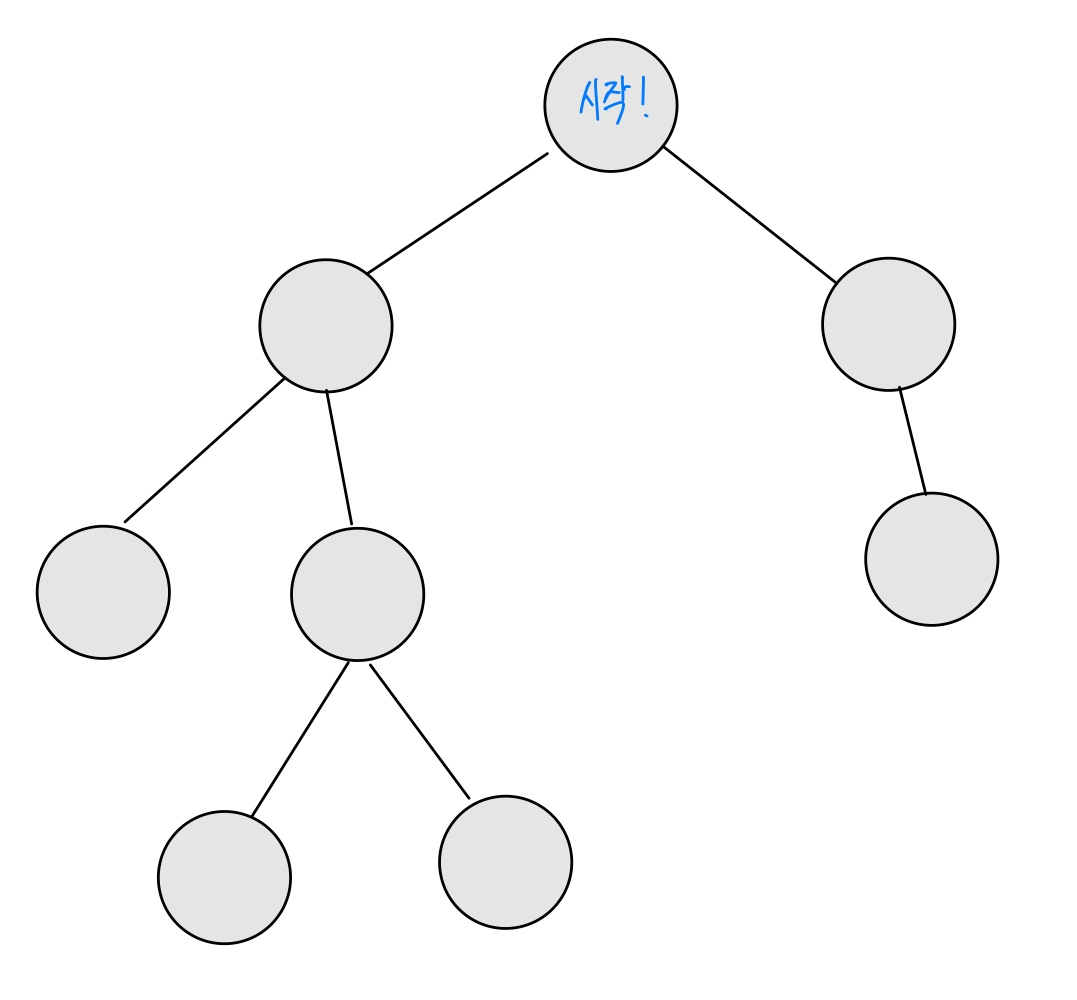
이 트리를 루트에서부터 시작해 모두 탐색하려고 한다. BFS라면 다음과 같은 그림으로 표현할 수 있다.
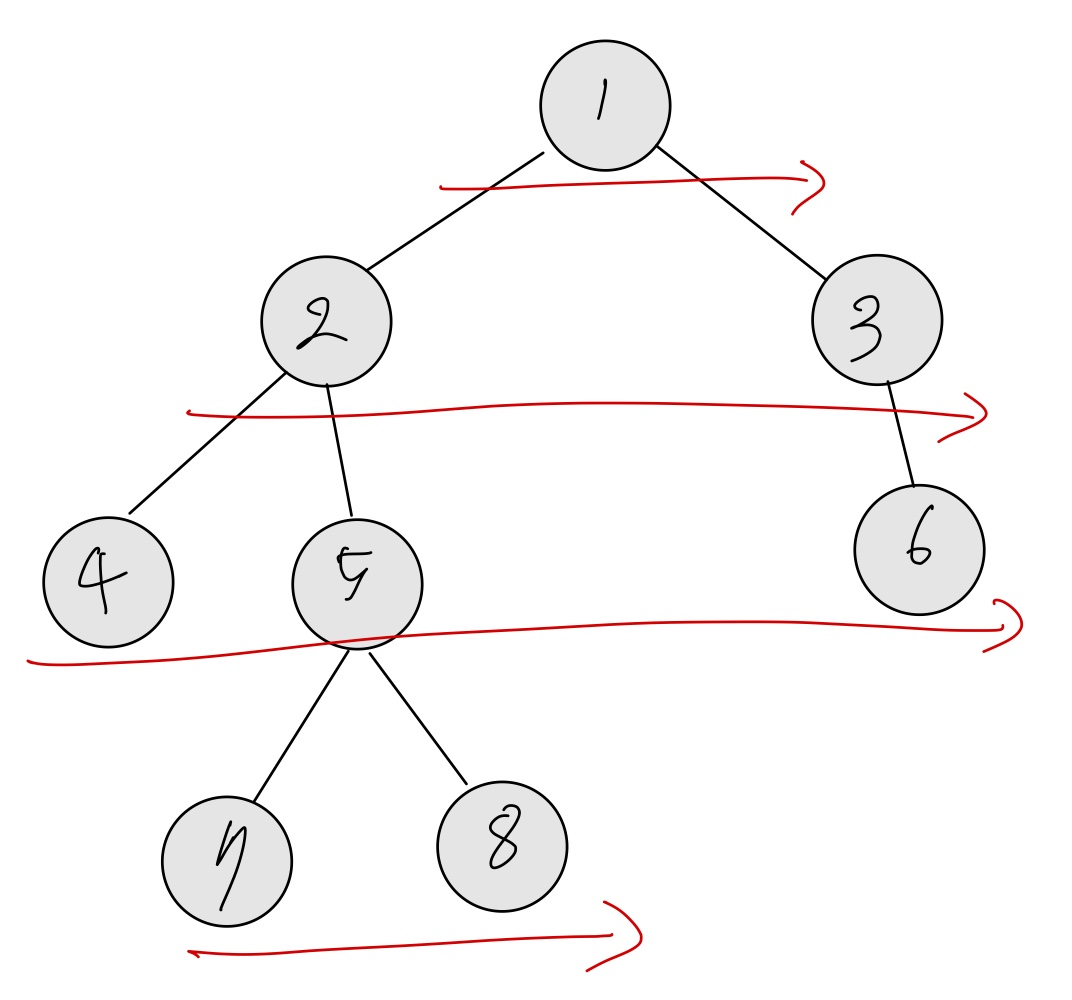
Breadth(너비)가 우선인 만큼, 살펴보고 있는 정점의 깊이와 같은 깊이에 있는 모든 정점들을 우선적으로 살펴보는 것을 알 수 있다.
반대로 DFS라면 다음과 같은 그림으로 나타낼 수 있다.
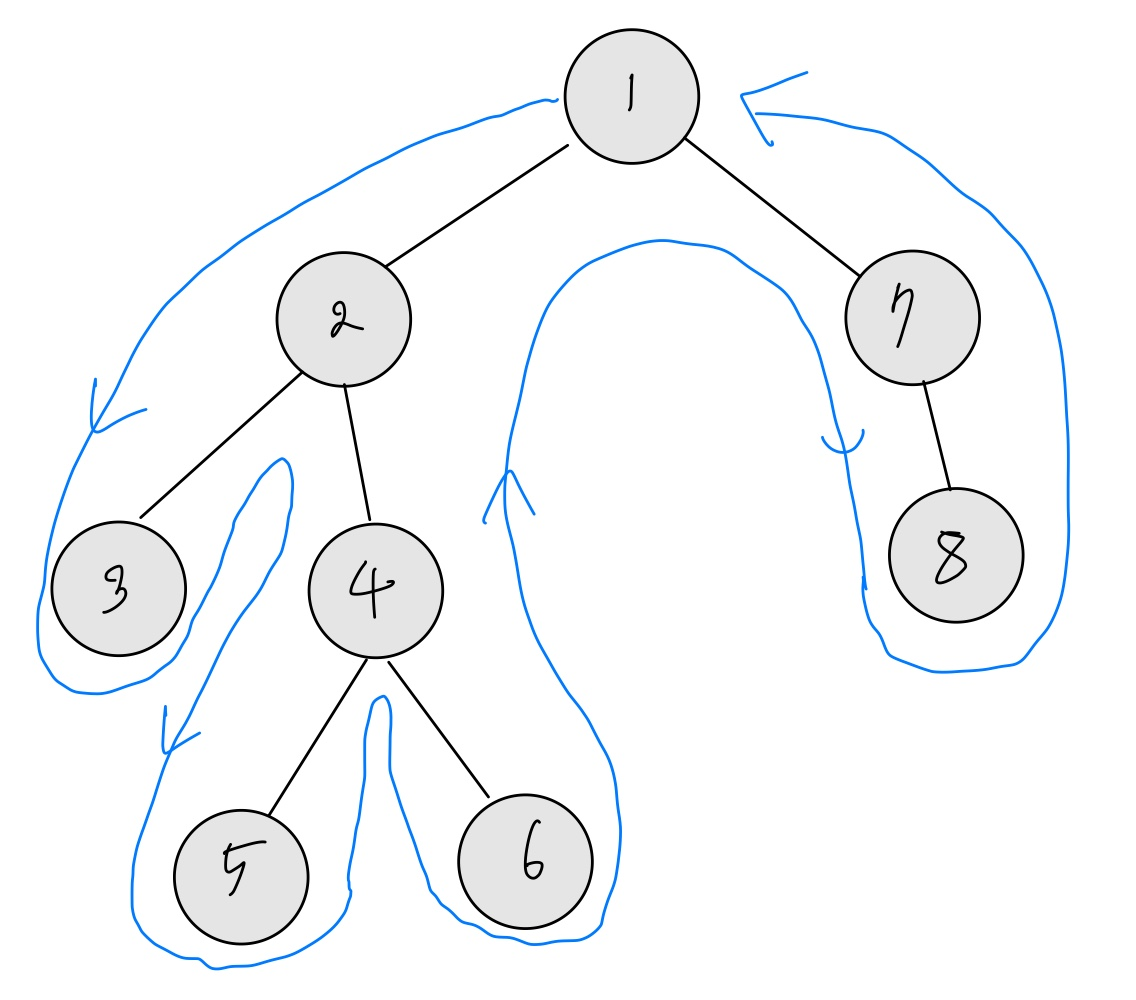
엄청난 그림실력이다 Depth(깊이)가 우선인 만큼, 같은 깊이의 정점보단 최대한 깊숙히 방문하는 것을 알 수 있다.
📌 BFS 구현
BFS를 코드로 구현하기 위해선, 자료구조 중 Queue(큐)가 필요하다. 다음은 BFS 알고리즘을 기술한 의사코드이다.
📍 Queue(큐) 사용
BFS(그래프, start)
{
visited를 false로 초기화;
visited[start] <- true;
queue.enqueue(start);
while (queue에 요소가 하나라도 있을 때) {
u <- queue.dequeue();
for (u와 인접한 정점을 v라고 하며, 순회할때) {
if ( visited[v] == false) then {
visited[v] = true;
queue.enqueue(v);
}
}
}
}📌 DFS 구현
반대로 DFS를 구현하기 위해선 Stack(스택)이 필요하다. 혹은 같은 원리를 함수를 재귀적으로 호출함으로서 구현할 수 있다.
📍 Stack(스택) 사용
BFS와 매우 유사하다.
DFS(그래프, start)
{
visited를 false로 초기화;
visited[start] <- true;
stack.push(start);
while (stack에 요소가 하나라도 있을 때) {
u <- stack.pop();
for ( u와 인접한 정점을 v라고 하며, 순회할 때) {
if (visited[v] == false) then {
visited[v] = true;
stack.push(v)
}
}
}
}📍 재귀 함수 호출 사용
DFS(vertex, visited)
{
visited[vertex] <- true;
for ( vertex와 인접한 정점을 x라고 하며, 순회할 때 ) {
if (visited[x] == false)
DFS(x, visited);
}
}
Backend Developer