KOCW 사이트를 이용하여 듣게 된 반효경 교수님의 운영체제 강의 내용을 간단히 정리하여 포스팅합니다.
지난 강의 리뷰
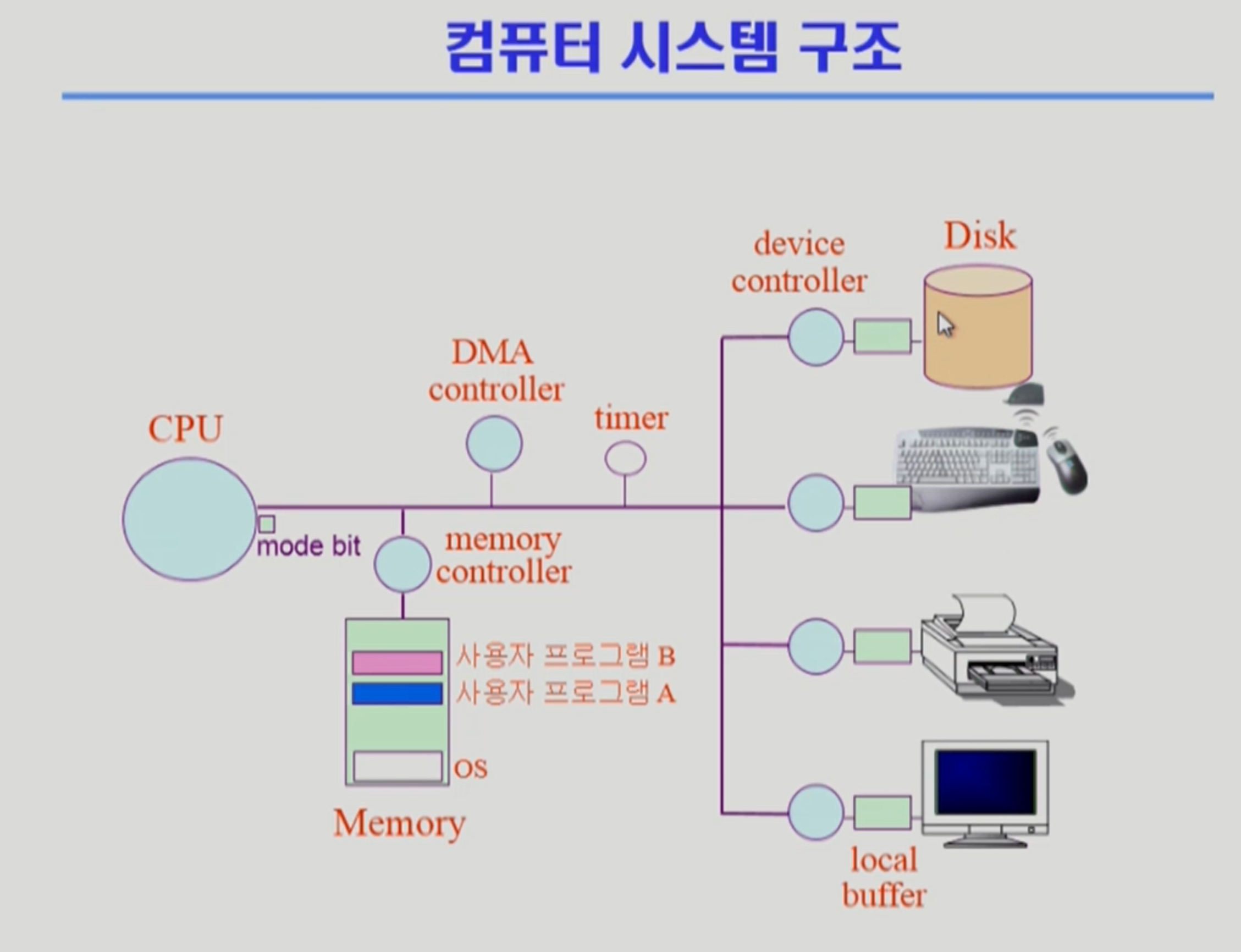
- device들을 전담하는 dc, 데이터 저장하는 작업 공간 local buffer
- cpu에 뭔가 알려주고 싶으면 controller가 interrupt를 걸어 전달할 일을 알려준다.
- cpu는 매 순간 메모리의 어떤 위치에 올려진 기계어(cpu instruction, 0과 1의 조합, 4byte 정도)를 처리한다.
- cpu의 레지스터 중 메모리 주소 가리키는 레지스터인 프로그램 카운터 레지스터가 가리키는 메모리로 가서 인스트럭션을 가져와 실행한다. 이후 프로그램 카운터 레지스터는 4byte만큼 증가하여 다음 위치로 이동(증가)한다. 이렇게 프로그램이 순차적으로 실행될 수 있다.
- 그런데 항상 순차적으로 실행되는 것은 아니다. 점프하는 인스트럭션 만나면 멀리 있는 인스트럭션을 실행할 수도 있다.
- 이렇듯 cpu는 프로그램 카운터 레지스터가 가리키는 메모리 주소의 인스트럭션을 실행하는 일꾼이다.
- cpu는 인스트럭션이 끝날 때마다 interrupt를 확인한다. 만약 있으면 현재 cpu를 누가 사용하고 있었던 운영체제로 제어권이 넘어가게 된다.
- 운영 체제는 인터럽트 마다 어떻게 처리해야 할지 커널 함수로 정의가 되어 있다.(인터럽트 벡터에 있는 인터럽트 처리 루틴(인터럽트 핸들러, 해당 인터럽트 처리하는 커널 함수)을 실행.)
- mode bit 0(운영체제)이면 모든 instruction 실행 가능하며, 1(사용자 프로그램)이면 한정된다.
- 사용자 프로그램은 100% 믿을 수 없으므로. instruction set에서 막아둔다.
- 그러므로 사용자 프로그램은 interrupt line에 system call을 요청하여 io 작업을 수행한다.
- timer도 cpu에 인터럽트를 걸 수 있다. mode bit을 통해 보안적으로는 사용자 프로그램을 막았지만, 지속적인 cpu 사용을 막기 위해서는 timer를 사용하게 된다.
- 운영 체제는 timer를 통해 여러 프로그램들을 함께 실행할 수 있게 된다.
동기식 입출력과 비동기식 입출력

- synchronous → 일반적으로 안 쓰는 단어 - 시간을 맞추는 것.
ex) 립싱크 - 노래와 입술 모양을 맞추는 것.
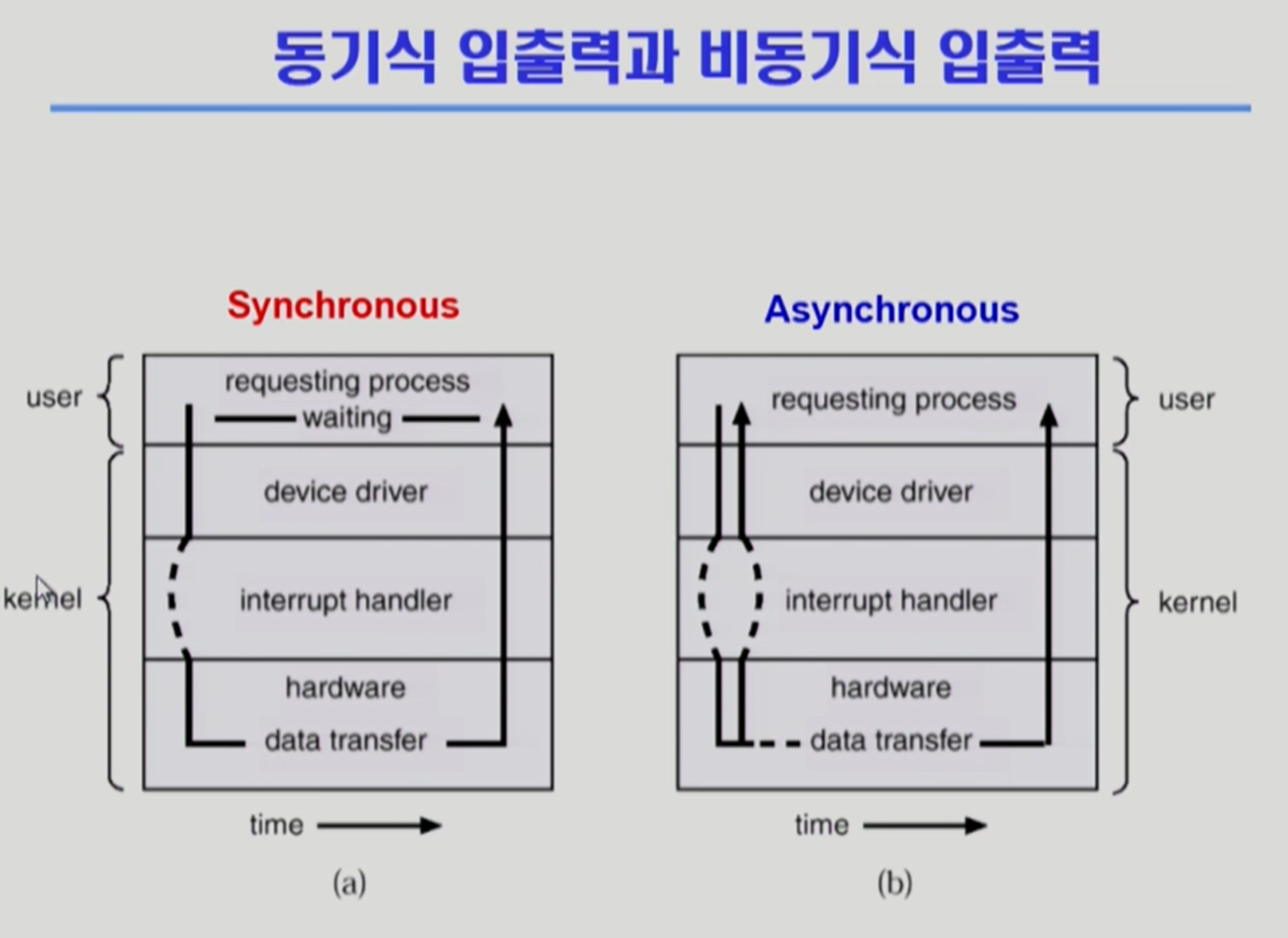
-
write는 async 하게 작동되는 것이 자연스러움. 만약 sync하게 작업시키고 싶을 때 sync 쓸 수도 있음. 구현하기 나름인 것.
-
그런데 io는 비교적 (cpu 작업에 비하면) 오래 걸리는 작업이므로 이를 기다리면 cpu가 낭비 될 수 있다. 그래서 다른 동기 프로세스에 cpu를 넘기게 된다. 이것이 위에 있는 구현 방법 2이다. 동기식 입출력이 보통 이 방식으로 구현된다.
-
io 작업이 끝나면 cpu에 인터럽트 걸게 된다. 그런데 io 작업이 쉴새 없이 쏟아진다면..?
DMA Controller
- 문제: io device로 인한 cpu로의 interrupt가 너무 많아진다면 => cpu가 효율적으로 동작을 할 수 없다.
⇒ DMA도 메모리에 접근할 수 있게 해서 IO 작업들을 메모리에 쌓고, 어느 정도 쌓였으면 cpu에 interrupt를 걸어 작업을 하도록 한다.
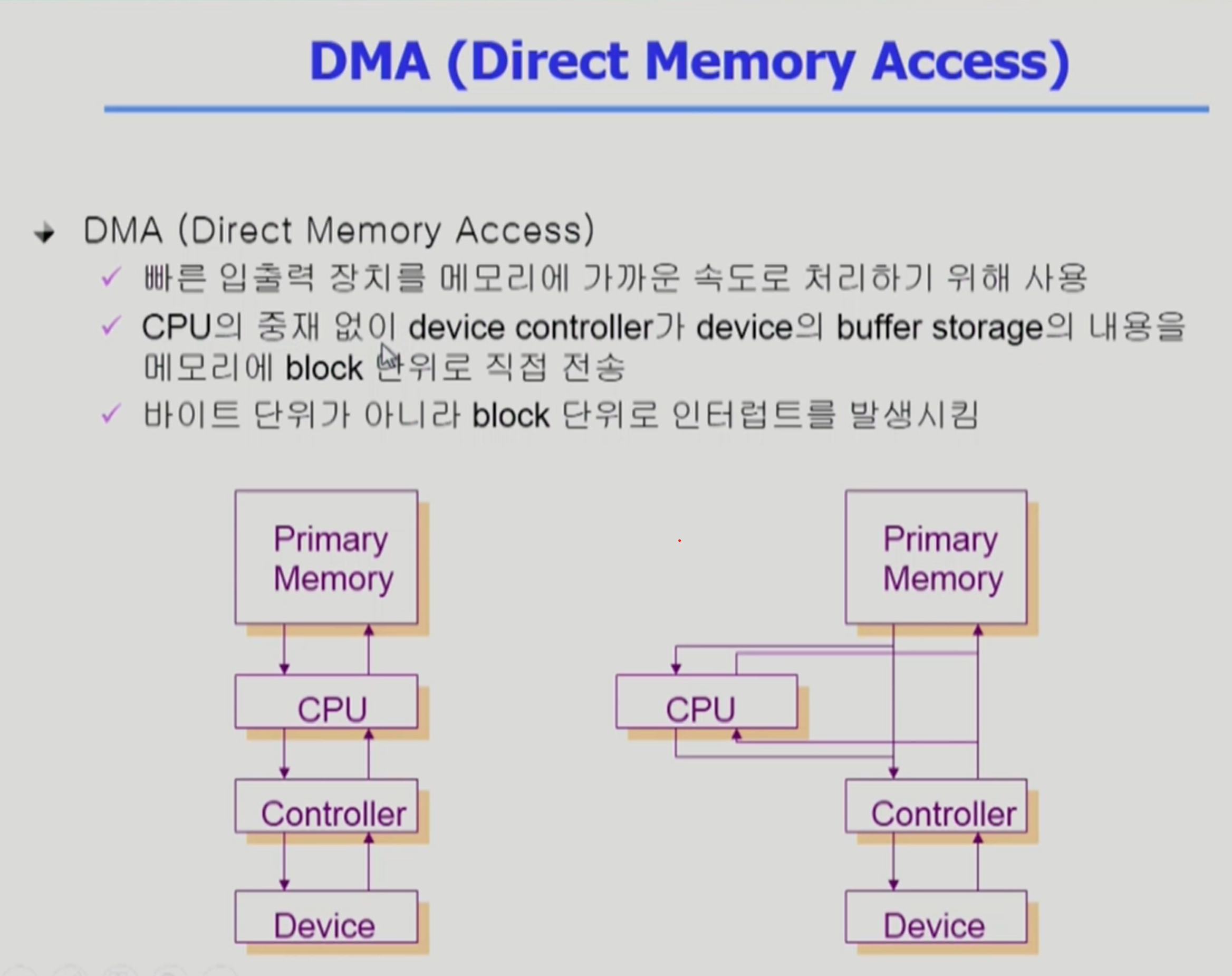
- 빠른 입출력 장치일 경우 interrupt를 더 많이 걸 것이므로 중간에 DMA 컨트롤러가 꼭 존재해야 한다.
IO를 할 수 있는 방법 2가지
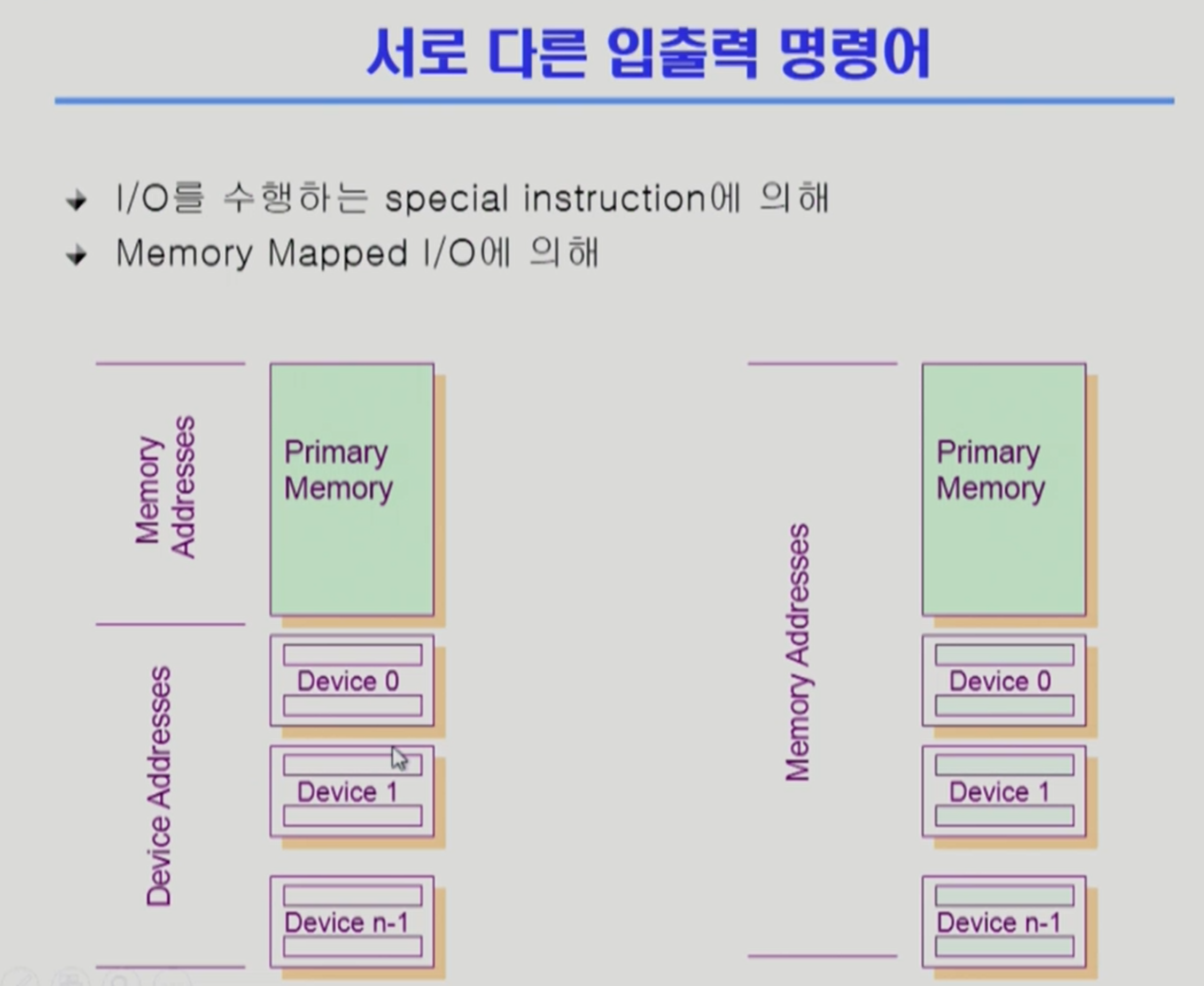
-
왼쪽은 일반적인 IO 방식이다. 메모리 접근해야 하는 instruction과, 각 io device별로 접근하는 instruction이 각자 따로 있다.
-
오른쪽은 Memory Mapped I/O 방식으로, io device에다가 메모리 주소의 연장 주소를 붙여서 접근한다.
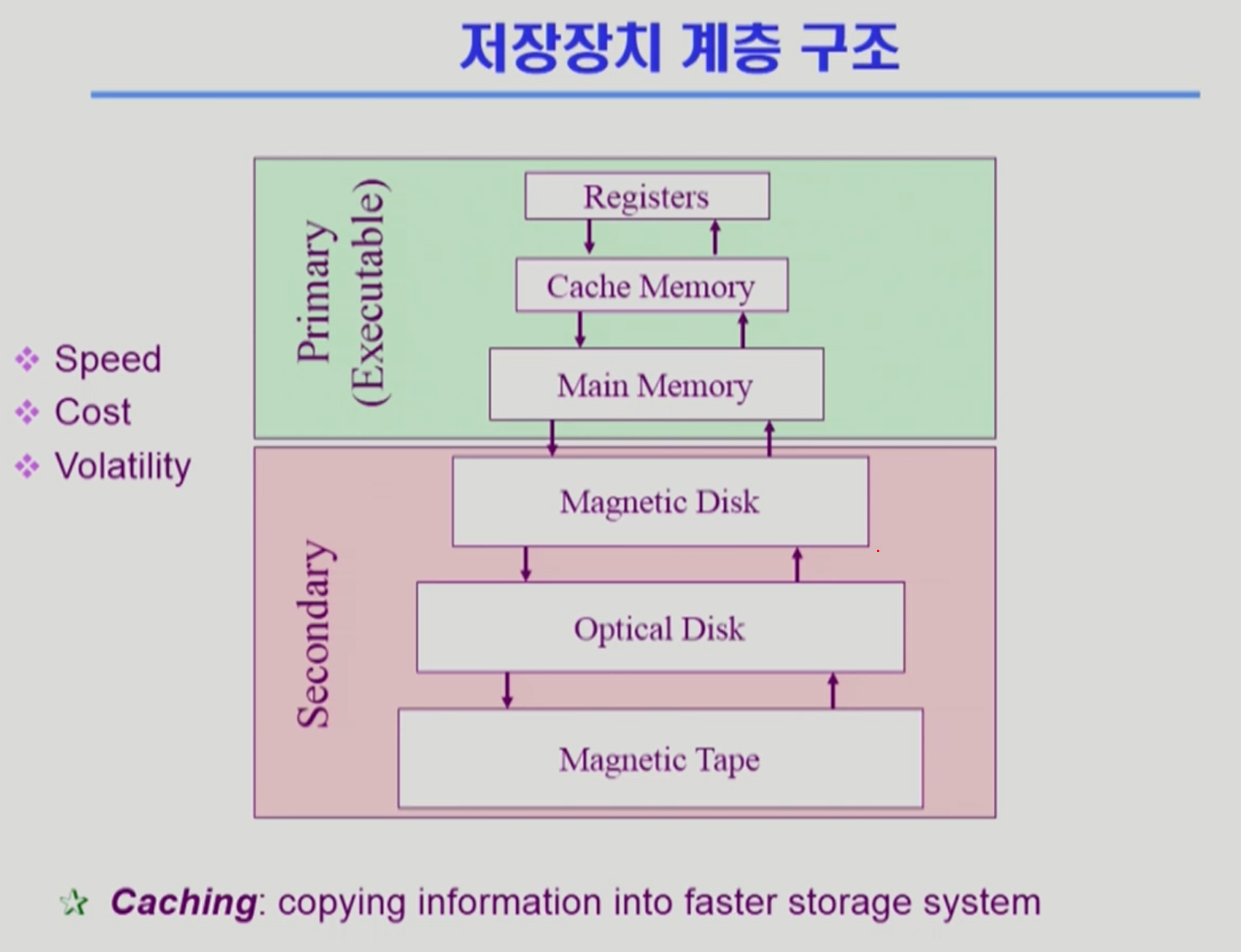
저장 장치 계층 구조
-
위로 갈수록 빠르고, 비싸고, 용량이 적고, 휘발성이다.
-
primary 영역 → cpu가 접근해서 실행이 가능한 바이트 단위로 접근이 가능하다. 바이트 단위로 접근이 가능하다.
-
secondary 영역 → byte 단위가 아닌 섹터 단위로 접근이 가능하다. executable하지 않은 매체이다.
-
Caching → 빠른 매체로 정보를 읽어 들여 놓아 사용하는 것이다. 그러나 용량이 작으므로 어떤 것을 지우고 할 지가 주요 이슈가 된다.
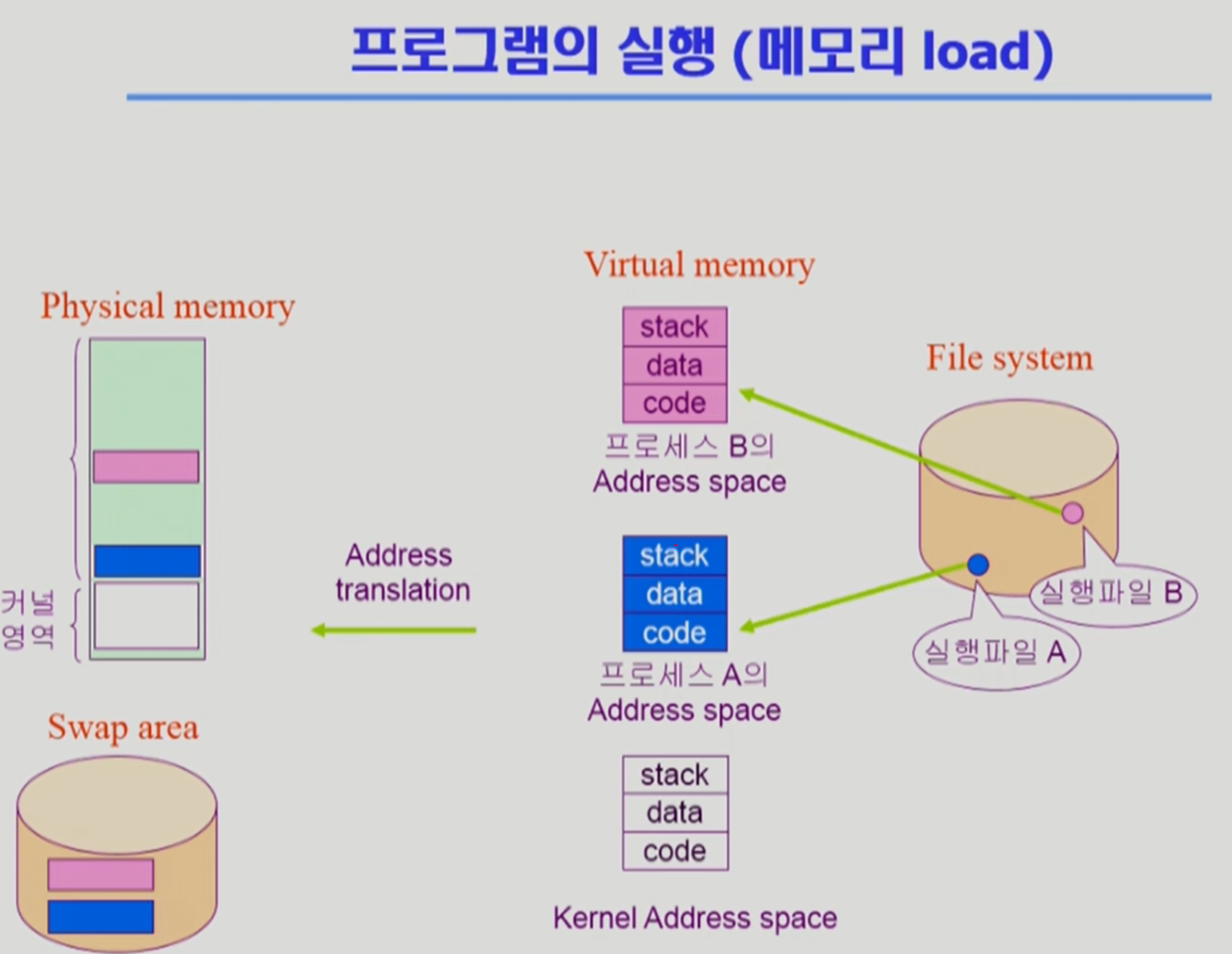
프로그램이 실행되면..
-
프로그램은 disk 상에서 file system 용도로 자신만의 독자적인 주소 공간을 가진다. 이를 virtual memory라고 하며, code(기계어 코드), data(전역 변수), stack(함수 호출, 리턴 시 스택으로 쌓는 영역)으로 구성되어 있다.
-
프로그램이 실행되면, 이를 물리적인 메모리로 올려서 실행하게 된다. 프로그램을 물리적인 메모리에 다 올리는 게 아니라 필요한 부분만 올려서 사용한다. 그래서 메모리의 낭비를 줄일 수 있다. 필요가 적어진 메모리는 디스크의 swap에 내려놓게 된다(메인 메모리의 연장 공간).
-
프로그램마다 각 주소는 0번지 부터 시작하게 된다. 그런데 virtual memory에서 physical memory로 갈 때 주소가 변환되어야 하는데, 이는 하드웨어의 도움을 받아야 한다. (logical memory address → physical memory address)
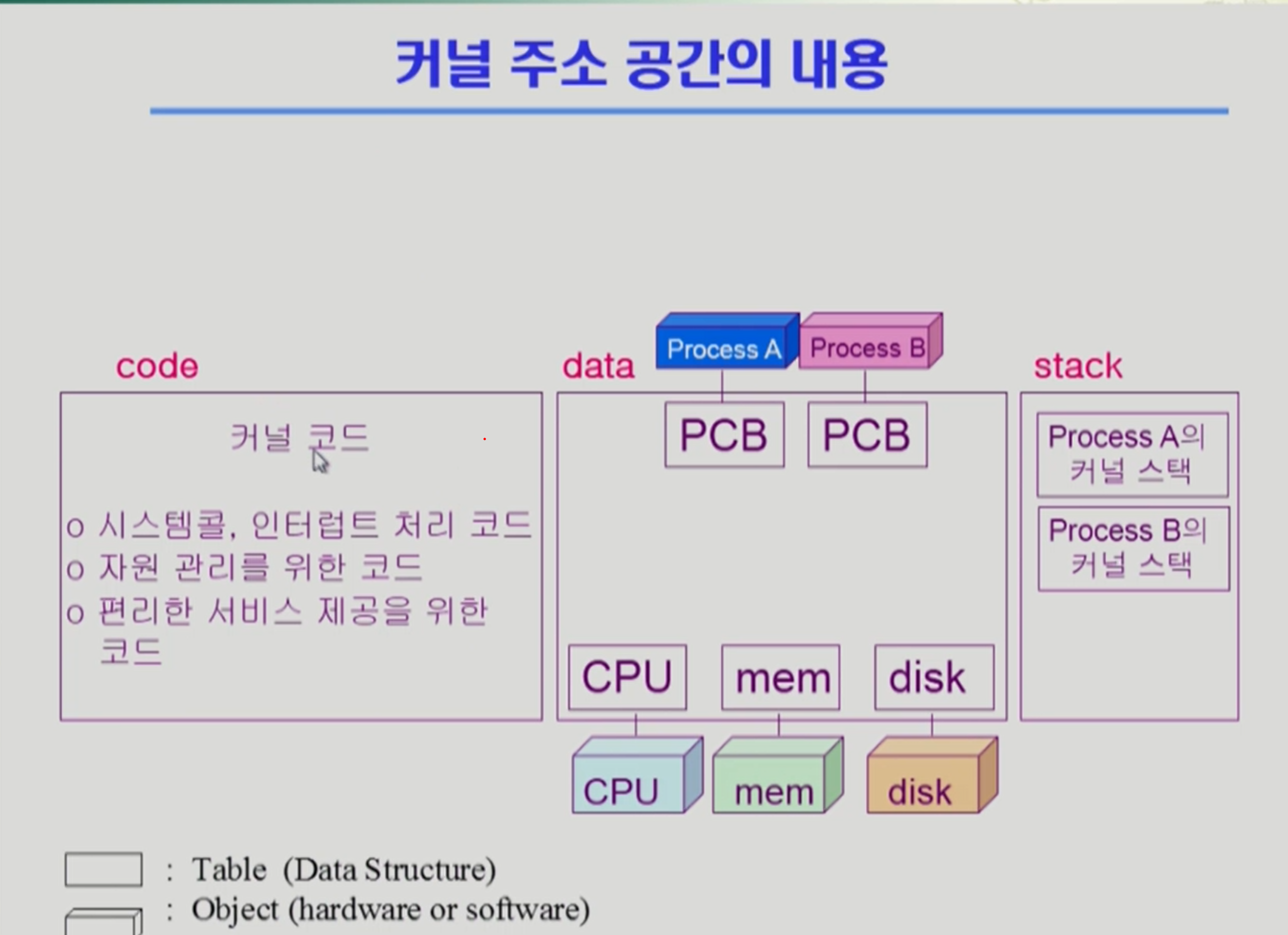
커널 주소 공간의 내용
-
cpu, mem, disk 하드웨어를 관리하기 위해서 커널 내 data 영역에 주소 공간을 만들어 관리를 하게 된다.
-
커널은 프로세스도 관리하게 되는 데, 각 프로그램 마다 운영체제가 관리하는 자료구조가 필요하다. program contral block. 프로세스 마다 pcb가 만들어져 관리하게 됨.
-
함수 호출 및 실행에 스택 영역이 사용됨.
-
사용자 프로그램마다 커널 스택도 따로 두게 됨.

-
대부분의 프로그래밍 언어는 함수 구조로 짜여져 있다. 기계어로 컴파일 되어도 어디부터 어디까지가 함수 구조로 짜여져 있는지 쓰여져 있다. 또한 컴파일 시 프로그램 안에 포함되어 있는 함수는 사용자 정의 함수, 라이브러리 함수이다.
-
반면에 커널 함수는 커널 코드 안에 들어 있는 함수이다.
-
사용자 프로그램 안에는 사용자 함수 및 라이브러리 함수의 코드가 있으므로, 커널 함수를 쓰고 싶다면 점프를 해야 한다.
-
그런데 점프는 physical memory 상에서 이루어지는 것이므로, 사용자 코드에서 커널 코드로 점프를 하는 것은 불가능하다.
-
따라서 system call을 통해 커널 함수를 호출해야 한다.
==> 커널 함수 호출할 때는 system call을 통해서 cpu 자원을 kernel로 넘어가게 해서 커널 함수를 실행하게 된다.
-
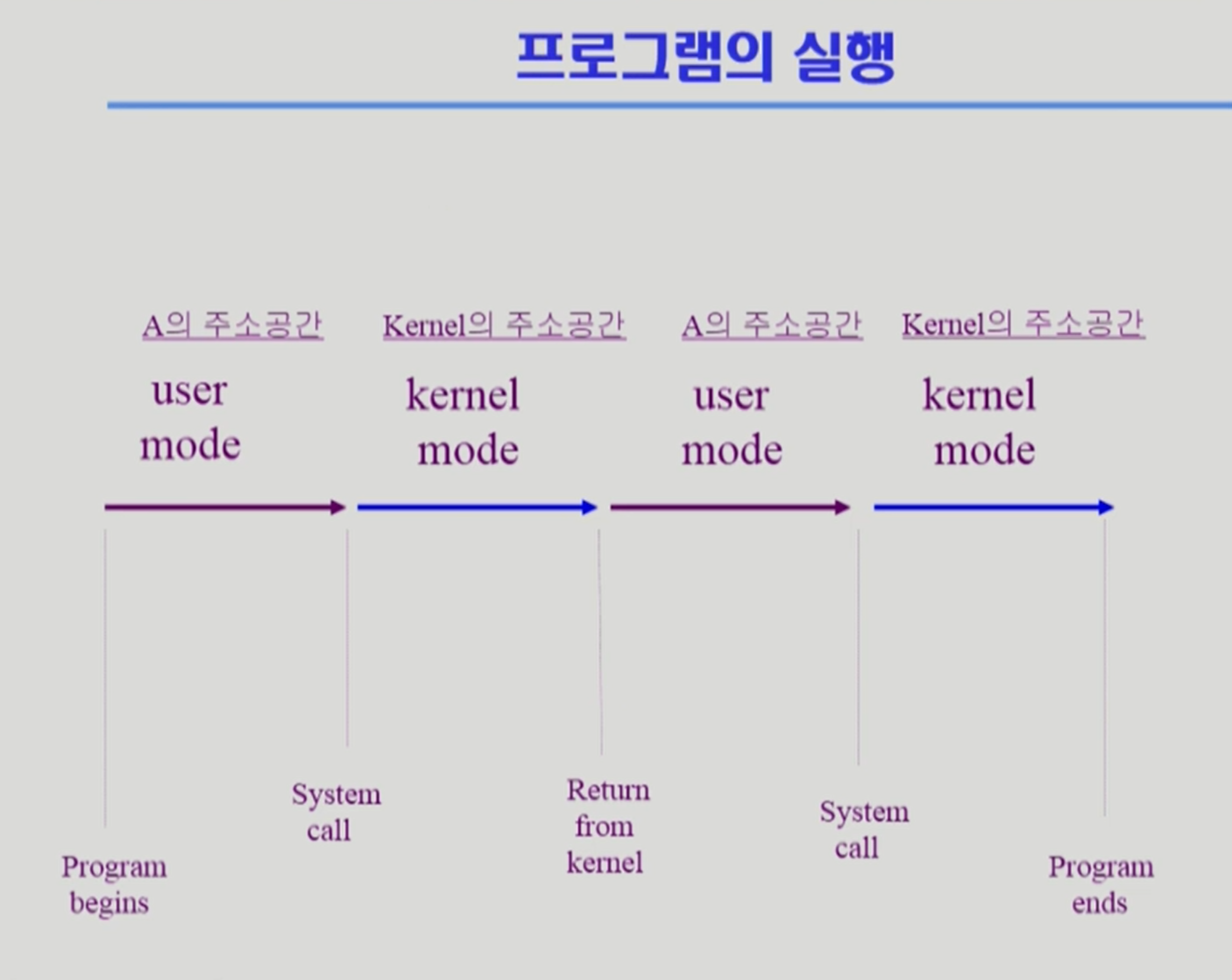
프로그램의 실행
-
프로그램의 실행을 user mode와 kernel mode로 나누어 살펴본 사진이다. program이 cpu 잡고 있을 때 → user mode이고, system call을 하게 되면 kernel로 제어권이 변경되며 커널 공간의 코드가 실행된다. 시스템 콜이 끝나면 프로그램으로 cpu 제어권이 넘어오고 다시금 자기의 제어권에 있는 코드를 실행하는 양상이 반복된다.
참고
강의 | 운영체제(2014, 이화여대), 반효경