단축 URL 생성 및 조회 서비스(like bitly)를 만들어보고, 그 과정을 기록해보았습니다.
프로젝트 GitHub 주소
프로젝트에 지난 포스트에서 언급했던 사항들이 반영되었습니다.
이에 대해 이야기해보고자 합니다.
먼저 지난 번 이야기했던 2가지 방식이 수정되었습니다.
지난 포스트에서 고려된 수정 사항들
1. 전역 예외 핸들러 추가
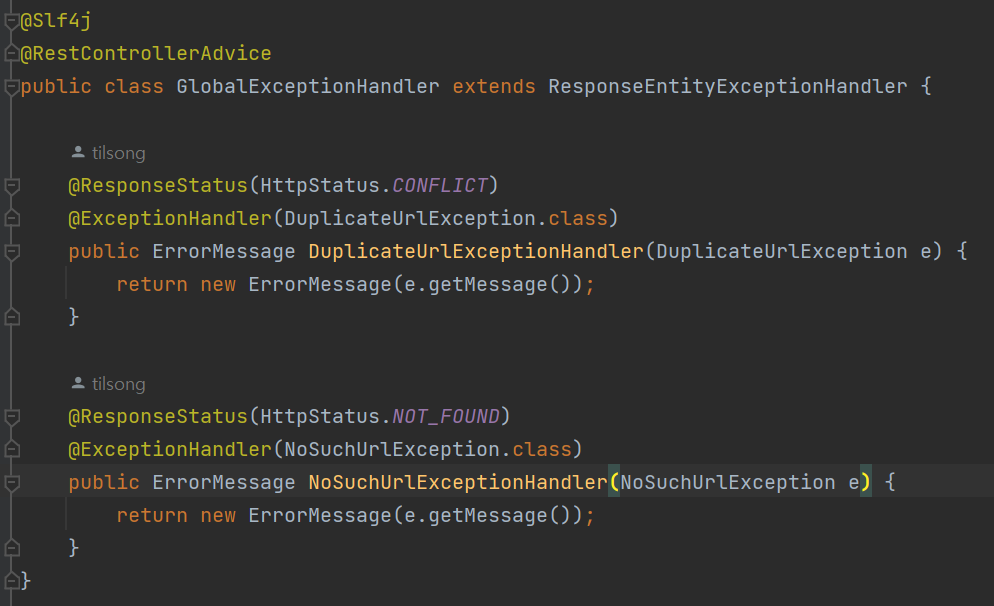
이를 통해 이제 각 레이어에서 필요할 경우 예외를 발생시킬 수 있게 되었고, 그에 대한 처리를 예외 핸들러를 통해 전담할 수 있게 되었습니다. (너무나 편리)
더불어 컨트롤러에서 예외를 발생시킬 수 없었던 지난 포스트에서의 문제도 해결되었습니다.
2. Stream 문법 재적용
-
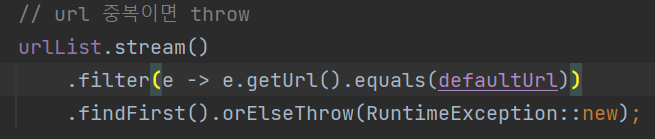
기존 - 스트림 문법을 다음과 같이 적용했습니다. 저장된 URL 리스트에 defaultUrl과 일치하는 것이 있으면(중복이면) 예외를 반환하는 것이 원래의 의도였는데, 아래 코드는 사실 요소가 없을 때 예외를 반환했습니다. (지난 게시물 참조)
-
변경 후 - 원래의 의도대로 코드가 수정되었습니다. 일치하는 요소가 있으면 이를 반환하고, ifPresent로 받아 예외를 반환하는 것입니다.

여기서 의외로 조금 헤매게 되었는데, 람다식에서 throw 문법으로 하나의 state문을 만들게 되면 위 코드처럼 중괄호를 감싸주고, 또 마지막에 “;”를 찍어주어야 하는 것을 몰랐습니다. 자바를 많이 써봐야 할 것 같습니다..
추가로, 코드를 작성하면서 새롭게 겪게 되었던 문제들에 대해서도 나누어보고자 합니다.
새로운 이슈들
1. 에러 로그 설정에 관한 이슈
1) 기존 에러 로그 적용 방식
-
기존에도
@Slf4j를 사용하여 로그를 작성했지만, 로그 레벨을 어떻게 사용해야 하는지에 대해서는 깊이 생각하지 않고 사용했습니다.단순 모니터를 위한 로그라면 Info로, 예외가 발생하여 기록하게 되는 로그라면 Error로 기록했었습니다. 그러나 멘토님께 이 부분을 지적 받았고, 다시 생각하게 되었습니다.

2) 변경된 방식
- Error의 경우, 시스템 자체에 문제가 생겨 개발자가 개입을 해주어야 되는 상황에만 사용하도록 했습니다. 예외가 발생하더라도, 사용자의 문제로 인해 발생한 것이거나 애플리케이션 내에서 당연히 발생될 수 있는 것들은 Error로 관리되지 않습니다. Error 로그의 경우, 개발자가 확실한 문제 상황으로 보고 해결해야 할 상황에 사용되어야 하는 로그이므로 엄격하게 관리되어야만 합니다.
-
Warning의 경우, 당장 시스템에 문제를 일으키지는 않지만 일으킬 여지가 있는 이상 동작이 발생하는 경우, 예를 들어 입력이 단 시간에 연속적으로 발생하는 경우 사용될 수 있습니다.
-
Info의 경우, 시스템의 진행 상황을 표현하는 정보를 위해 사용될 수 있습니다.
2. Repository 레이어의 인터페이스의 메서드 시그니처 문제
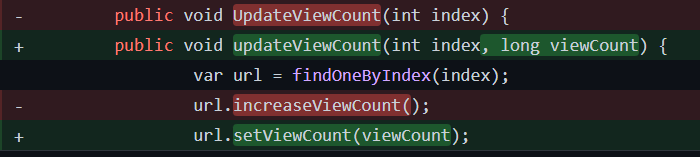
URL에 대한 조회수를 업데이트하는 로직을 레포지토리 레이어에 할당했었고, 이것이 문제가 되었습니다. 이로 인해 도메인의 각 필드에 대한 수정에 대한 책임을 레포지토리가 가지게 되었기 때문입니다. 그러나 이는 레포지터리의 책임이 아닙니다.
이로 인해 레포지토리의 코드가 중복될 가능성이 높아졌고, 또한 각 필드에 대한 수정을 위한 메소드를 하나하나 다 만들게 되었을 때 레포지토리의 메서드가 수도 없이 많아지게 될 위기에 처했습니다.
이러한 문제가 발생한 원인은 결국 각 레이어(Service, Repository, Domain)에 대한 이해가 부족하기 때문이었습니다. 그러나 기존에 가지고 있던 Controller, Service, Repository에 대한 지식만으로는 더 이상의 레이어에 대한 이해가 어려웠습니다.
그러다가 Layered Architecture와 DDD를 만나게 되었고, 이를 통해 각 레이어와 도메인, 그리고 Entity 등 기존에 사용은 했으나 제대로 이해하지 못하고 있던 개념들을 새롭게 이해해볼 수 있었습니다. Layered Architecture와 DDD에 대해서는 추후 게시물을 통해서 다루어 보겠습니다.
*DDD 이해를 위해 “도메인 주도 개발 시작하기: DDD 핵심 개념 정리부터 구현까지, 최범균”을 읽었습니다.
3. 비동기 처리에 대한 오버 엔지니어링
기존에 조회수를 업데이트하는 로직은 사용자가 단축 URL과 함께 원본 URL에 대한 리다이렉트 요청을 했을 때 실행되었습니다.
이 때, 조회수 업데이트 로직은 사용자의 요청에 대한 응답에 대해서는 무관하므로 분리되어 실행되는 것이 더 나을 것 같다고 생각했습니다. 더 정확히는, 사용자의 요청에 대한 응답을 전송하기 까지의 성능에 조회 수 업데이트 로직이 영향을 주지 않아야 한다고 생각했습니다. 그래서 이를 비동기로 처리하고자 했습니다.

위 사진의 코드처럼 비동기 스레드들을 생성하고, 아래 사진의 메서드를 사용하여 조회 수 업데이트를 실행하도록 했습니다. (그 와중에 업데이트에 대한 락 스트라이핑도 적용했습니다)
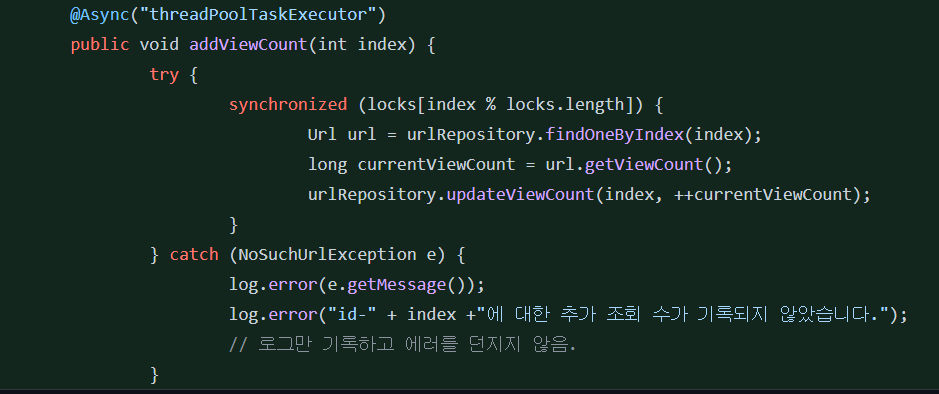
이것저것 다 적용하니깐 나름 괜찮은데? 라고 생각을 했는데..
멘토님은 다른 생각이셨습니다. 만약 이 부분이 애플리케이션의 UX를 좌우하는 부분이었다면 성능적으로 개선을 해볼만 하겠지만, 그런 영역이 아니며 (단순히 DB 접근을 통한 UPDATE를 수행하는 로직) 오히려 비동기 로직으로 인해 더 많은 리소스가 사용되고 코드의 복잡성이 불필요하게 증가했다고 말씀을 해주셨습니다.
이를 오버 엔지니어링이라고 한다고 합니다. 현재 필요한 것보다 더 과하게 제품을 디자인하는 것을 말합니다. 반대되는 말로는 필요한 만큼만 제품을 디자인한다는 의미를 담은 적정 엔지니어링이 있습니다.
그래서 오버 엔지니어링된 비동기 부분을 제거하고, 코드를 깔끔하게 개선했습니다.
4. 단축 URL의 ID 생성 방법
이 프로젝트의 메인 도메인인 URL의 식별자는 ArrayList로부터 부여되는 Index 값이었습니다. 해당 값을 ID값으로 사용한 이유는 ArrayList를 사용할 때 적절한 식별자이자, 가장 비용이 적게 들어가는 ID 생성 방식이라고 생각했기 때문입니다. (그러나 이 때문에 Synchronized 등 불필요한 동기화 처리에 대한 비용이 들기도 했습니다..) 더불어 ID를 단축 URL로 변환할 때 ID가 숫자 타입이어야 했으므로, 적절해 보였습니다.
따라서 ArrayList의 Index를 통해서 URL을 검색하고, 얻어내도록 로직을 작성했습니다. 이와 함께 Repository 인터페이스의 메서드 시그니처에는 index 파라미터가 붙어 다녀야만 했죠. 그러나 멘토님께서는 다른 Repository 구현체, 즉 Map이나 RDB 등이 추가되어 사용되었을 때를 고려했을 때, 이는 좋은 선택이 아닐 수 있다고 말씀해주셨습니다.
확장해도 DB의 auto_increment를 쓰면 되지 않냐는 생각으로 Index를 그냥 사용했었는데, 생각해보니 문제가 이만저만이 아니었습니다. 이에 대한 내용을 책 “가상 면접 사례로 배우는 대규모 설계 시스템 기초”를 통해서 살펴 보았습니다.
책 “가상 면접 사례로 배우는 대규모 설계 시스템 기초”를 통해서 ID 생성 방법 살펴보기
책의 7장에서 “분산 시스템을 위한 유일 ID 생성기 설계”에 대해서 다루고 있습니다.
책에서 만들고자 하는 ID 생성기의 요구사항은 다음과 같습니다.
- 유일해야 함
- 숫자로만 구성됨
- 64비트로 표현될 수 있어야 함
- 발급 날짜에 따라 정렬 가능해야 함
책은 몇 가지의 고려할 수 있는 방법을 추천해주었습니다.
-
다중 마스터 복제(Multi-master replication)
a. 이 방법은 DB의 auto_increment 기능을 활용하는 것인데, 다만 ID의 값을 구할 때 1만큼 증가시켜 얻는 것이 아니라 K만큼 증가시키게 됩니다. K는 현재 사용 중인 데이터 베이스 서버의 수입니다. 이는 규모 확장성 문제를 어느 정도 해결할 수 있습니다.b. 단점
1) id의 유일성은 보장하나, 그 값이 시간 흐름에 맞추어 커지도록 보장할 수는 없습니다. 이는 서버 별로 다른 K 증가 수를 가지고 있기 때문입니다.
2) 서버를 추가하거나 삭제할 때 잘 동작하도록 만들기 어렵습니다.
3) 여러 데이터 센터에 걸쳐 규모를 늘리기 어렵습니다.
-
UUID(Universally Unique Identifier)
a. UUID는 컴퓨터 시스템에 저장되는 정보를 유일하게 식별하기 위한 128 비트짜리 수이며, 충돌 가능성이 지극히 낮습니다. 중복 UUID가 1개 생길 확률을 50%로 끌어 올리려면 초당 10억 개의 UUID를 100년 동안 계속해서 만들어야 한다고 합니다.b. 만드는 것이 단순하며, 서버 사이의 조율이 필요 없으므로 동기화 이슈도 없습니다. 각 서버가 자기가 쓸 ID를 알아서 만드는 구조이므로 규모 확장도 쉽습니다.
c. 단점
1) ID가 128비트로 깁니다.
2) ID를 시간 순으로 정렬할 수 없습니다.
3) ID에 숫자가 아닌 값이 포함될 수 있습니다. -
티켓 서버(Ticket Server)
a. 단순히 단일 DB를 사용한다면 auto_increment를 사용할 수도 있습니다. 유일성이 보장되는 오직 숫자로만 구성된 ID를 쉽게 만들 수 있습니다.b. 구현하기 쉽고, 중소 규모 애플리케이션에 적합합니다.
c. 단점
스케일 아웃을 고려한다면, 이 방식은 좋은 방식이 아닙니다. 단일 장애점(Single-Point-Of-Failure, SPOF)이 될 수 있고, 만약 이 이슈를 피하려고 티켓 서버를 여러 대 준비한다면 데이터 동기화와 같은 새로운 문제가 발생하게 될 수 있습니다. -
트위터의 스노플레이크(Snowflake) 접근법
a. 이 방법은 분할 정복 방식(Divide and Conquer)을 사용합니다. 생성해야 할 ID를 여러 절(Section)으로 분리하는 것입니다.b. 주어진 ID의 비트가 64일 때,
1) sign 1비트는 음수와 양수 구별을 위해
2) 타임 스탬프를 위해 41 비트를
3) 데이터 센터 식별을 위해 5비트를
4) 서버 식별을 위해 5비트를
5) 일련 번호 12비트를 사용합니다.c. 스노플레이크 방식을 사용하면, 요구사항을 만족하면서도 분산 환경에서 규모 확장이 가능합니다.
책의 내용을 고려했을 때 Repository의 구현 객체 변경을 고려한다면, URL 도메인에 ID 필드를 추가하는 것은 피할 수 없어 보입니다.
현재 방식을 유지한다면
1. 메모리를 사용하므로 저장에 한계가 있습니다.
2. 스케일 아웃이 불가합니다.
3. 서버가 단일 장애점으로 작동합니다.
그러므로 Url 도메인에 ID 피드를 추가하고, 위 방식 중 적절한 방법을 찾는 것이 좋아 보입니다. 모든 Repository 구현체에 적용될 수 있고, Indexing이 가능하며 Scale-out이 가능한 방식은 스노플레이크입니다. 스노플레이크 자체에 구현 비용이 들 수는 있지만, 구현 후에는 확실히 성능 상으로나 서버의 확장면에서 이점이 있다고 생각됩니다.
프로젝트를 마무리하면서..
다른 일정으로 인해 프로젝트를 완전히 매듭 짓고 가지는 못하지만, 이번 프로젝트는 저에게 많은 것을 가르쳐주었습니다.
프로젝트를 만들면서 가장 좋았던 점은 제가 무엇을 모르는지 확실히 알게 되었다는 것입니다. 모르는 것들을 찾아보고 이해하고 코드로 적용도 해보는 시간이었습니다. 구체적으로는 다음의 내용들입니다.
- 자바와 스프링의 사용에 조금 더 익숙해졌습니다.
- 백엔드 애플리케이션의 레이어 간 역할과 책임을 코드를 통해, 그리고 레이어드 아키텍처와 DDD 개념을 통해 이해 해볼 수 있었습니다.
- 오버 엔지니어링과 적정 엔지니어링에 대해 고려할 수 있게 되었습니다.
- 확장(구현체 변경, 서버 스케일 아웃) 대비한 설계를 생각할 수 있게 되었습니다.
언젠가는 돌아와 이 프로젝트를 다시 작성해보리라 다짐하며, 글을 마칩니다.
참고
- “가상 면접 사례로 배우는 대규모 설계 시스템 기초” , 알렉스 쉬, 2021
