2.6. Probability - Dive into Deep Learning 0.17.2 documentation
Ch2 정리 코랩 공유폴더 링크
DiveToDeepLearning - Google Drive
- ch 2.1 ~ 2.6
model(X_train)의 작동 원리
요약 : 원하는 시점에서 특정한 동작을 발생시킬 수 있는 hook에 의해서 model(X_train)의 형태는 model.forward(X_train)을 호출한다.
#사용 예시
prediction = model(x_train)model(x_train)은 model.forward(X_train)과 동일함
> nn.Module.__call__
결과 : <function torch.nn.modules.module.Module._call_impl>__call__은 _call_impl의 별명 (as, alias)
실제 코드 from pytorch/torch/nn/modules/module.py link
__call__ : Callable[..., Any] = _call_impl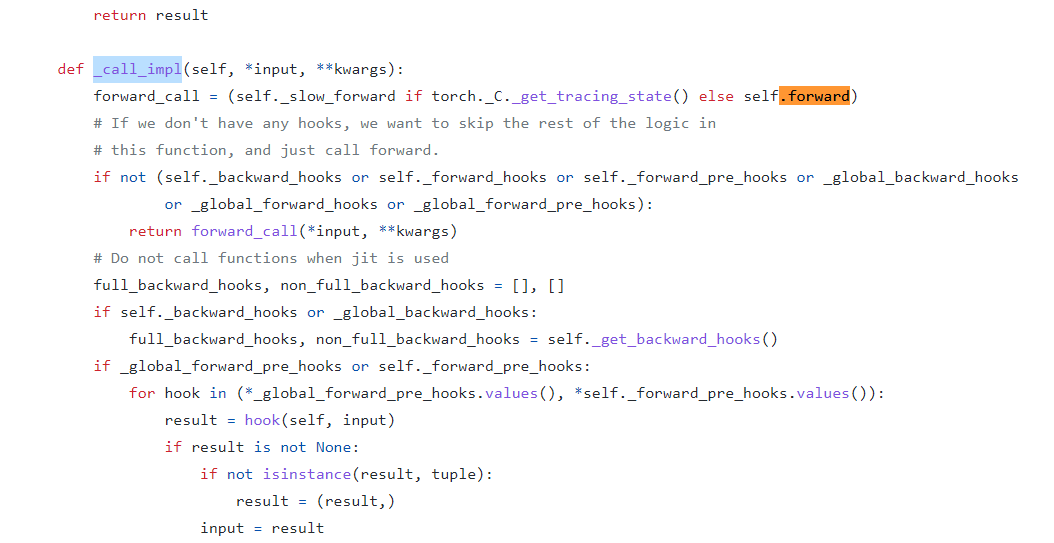
Model객체를 호출할 때
model = MyModel(X_train)
model(X_train)
- _call_impl()가 호출됨
implicit(암묵적인) call (호출) = 함수가 호출(call)되면 자동으로(암묵적으로) 실행되는 함수
hook과 관련된 친절한 설명
Forward Pre-hook → Forward → Forward Hook → Backward Hook 등록 (grad_fn)
처음 예제에서 보신 것처럼, Module 안에는 Sub-Module 들이 정의되고 순차적으로 call 이 호출되게 됩니다. 이때마다 위와 같은 로직이 실행되게 되는 것이죠.
- 31 Oct 2017, 이전버전의 파이토치에서는 call이 호출되었지만 최근 버전에서는 _call_impl이 호출됨
Ch2.1 데이터 조작
Can MXNet Stand Up To TensorFlow & PyTorch?
- 데코레이터 (@)
- @property
- @property , getter , setter
캡슐화
[코드잇] 쉽게 배우는 파이썬 문법 - 프로퍼티(Property) 2편
Ch2.2 데이터 전처리
pandas를 이용한 결측치 다루기
생략
Ch2.3 선형 대수
https://colab.research.google.com/drive/1UBA7gXF9jq2HXxca4H6reSgKXSOz6x91#scrollTo=PpmPsheI5wRS
Ch2.4 연쇄 법칙 (chain rule)
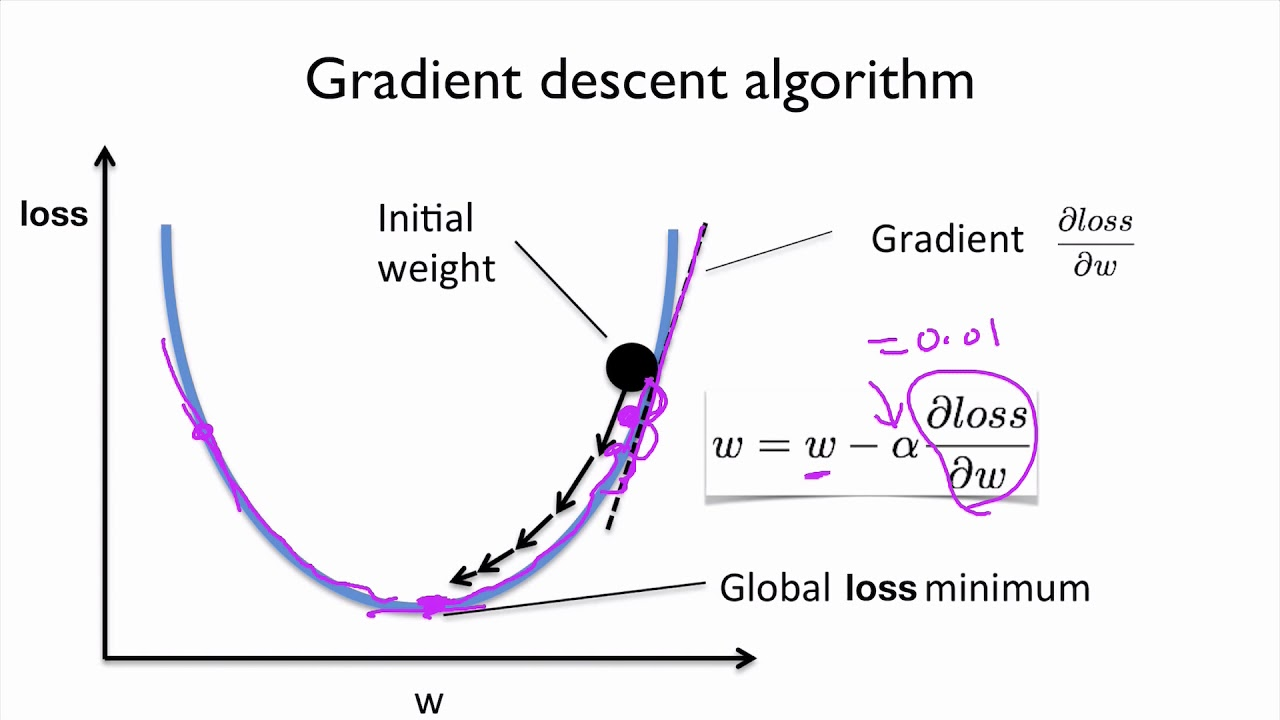
경사하강법
미분을 통해 오차(Loss)가 최소인 점을 찾는 방법
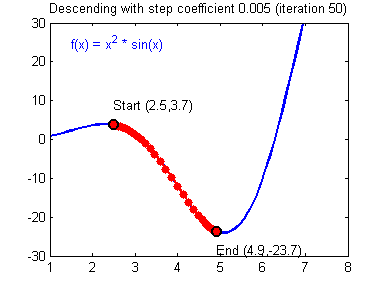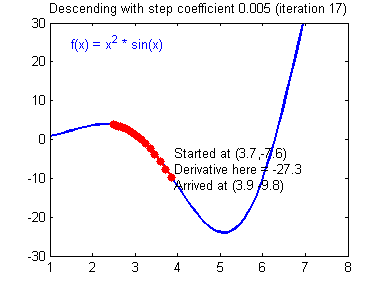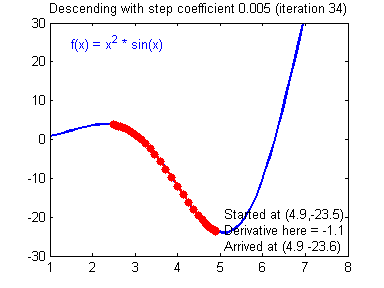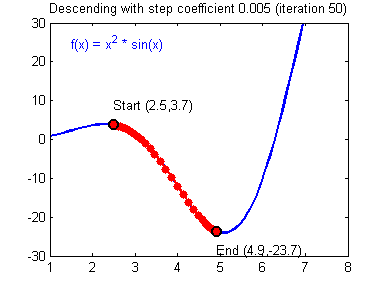
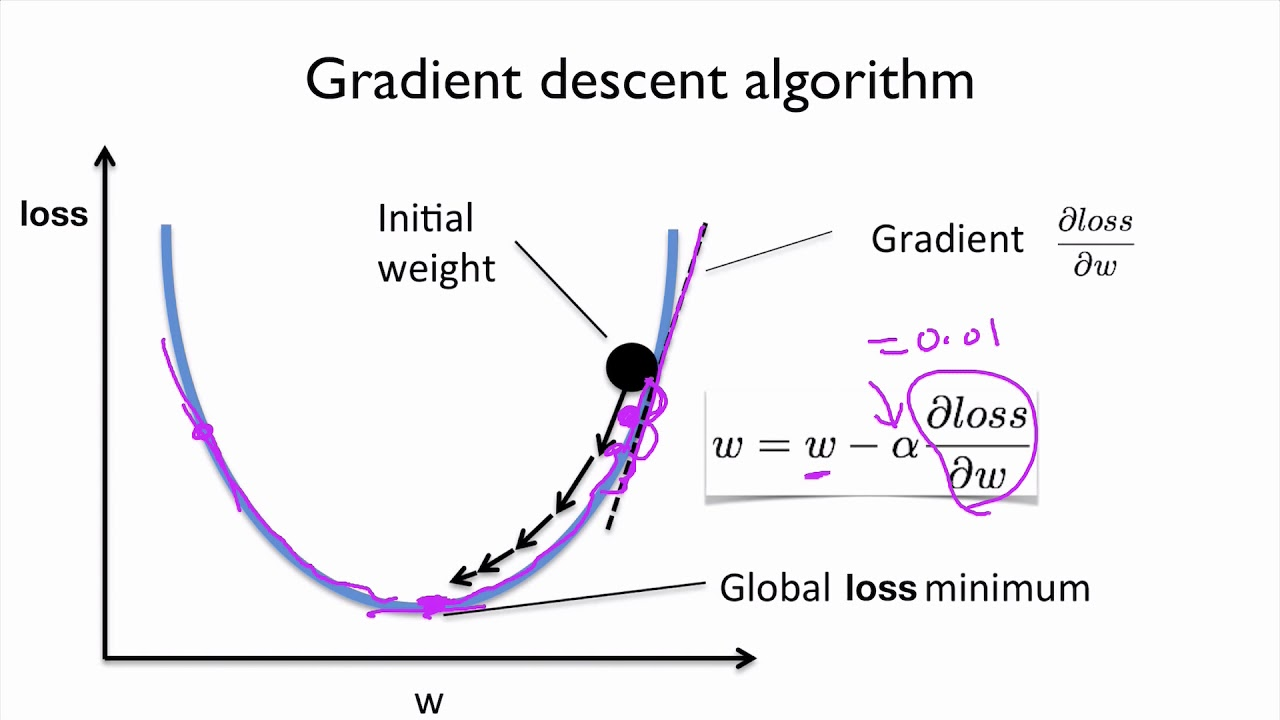
경사하강법의 효율성
- 편미분을 활용
- 갱신할 weigtht = up stream * local stream - 연산량 감소
- w1가 포함된 수식만 계산하면 w1를 갱신할 수 있음
- upstream은 공통 , local stream만 계산하면 w1의 loss에 대한 기여도(미분계수)를 구할 수 있음전체 오차(loss)에서 w_n의 기여량 = w_n의 기울기
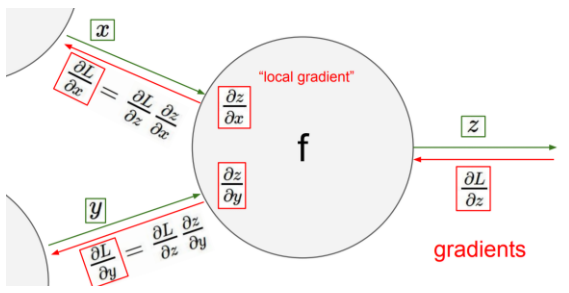
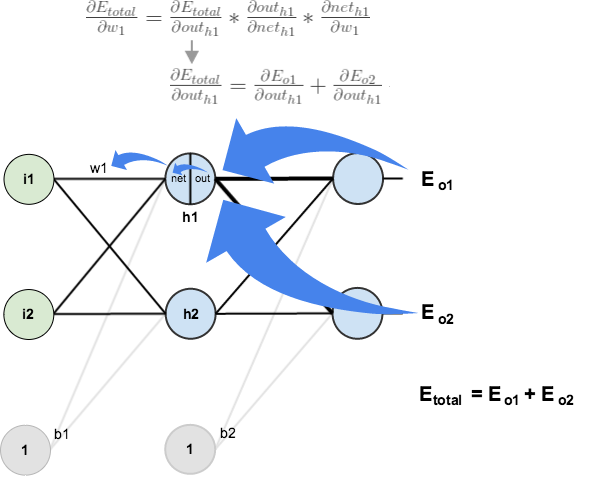
- upstream stream : output layer에서 input layer 방향으로 backward pass되는 gradient를 (위의 그림에서 gradients)
- output layer에 가까움 - local stream : output layer에서 z를 편미분 한 값(dz/dx, dz/dy) (위의 그림에서 local gradient)
- 같은 의미로 쓰로 쓰인다. stream = gradient
연산량 감소
Output 모두 반영해서 Loss
- Upstream : 출력값에 가까움
gradient =
upstreamgradient *localstreamgradient
- x의 가중치(계수 or 기울기)를 갱신하기 위해서 dL/dx을 구해야한다.
- x가 포함된, 영향을 미친 모든 노드를 계산
- 하지만 경사하강법을 진행하던 도중 Local minimum에 갇힐 가능성이 있다.
reference
Backpropagation 요약 (sigmoid 함수와 tanh 함수의 미분)
[모두를 위한 cs231n] - Lecture4. Backpropagation and Neural Network. 오차역전파에 대해서 알아보자😃
경사 하강법(Gradient Descent)의 문제점: Local Minimum 문제, Oscillation 문제
https://velog.io/@kjune1236/4%EA%B0%95-Backpropagation
Local minima problem
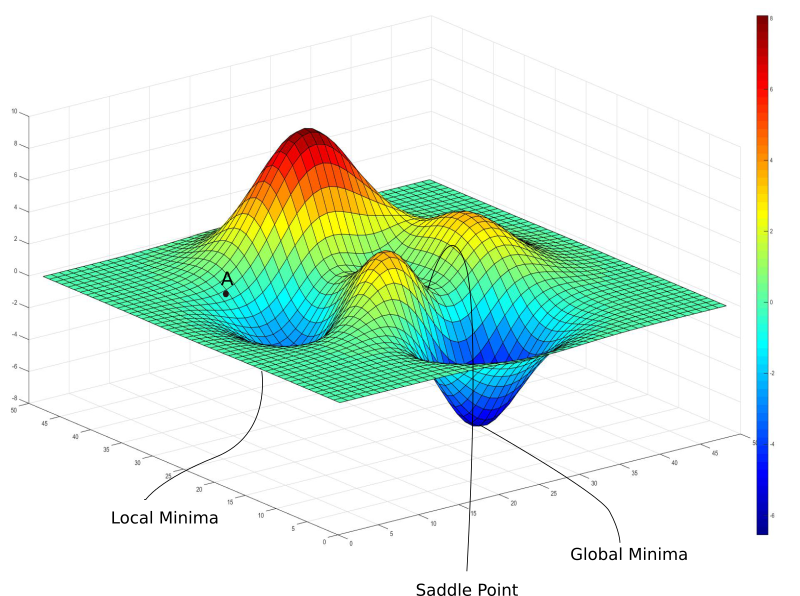
- weight를 업데이트 하던 도중 국소 최소점에 갖혀버리는 문제
- 어떻게 전체 최적점을 찾을 것인가
sol.1 : optimizer를 통해 해결
Ch2.5 자동 미분
Ch2.6 확률 (Probabliity)
확률(probability) : 특정 값이 존재하는 영역 또는
범위
- 학부 수준의 확률통계
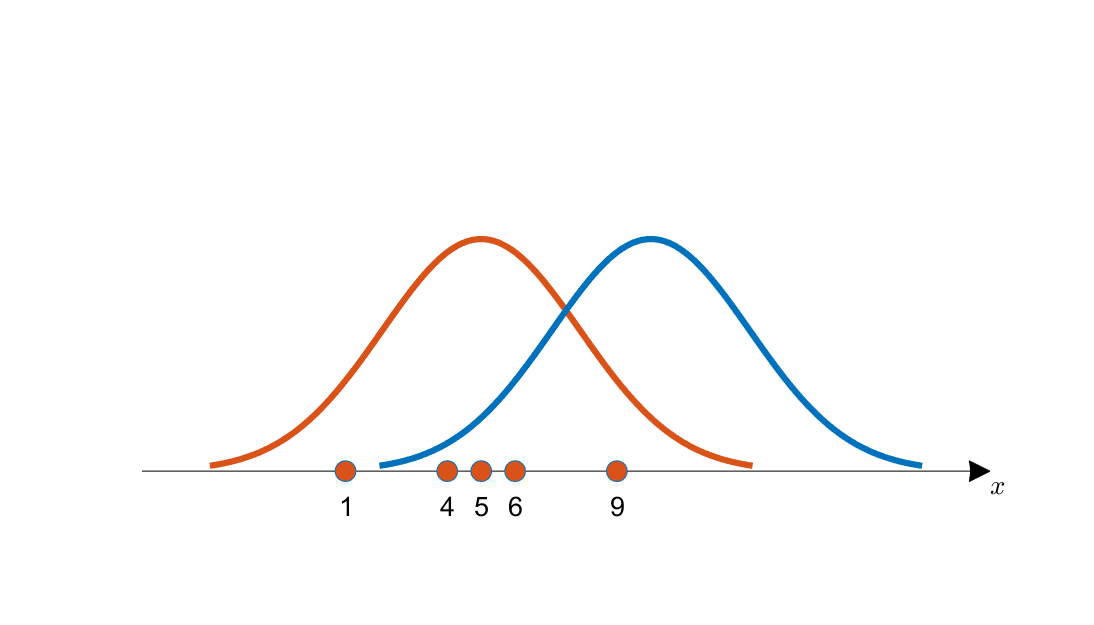
확률(probability)과 가능도(likelihood) 그리고 최대우도추정(likelihood maximization)
- 일반적으로 둘다 확률로 많이 쓰임. 심지어 전공책에서도!
가능도(Likelihood) : f(x)에서 x = a 일때의 값 f(a)
한 점 x에서의 f(x) 값
- 몸무게가 40 이상일 확률 = 확률
- 몸무게가 40 일 확률 = 가능도(==우도) 최대우도법(MLE)ㅡ 가장 중앙으로 밀집된 분포 선택 → 가장 그럴듯한 분포 선택
Ch2.7 Documentation
torch에서 help 명령어 사용법
import torch
print(dir(torch.distributions))
help(torch.ones)생략
