
가장 기본적인 자료구조다. 많은 자료구조는 Array, Linked List에서 시작한다.
1
배열은 같은 타입의 여러 변수를 하나의 묶음으로 쉽게 다루기 위해서 사용한다. 예를 들어 100개의 데이터를 저장하기 위해서 100개의 변수를 선언해야 한다면 매우 비효율적이다.
배열을 사용하면 다음과 같이 데이터를 묶음으로 관리할 수 있다.
student = 배열 생성
student[0] = 최진혁
student[1] = 한아람
student[2] = 최유빈
student[3] = 한이은
student[4] = 김주한배열은 마치 객차가 줄줄이 달린 열차와 비슷하다. 각 객차는 순서대로 번호가 있고 그 안에 데이터를 담을 수 있다. 각 객차를 요소(element)라고 하고 객차마다 가지고 있는 번호를 인덱스(index)라고 한다.
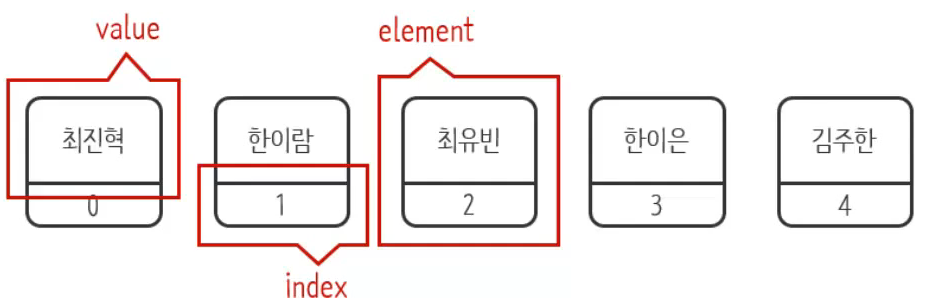
2
배열의 가장 큰 특징은 다음과 같다.
- 인덱스를 이용해서 요소에 빠르게 접근할 수 있다.
인덱스를 이용해서 요소에 빠르게 접근하려면 조건이 있다. 배열을 생성할 때 데이터의 타입과 길이를 선언해야 한다. 왜 그런지 조금 더 자세히 알아보자.
int[] arr = new int[5];
여기 길이는 5, 데이터 타입은 int(정수)인 배열 arr이 있다. int, 즉 정수형 자료 하나의 크기는 4byte로 메모리에서 4byte만큼 자리를 차지한다. 따라서 int[5]는 정수 자료형 5개가 순서대로 메모리(RAM)에 존재한다.
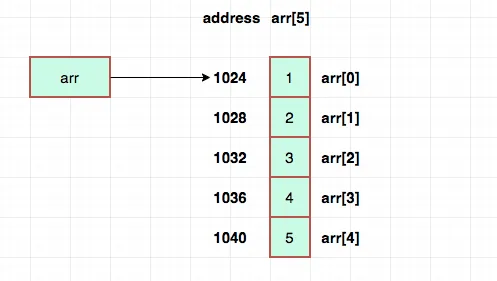
따라서 int[5]는 4byte짜리 공간 5개가 연속된 형태로 총 20byte만큼의 공간을 차지하게 된다. 그리고 arr이라는 변수는 배열의 시작 요소의 주소(1024)를 참조하고 있다.
이런 형태이기 때문에 인덱스를 이용해서 요소에 접근할 때는 아주 단순한 연산만 하면 된다.
만약 arr[2]에 접근하고 싶다면 2(인덱스) * 4(int 데이터 크기) + 1024(시작 주소) = 1032(주소) 이렇게 간단한 연산으로 해당 데이터의 주소를 알 수 있다. 배열의 크기가 얼마나 크든 상관없이 곱하기 한 번, 더하기 한 번이면 바로 주소를 알아낼 수 있다. 시간복잡도로 나타내면 O(1)이다.
이렇게 원하는 주소로 바로 접근하는 방식을 Random Access라고 한다.
3
이런 형태가 갖는 단점도 존재한다. 길이가 고정되어 있고 연속된 형태를 유지해야 하기 때문에 요소의 삽입/삭제는 효율이 상대적으로 떨어진다.
먼저 요소를 삽입하는 경우를 살펴본다. arr에는 [1,2,4,5] 4개의 요소가 들어있다. 2와 4사이에 3을 넣기 위해서는 먼저 3이 들어갈 공간을 만들기위해서 4와 5를 한 칸씩 뒤로 밀어야 한다. 그리고 빈 공간이 생기면 3을 넣는다. 이렇게 공간을 만들기 위해서 요소들을 뒤로 밀어줘야 한다. 만약 배열의 빈공간이 없는 경우는 더 큰 배열을 생성해서 요소를 복사해야 한 뒤, 요소를 추가해야 한다.
같은 맥락으로 삭제도 마찬가지다. 요소를 삭제하는 경우 빈공간을 채우기 위해서 요소들을 앞으로 당겨야한다. (배열 가장 뒤에 요소를 삽입/삭제할 때는 문제가 없다.) 요소가 많으면 많을 수록 해야 하는 연산도 늘어날 것이다. 시간복잡도로 나타내면 O(n)이다.
참고자료
