1. 벡터화란?
- 벡터화(Vectorization) : 자연어 처리에서는 전처리 과정에서 텍스트를 숫자 벡터로 변환
- 방법
- 통계와 머신 러닝을 활용한 방법
- 인공신경망을 활용하는 방법
2. 통계와 머신러닝을 활용한 방법
1) 단어 빈도를 이용
- Bag of Words(BoW)
- 문서 내의 단어들의 분포를 보고 이 문서의 특성을 파악하는 기법
- 단점 : 어순에 따라 달라지는 의미를 반영하지 못 함
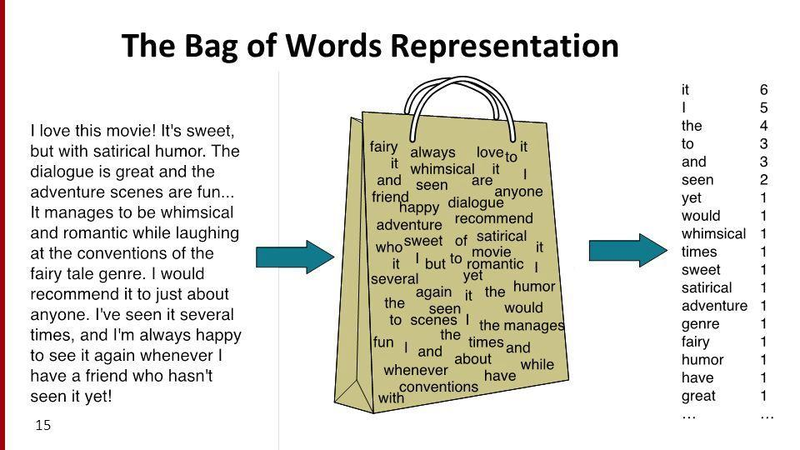
단어장(Vocabulary) : 중복을 제거한 단어들의 집합
- DTM(Document-Term Matrix; 문서-단어 행렬)
- 여러 문서(Corpus) 데이터의 Bag of Words를 하나의 행렬로 구현한 것
- 각 문서에 등장한 단어의 빈도수(frequency)를 하나의 행렬로 통합
- 행을 문서 벡터(document vector), 열은 단어 벡터(word vector)로 갖는 행렬
- 경우에 따라 열-문서, 행-단어로 하는 TDM(Term-Document Matrix)일때도 있다
- 한계점
- 희소 행렬 표현(Sparse Matrix Representation) : 높은 계산 복잡도와 저장공간 낭비
- 문서의 수가 많아지면 많아질수록, 통합 단어장의 크기도 커지게 되어서 DTM은 결국 문서 벡터와 단어 벡터 모두 대부분의 값이 0이 되는 성질을 갖는다 => 차원의 저주
- 단순 빈도수 기반 단어 표현 : 불용어의 빈도가 높다고 유사한 문장인가?
- TF_IDF(Term Frequency-Inverse Document Frequency; 단어 빈도-역문서 빈도)
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단하는 것
- 불용어처럼 중요도가 낮으면서 모든 문서에 등장하는 단어들이 노이즈가 되는 것을 완화해 줌
- : 각 문서에 등장하는 단어의 빈도(TF)
- : IDF
- N : 전체 문서의 수
- df : 문서 빈도

- LSA(Latent Semantic Analysis; 잠재 의미 분석)
- 전체 코퍼스에서 문서 속 단어들 사이의 관계를 찾아내는 자연어 처리 정보 검색 기술
- 문서의 집합에서 토픽을 찾아내는 프로세스
- 토픽 모델링(Topic Modelling)
- 단어와 단어 사이, 문서와 문서 사이, 단어와 문서 사이의 의미적 유사성 점수를 찾아냄
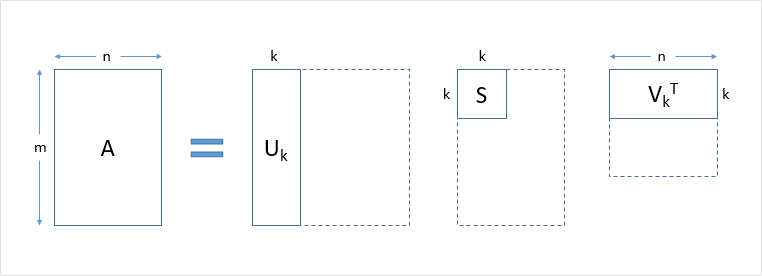
- DTM이나 TF-IDF 행렬 등에 Truncated SVD를 수행
- : 문서들과 관련된 의미들을 표현한 행렬
- : 단어들과 관련된 의미를 표현한 행렬 => 여기서 k열은 전체 코퍼스로부터 얻어낸 k개의 주요 주제(topic)
- : 각 의미의 중요도를 표현한 행렬
- : 하이퍼 파라미터
- : 문서의 수
- : 단어의 수
- DTM을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶음
- 전체 코퍼스에서 문서 속 단어들 사이의 관계를 찾아내는 자연어 처리 정보 검색 기술
용어
-
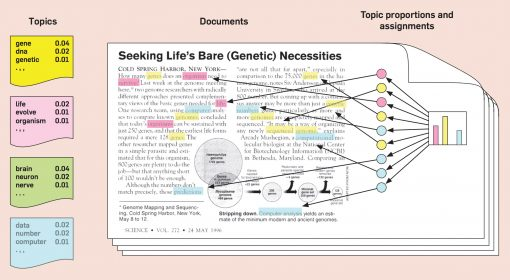
LDA(Latent Dirichlet Allocation; 잠재 디리클레 할당)
-
문서들이 토픽들의 혼합으로 구성되어 있으며, 토픽들은 확률 분포에 기반하여 단어들을 생성한다고 가정하여 단어들의 분포로 부터 문서가 생성되는 과정을 역추적해 문서의 토픽을 찾아냄
-
단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합 확률로 추정하여 토픽을 추출
-
2) 텍스트 분포를 이용(비지도학습)
-
soynlp
- 품사 태깅, 형태소 분석 등을 지원하는 한국어 형태소 분석기
- 비지도 학습으로 형태소 분석을 진행한다
- 데이터에 자주 등장하는 단어들을 형태소로 분석
- 내부적으로 단어 점수표로 동작
- 단어 점수표 : 응집 확률(cohesion probability) 과 브랜칭 엔트로피(branching entropy) 를 활용
-
soynlp의 응집 확률(cohesion probability)
- 내부 문자열(substring)이 얼마나 응집하여 자주 등장하는지를 판단하는 척도
- 값이 높을수록 전체 코퍼스에서 이 문자열 시퀀스는 하나의 단어로 등장할 가능성이 높다
식 예시 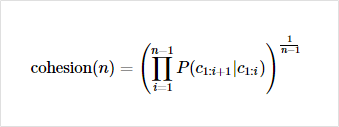

-
soynlp의 브랜칭 엔트로피(branching entropy)
- 확률 분포의 엔트로피값을 사용
- 주어진 문자열에서 다음 문자가 등장할 수 있는 가능성을 판단하는 척도
- 하나의 단어가 끝나면 그 경계 부분부터 다시 브랜칭 엔트로피값이 증가함
-
soynlp의 LTokenizer
- 찾아볼 것
-
최대 점수 토크나이저
- 띄어쓰기가 되어 있지 않은 문장에서 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저
