원하는 데이터를 더 쉽게: Subquery
하나의 SQL 쿼리 안에 또다른 SQL 쿼리가 있는 것을 의미합니다.
여러 번 듣는 것보다, 한 번 보는게 이해가 빠르겠죠? 바로 가보시죠!
- kakaopay로 결제한 유저들의 정보 보기 → 우선, 이렇게 볼 수 있겠죠?
users와orders의 inner join으로!
select u.user_id, u.name, u.email from users u
inner join orders o on u.user_id = o.user_id
where o.payment_method = 'kakaopay'- 그런데, 이것을 이렇게 할 수도 있습니다. 조금 더 직관적이지 않나요?
- 우선 kakaopay로 결제한 user_id를 모두 구해보기 →
K라고 합시다.
select user_id from orders
where payment_method = 'kakaopay'- 그 후에, user_id가
K에 있는 유저들만 골라보기
→ 이게 바로 서브쿼리!
select u.user_id, u.name, u.email from users u
where u.user_id in (
select user_id from orders
where payment_method = 'kakaopay'
)Subquery 본격 사용해보기
자주 쓰는 Subquery를 먼저 알아볼까요?
Subquery는 where, select, from 절에서 유용하게 사용될 수 있어요!
Where 에 들어가는 Subquery
Where은 조건문이죠? Subquery의 결과를 조건에 활용하는 방식으로 유용하게 사용합니다.
where 필드명 in (subquery) 이런 방식으로요!
- 예를 들면, 카카오페이로 결제한 주문건 유저들만, 유저 테이블에서 출력해주고 싶을 때는 아래와 같이 표현할 수 있겠죠.
select * from users u
where u.user_id in (select o.user_id from orders o
where o.payment_method = 'kakaopay');- 쿼리가 실행되는 순서를 이렇게 상상하면 편해요!
👉
(1) from 실행: users 데이터를 가져와줌
(2) Subquery 실행: 해당되는 user_id의 명단을 뽑아줌
(3) where .. in 절에서 subquery의 결과에 해당되는 'user_id의 명단' 조건으로 필터링 해줌
(4) 조건에 맞는 결과 출력
Select 에 들어가는 Subquery
Select는 결과를 출력해주는 부분이죠? 기존 테이블에 함께 보고싶은 통계 데이터를 손쉽게 붙이는 것에 사용합니다.
select 필드명, 필드명, (subquery) from .. 이렇게요!
- 앞서 보았던것처럼, '오늘의 다짐' 데이터를 보고 싶은데 '오늘의 다짐' 좋아요의 수가, 본인이 평소에 받았던 좋아요 수에 비해 얼마나 높고 낮은지가 궁금할 수 있겠죠?
- 그럼, 평균을 먼저 구해봅시다!
user_id='4b8a10e6'를 예시로!
select avg(likes) from checkins c2
where c2.user_id = '4b8a10e6'그러면, 이렇게 표현할 수 있어요!
select c.checkin_id, c.user_id, c.likes,
(select avg(likes) from checkins c2
where c2.user_id = c.user_id) as avg_like_user
from checkins c;- 쿼리가 실행되는 순서를 이렇게 상상하면 편해요!
👉
(1) 밖의 select * from 문에서 데이터를 한줄한줄 출력하는 과정에서
(2) select 안의 subquery가 매 데이터 한줄마다 실행되는데
(3) 그 데이터 한 줄의 user_id를 갖는 데이터의 평균 좋아요 값을 subquery에서 계산해서
(4) 함께 출력해준다!
From 에 들어가는 Subquery (가장 많이 사용되는 유형!)
From은 언제 사용하면 좋을까요? 내가 만든 Select와 이미 있는 테이블을 Join하고 싶을 때 사용하면 딱이겠죠!
- 자, 우선 유저 별 좋아요 평균을 먼저 구해볼까요? → checkins 테이블을 user_id로 group by 하면 되겠죠?
select user_id, round(avg(likes),1) as avg_like from checkins
group by user_id- 자, 이제 여기서 해당 유저 별 포인트를 보고 싶다면? → 그러면, 포인트와 like의 상관정도를 알 수 있겠죠?
select pu.user_id, a.avg_like, pu.point from point_users pu
inner join (
select user_id, round(avg(likes),1) as avg_like from checkins
group by user_id
) a on pu.user_id = a.user_id- 쿼리가 실행되는 순서를 이렇게 상상하면 편해요!
👉
(1) 먼저 서브쿼리의 select가 실행되고,
(2) 이것을 테이블처럼 여기고 밖의 select가 실행!
Subquery 연습해보기 (where, select)
- Where 절에 들어가는 Subquery 연습해보기
- [연습] 전체 유저의 포인트의 평균보다 큰 유저들의 데이터 추출하기
- [연습] 전체 유저의 포인트의 평균보다 큰 유저들의 데이터 추출하기
👉 포인트가 평균보다 많은 사람들의 데이터를 추출해보자!
*참고: 평균 포인트는 5380점
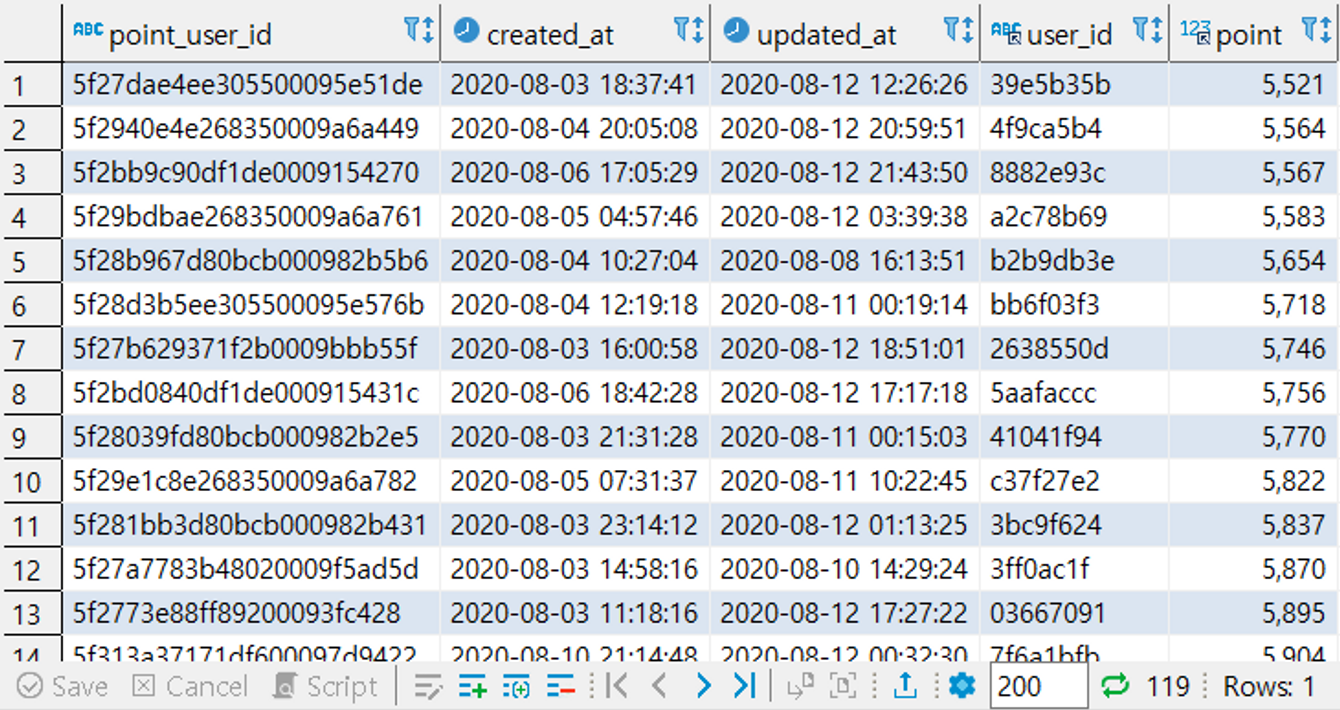
select * from point_users pu
where pu.point > (select avg(pu2.point) from point_users pu2);👉 이씨 성을 가진 유저들의 평균 포인트보다 더 많은 포인트를 가지고 있는 데이터를 추출해보자!
*참고: 이씨 성을 가진 유저들의 평균 포인트는 7454점

select * from point_users pu
where pu.point >
(select avg(pu2.point) from point_users pu2
inner join users u
on pu2.user_id = u.user_id
where u.name = "이**");Select 절에 들어가는 Subquery 연습해보기
👉 checkins 테이블에 course_id별 평균 likes수 필드 우측에 붙여보기
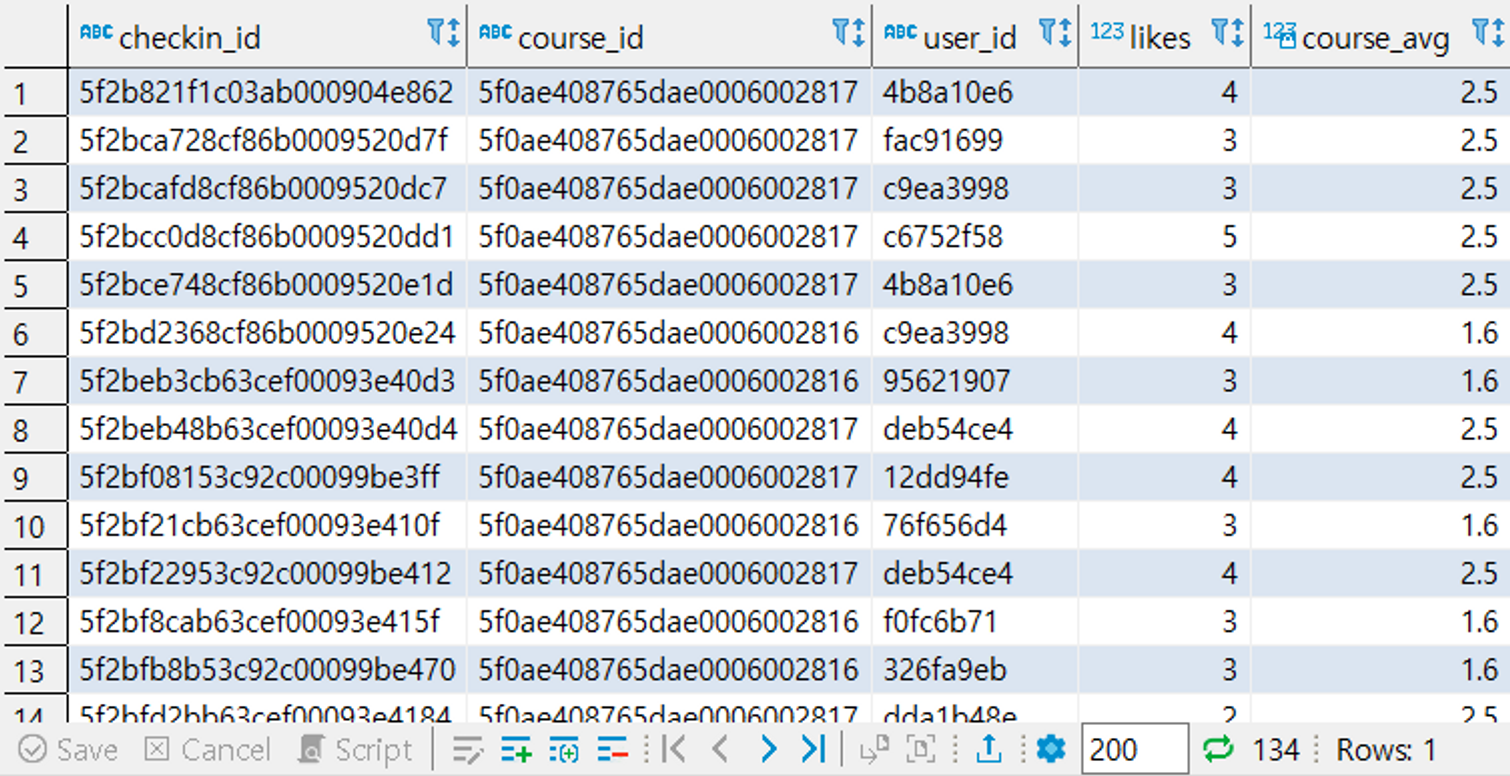
select checkin_id, course_id, user_id, likes,
(select avg(c2.likes) from checkins c2
where c.course_id = c2.course_id)
from checkins c;👉 checkins 테이블에 과목명별 평균 likes수 필드 우측에 붙여보기

select checkin_id, c3.title, user_id, likes,
(select round(avg(c2.likes),1) from checkins c2
where c.course_id = c2.course_id) as course_avg
from checkins c
inner join courses c3
on c.course_id = c3.course_id;From 절에 들어가는 Subquery 연습해보기
- course_id별 유저의 체크인 개수를 구해보기!
👉
checkins 테이블을 course_id로 group by 하면 되겠죠! 너무 쉽다!
그리고 distinct로 유저를 세면 되겠네요!
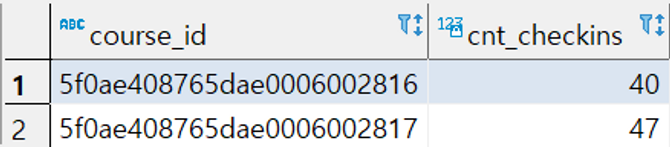
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_idwith절 연습하기
- 코스제목별 like 개수, 전체, 비율
select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from
(
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) a
inner join
(
select course_id, count(*) as cnt_total from orders
group by course_id
) b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_idwith table1 as (
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
), table2 as (
select course_id, count(*) as cnt_total from orders
group by course_id
)
select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from table1 a inner join table2 b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_id실전에서 유용한 SQL 문법 (문자열)
실제 업무에서는, 문자열 데이터를 원하는 형태로 한번 정리해야 하는 경우가 많습니다.
- 이메일에서 아이디만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', 1) from users- 이메일에서 이메일 도메인만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', -1) from users- orders 테이블에서 created_at을 날짜까지만 출력하게 해봅시다!
select order_no, created_at, substring(created_at,1,10) as date from orders- 일별 주문 숫자
select substring(created_at,1,10) as date, count(*) as cnt_date from orders
group by dateCASE: 경우에 따라 원하는 값을 새 필드에 출력해보기
- 10000점보다 높은 포인트를 가지고 있으면 '잘 하고 있어요!', 평균보다 낮으면 '조금 더 달려주세요!' 라고 표시해 주려면 어떻게 해야할까요?
select pu.point_user_id, pu.point,
case
when pu.point > 10000 then '잘 하고 있어요!'
else '조금 더 달려주세요!'
END as '구분'
from point_users pu;- CASE: 실전을 위한 트릭!
Subquery를 이용하면 이런 통계도 낼 수 있어요!
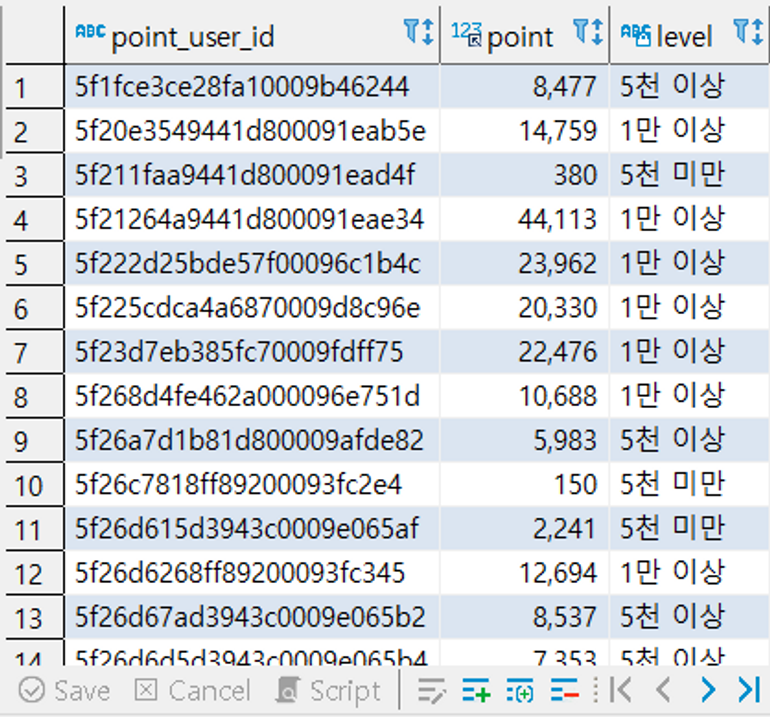
select pu.point_user_id, pu.point,
case
when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만'
END as level
from point_users pu서브쿼리를 이용해서 group by로 통계를 낼 수 있습니다.

select level, count(*) as cnt from (
select pu.point_user_id, pu.point,
case
when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만'
END as level
from point_users pu
) a
group by levelwith table1 as (
select pu.point_user_id, pu.point,
case
when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만'
END as level
from point_users pu
)
select level, count(*) as cnt from table1
group by level