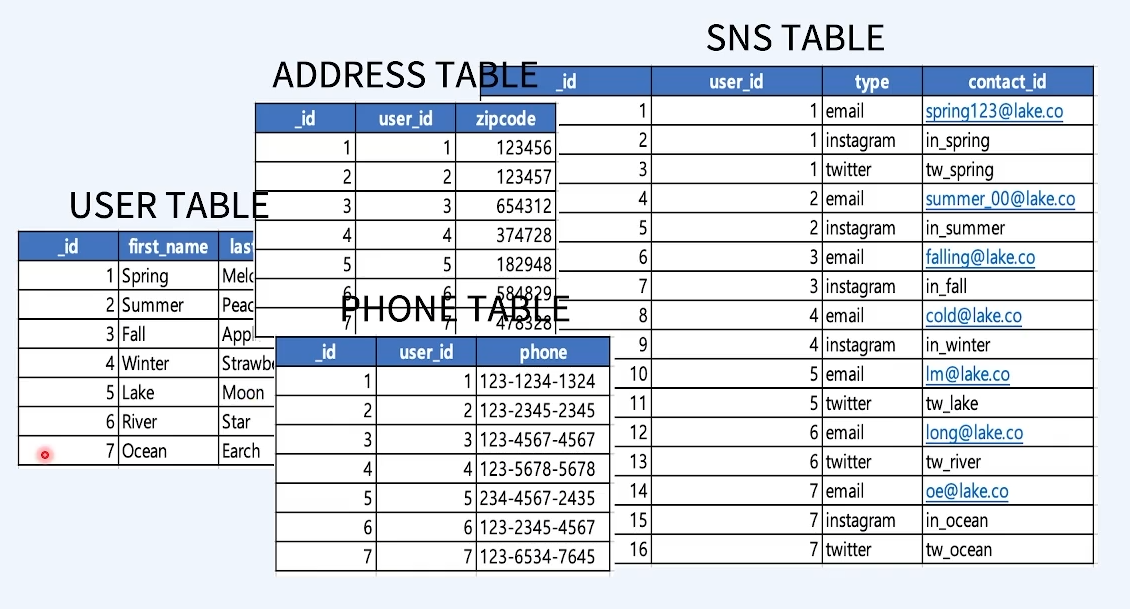
1. 구조
1) RDB의 장단점
-
데이터 중복을 방지할 수 있다.
-
Join의 성능이 좋다.
-
복잡하고 다양한 쿼리가 가능하다.
-
잘못된 입력을 방지할 수 있다.
-
하나의레코드 확인을 위해 여러 테이블을 조인하여 가시성이 덜어진다.
-
스키마가 엄격해서 변경에 대한 공수가 크다.
🥭Scaling 관점에서 보는 RDB
-
Scale-Out이 가능하지만, 설정이 어렵다.
-
확장할 때마다 Application단의 수정이 필요하다
-
전통적으로 Scale-Up 위주로 확장했다.
-
예전에는 디스크 스토리지가 매우 고가의 제품으로 데이터 중복을 줄이려고했다.
Scale-Out Scale-Up 어떻게 하드웨어 성능을 올리는것 서버 여러개로 데이터와 트래픽을 분산 성격 vertical horiznotal
2) 몽고디비 장단점
-
데이터 접근성과 가시성이 좋다.
-
Join 없이 조회가 가능해서 응답 속도가 일반적으로 빠르다.
-
스키마 변경에 공수가 적다.
-
스키마가 유연해서 데이터 모델을 App의 요구사항에 맞게 데이터를 수용할 수 있다.
-
데이터의 중복이 발생한다.
-
스키마가 자유롭지만, 스키마 설계를 잘해야 성능 저하를 피할 수 있다.
-
HA와 Sharding에 대한 솔루션을 자체적으로 지원하고 있어 Scale-Out이 간편하다.
-
확장 시, Application의 변경사항이 없다.
3. 요약
- mongoDb는 Document 지향 Database이다.
- 데이터 중복이 발생할 수 있지만, 접근성과 가시성이 좋다.
- 스키마 설계가 어렵지만, 스키마가 유연해서 Application의 요구사항에 맞게 데이터를 수용할 수 있다.
- 분산에 대한 솔루션을 자체적으로 지원해서 Scale-Out이 쉽다.
- 확장 시, Application을 변경하지 않아도 된다.
- MongoDB는 유연하고 확장성 높은 Opensource Document 지향 Database이다.
1. 구조
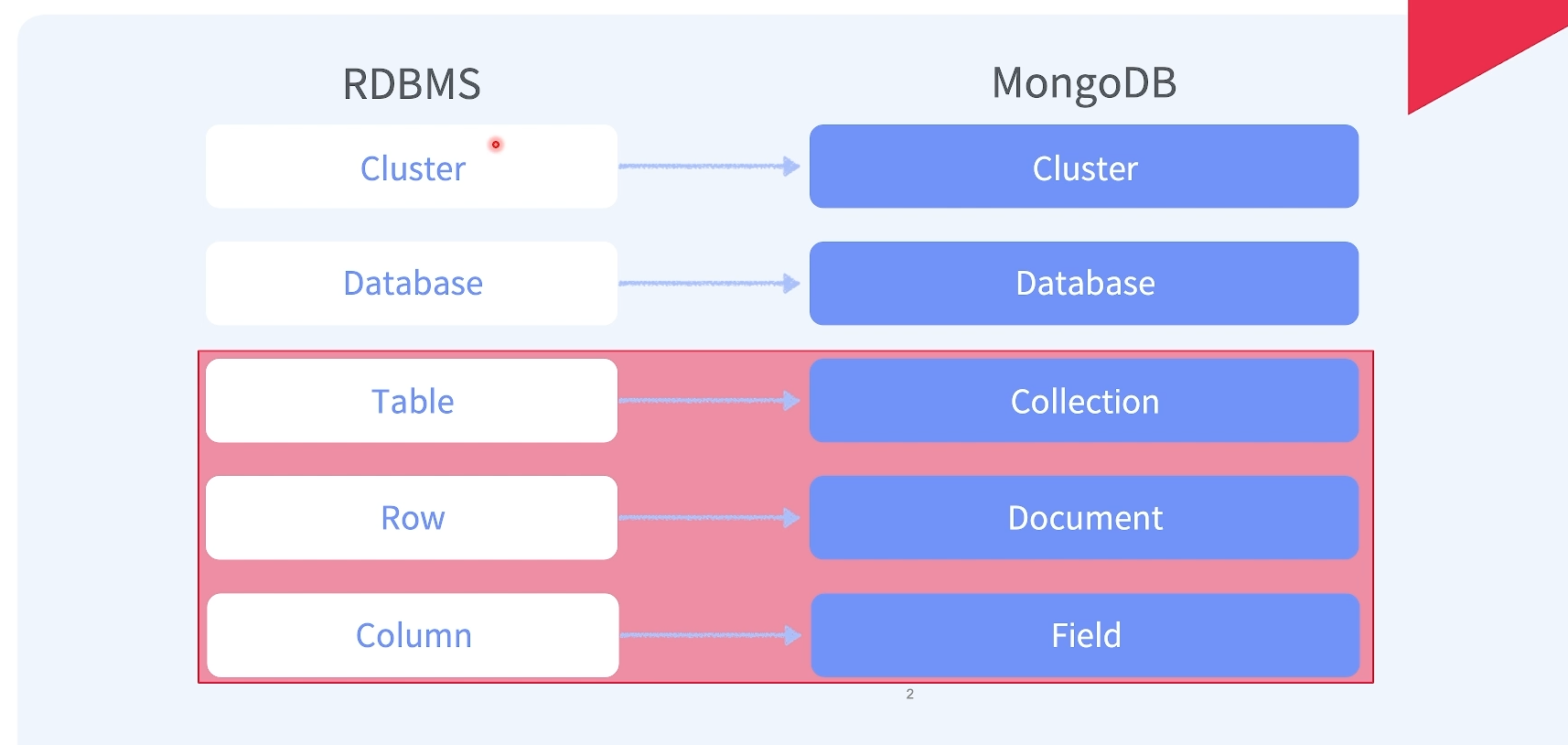

Collection 특징
-
동적 스키마를 갖고 있어서 스키마를 수정하려면 필드 값을 추가/수정/삭제하면 된다.
-
Collection 단위로 Index를 생성할 수 있다.
-
Collection 단위로 Shard를 나눌 수 있다.

-
데이터는 JSON 형식으로 표현하지만 저장할 때에는 BSON(Binary JSON)으로 한다.
-
모든 Document에는 "_id"필드가 있고, 없이 생성하면 ObjectId 타입의 고유한 값을 저장한다.
-
생성 시, 상위 구조인 Database나 Collection이 없다면 먼저 생성하고 Document를 생성한다.
-
Document의 최대 크기는 16MB이다.
MongoDB 배포 형태
1. 종류
1) Standalone

- 공부나 테스트 용도로밖에 사용하지 못한다.
2) Replica Set
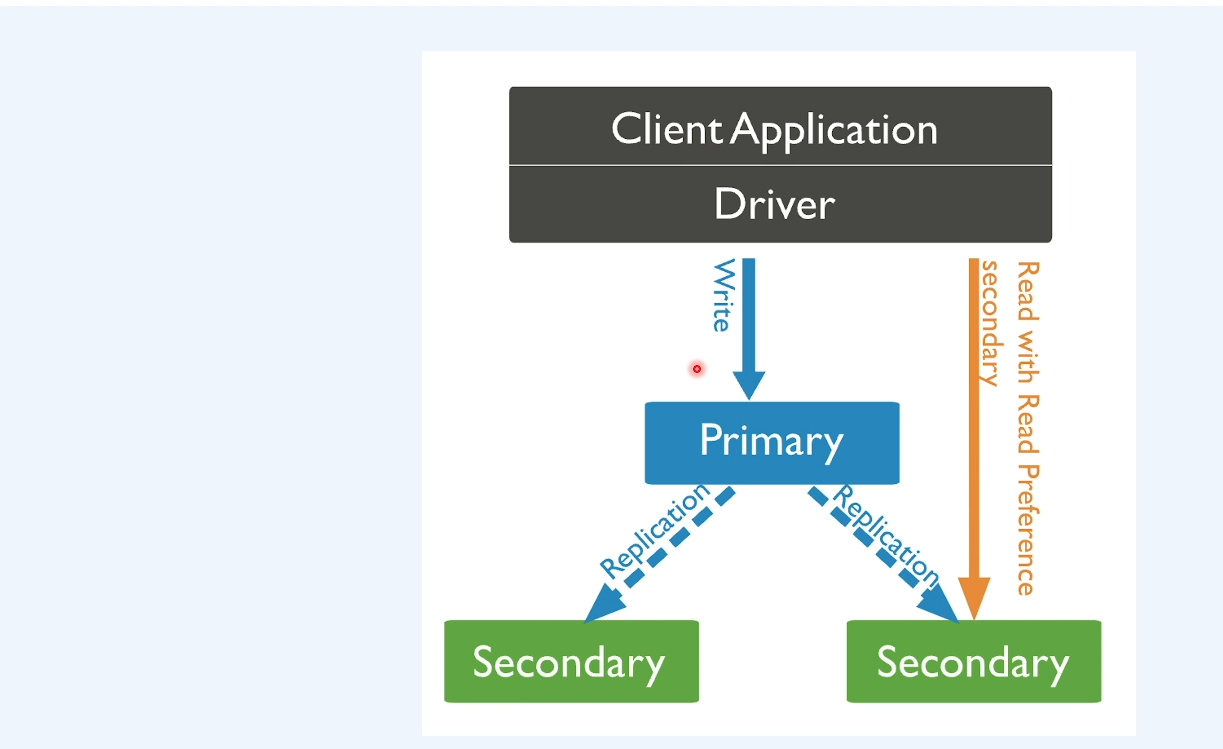
- HA(High Availability
3) Sharded Cluster
- HA(High Availability)
- Distribution
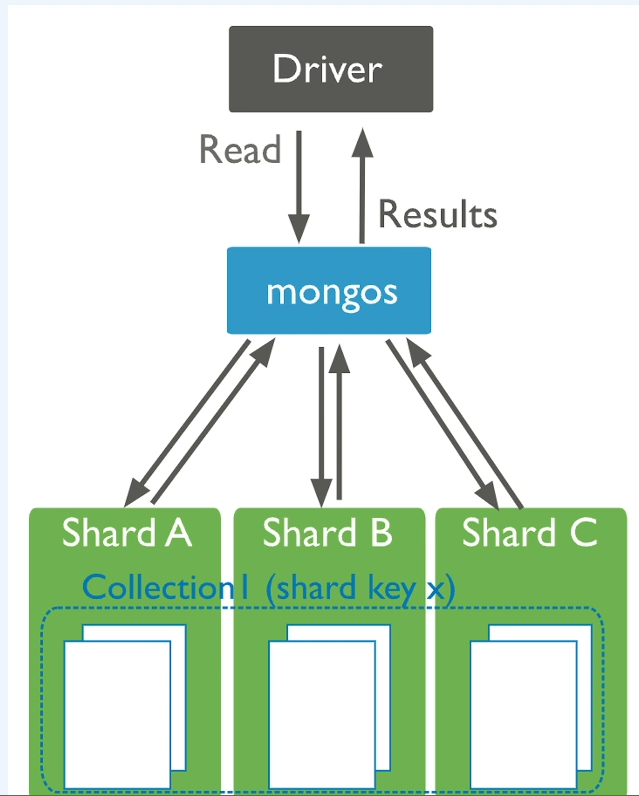
- Collection I 가 기존에는 Replica Set 하나에 모두 다 모여 있었다면 이것을 세 개의 Shard로 나눠서 데이터와 트래픽을 분산시켜주는 것이다.
