첫번째 풀이
def solution(k, score):
answer, ls = [], []
for i in score:
ls.append(i)
ls.sort(reverse=True)
if len(ls) > k:
ls.pop()
answer.append(ls[-1])
return answer
score를 순회하며 각 값을 추가하면서 정렬하고, 길이를 k에 맞게 유지해주며, 마지막 값을 answer에 추가해 반환한다. 잘 아시다시피 파이썬 리스트의 sort() 메서드는 의 시간 복잡도를 가진다.
두번째 풀이 - 삽입 정렬 활용
def insertion_sort(ls: list):
len_ls = len(ls)
# in-place
for idx, val in enumerate(ls[-2::-1]):
idx = len_ls - idx - 1
tmp_idx = idx
while idx < len_ls and val < ls[idx]:
ls[idx-1] = ls[idx]
idx += 1
if idx != tmp_idx:
ls[idx-1] = val
return ls
def solution(k, score):
answer, ls = [], []
for i in score:
ls.append(i)
# ls.sort(reverse=True) # 왜 이게 더 빠르지??
insertion_sort(ls)
if len(ls) > k:
ls.pop()
answer.append(ls[-1])
return answer
매번 정렬할 때, 거의 정렬된 ls에 원소 하나를 추가하여 다시 정렬한다는 점에 착안하여, 최선의 경우 시간복잡도 을 갖는 삽입 정렬을 in-place로 구현해 제출했다.
결과는?
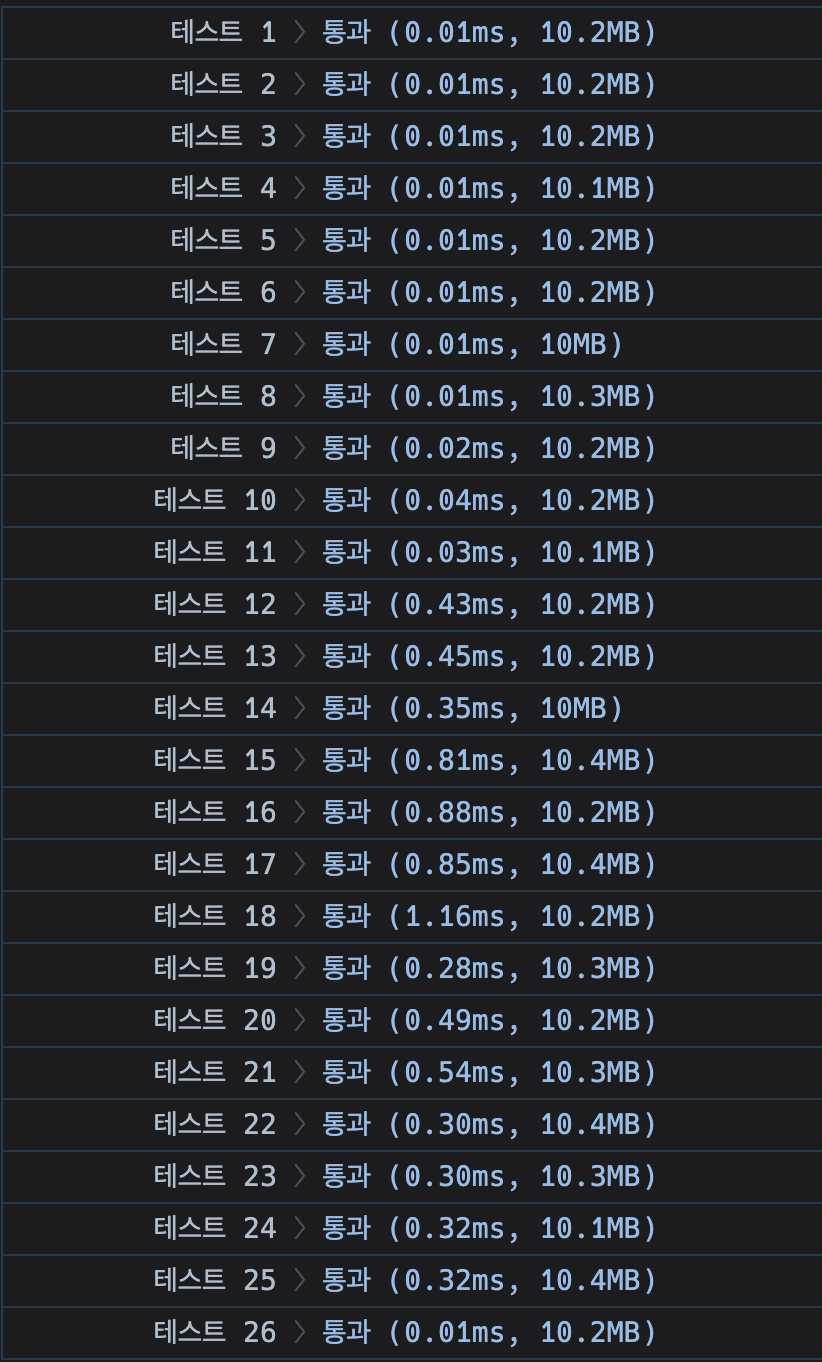
파이썬 리스트의 sort()메서드 사용
파이썬 코드로 구현한 삽입 정렬 사용
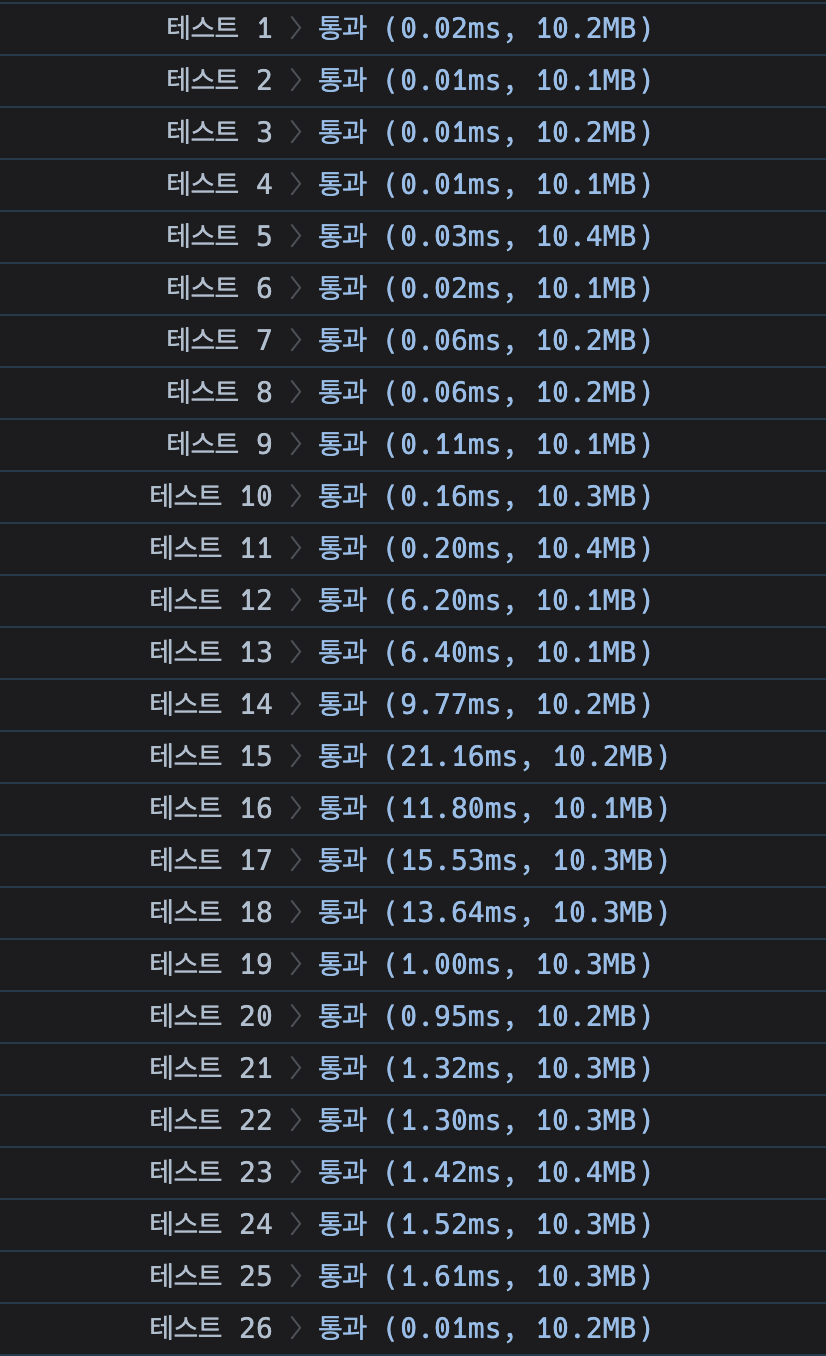
그냥 파이썬 리스트의 sort() 메서드를 사용하는게 더 빠르더라. 테스트 18에서 약 11배가량, 15에서 약 26배 가량 성능이 차이남을 확인할 수 있다. 왜 그럴까? 어떻게 구현되어있는지 어떻게 확인할 수 있을까?

이토록 멋진 휴식!