코드가 너무 느리다
혼신의 힘을 다 해 쓴 코드가 메모리를 108MB씩이나 잡아먹고, 5984ms씩 걸리더라. 다른 사람들의 코드에서 배우려고 눈을 돌렸는데 rkddus96님의 코드가 눈에 들어왔다.
m, n = map(int, input().split())
li = [False] + [True] * ((n - 1) // 2)
for x in range(1, int(n ** .5 / 2 + 1)):
if li[x]:
li[2*x*(x+1)::x*2+1] = [False] * ((((n + 1) // 2) - x * x * 2) // (x * 2 + 1))
if m <= 2:
print(2)
print('\n'.join([f'{x}' for x, val in zip(range(m+(m&1==0), n+1, 2), li[m//2:]) if val]))메모리 42.3MB, 시간 76ms.. 실로 엄청난 성능이다.
하지만 녀석은 쉽게 내게 잡혀주지 않았다. 오랜 시간 씨름한 끝에 이해했다고 생각한 것들을 이곳에 정리한다.
과정의 재구성
초기화
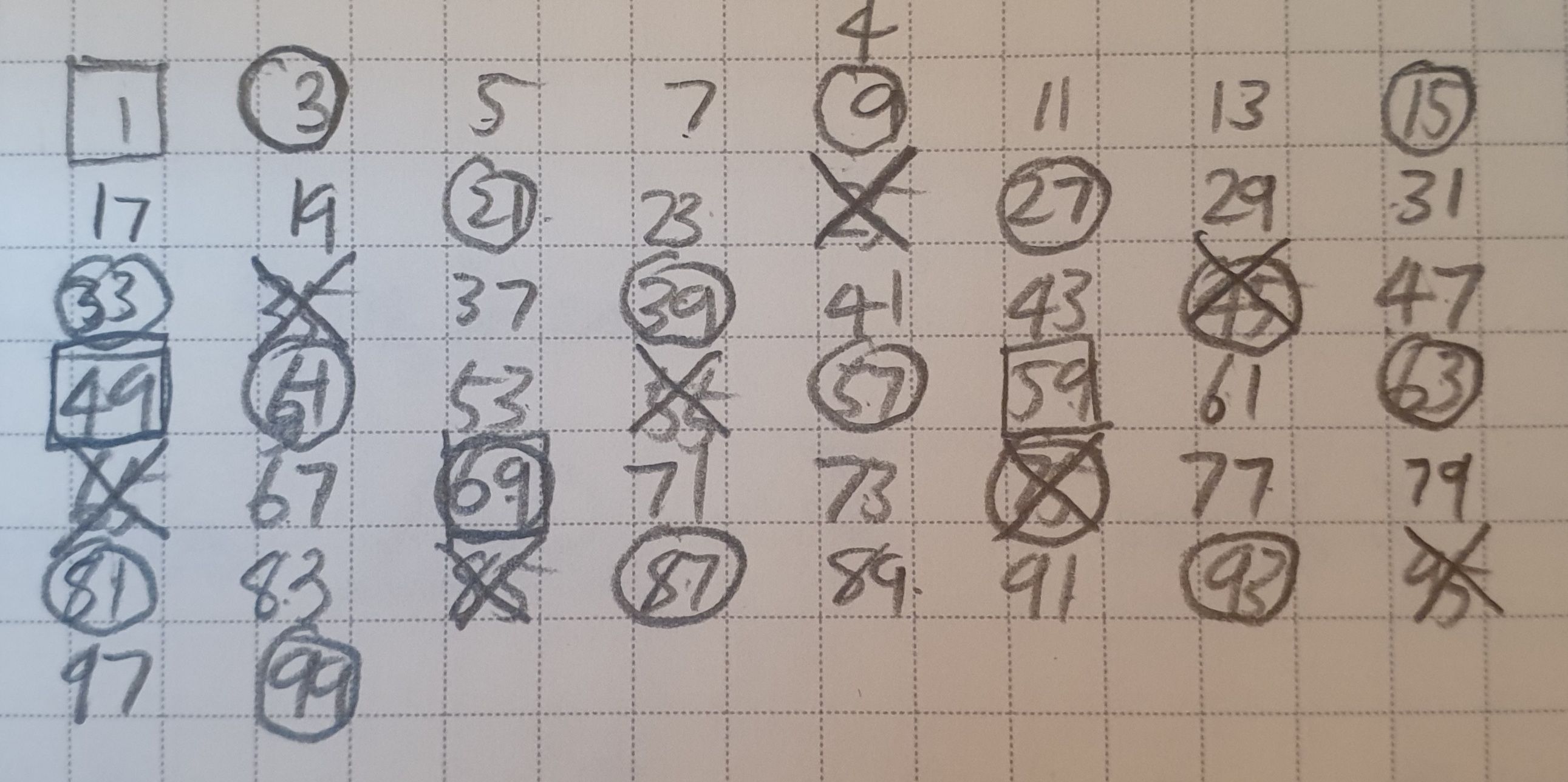
rkddus96님은 이 문제를 어떻게 접근한 걸까? 생각해보자. 2의 배수는 쉽게 걸러 낼 수 있다. 그리고 m과 n을 받았을 때, 어차피 2부터 계산해 나가야 한다. 그러니까 처음 리스트를 만들 때부터 짝수를 제외하자.
# 1. (내가 했던 방법)
ls = [2, *range(3, n + 1, 2)]
# 2. 나중에 2를 따로 print 한다면
ls = [*range(1, n + 1, 2)]
# 2-1. 또는 (rkddus96님의 방법과 유사)
ls = [0, *range(3, n + 1, 2)]
# 3. rkddus96님의 방법
ls = [False] + [True] * (n - 1) // 2
재구성하는 중이므로 변수명은 다르게 쓰도록 하겠다. 필자가 이 방법에서 가장 직관적이라고 생각하는 2-1번 방법을 사용해보자. n이 100일 때 ls는 0, 3, 5, ..., 99, 길이는 50, 101일 때 0, 3, ..., 101, 길이는 51이 된다. 일반화하면 (n + 1) // 2로 쓸 수 있다. 이 값은 나중에 중요해지니 기억해두도록 하자. 첫번째 값을 0으로 한 이유는 아래 조건문에서 첫번째를 그냥 지나가게 하기 위함이다. rkddus96님의 False와 기능이 같다.
반복문으로 연산
반복문의 조건
for x in range(1, int(n ** .5 / 2 + 1)):
if ls[x]:
이 반복문에서 x는 1부터 n의 제곱근을 2로나눈 값에 1을 더한 값을 정수로 한 값 이전까지이다. 에라스토네테스의 체를 사용했을 때 n의 제곱근까지만 확인해도 된다고 했는데, 왜 여기선 2로 나눌까? 처음에 나는 ls가 n의 반으로 줄었기 때문이라고 생각했다. 하지만 개수가 줄어든거지 큰 값들 자체가 반으로 줄어든게 아니다. 이유는 예를 들어서 설명할 수 있다. 먼저 0, 3, 5, 7, 9, 11, ... 에서 3의 배수를 확인한다고 하자. 원래대로라면 6, 9, 12, 15, ... 지만 짝수는 걸러진 만큼 3, 9, 15, ... 가 될 것이다. 3이 6으로 가지 않고 9로 바로 갈 수 있는 것이다. 건너뛰어야 되는 횟수가 반으로 줄어들었기 때문에 까지만 반복문을 수행해도 되는 것이다. 핵심을 짚으면, x는 인덱스를 가리키기 때문이라고 할 수 있을 것 같다. 여기서 x 값을 사용해 얼마나 건너뛰어야 하는지 결정하는 것을 보게 될 것이다. 어려운 개념일 수 있다. 하지만 잘 생각해보면 이해할 수 있을 것이다.
연산
ls[2*x*(x+1)::x*2+1] = [0] * ((((n + 1) // 2) - x * x * 2) // (x * 2 + 1))
이 부분도 바로 이해하기 어려운 부분이었다. 각 값을 찾아 그 값의 배수(또는 해당하는 값들)에 0이라는 값을 할당해주는 코드이다.
좌변
x | 2*x*(x+1) | x*2+1 | 해당하는 값 |
|---|---|---|---|
| 1 | 4 | 3 | 9에서 3칸씩 (6씩) |
| 2 | 12 | 5 | 25에서 5칸씩 (10씩) |
| 3 | 24 | 7 | 49에서 7칸씩 (14씩) |
좌변에서 중요한 값들이 이렇게 증가함을 볼 수 있다. ls를 슬라이싱하는 값들을 살펴보자. x가 1일 때 ls[x]의 값은 3이다. 3은 소수가 맞으니 남겨두고 3의 배수들을 찾아 0이라는 값으로 덮어쓸 것이다. 그런데 6은 초기화 과정에서 소거되었으니 9를 찾는다. 그리고 3칸씩 넘어가면서 0을 덮어쓴다. 위에서 봤듯이 6이 있었으면 길이가 2배가 되었을 것이다. 하지만 여기서는 9에서 3칸씩 넘어가면 12가 아닌 15, 18이 아닌 21로 성큼성큼 진행할 수 있다. 9부터 시작해 6씩 더해가며 0으로 덮어쓴다.
5의 경우도 마찬가지다. 25에서 시작해 5칸씩, 즉 10씩 증가하면서 0으로 덮어쓴다. 7도 49부터 7칸씩, 즉 14씩 증가하면서 덮어쓴다.
3일때 9, 5일때 25, 7일 때 49... 왜 제곱수부터 시작하는걸까? 제곱하여 시작하는게 아니라 그 수들이 가능한 첫번째 배수인 것이다. 3의 2배수는 2의 배수에서 소거되었고, 5의 2, 3, 4배수 또한 소거되었으니 5배수부터, 7도 마찬가지로 7배수부터 소거를 시작한다.
"2*x*(x+1)"와 "2*x+1"에 대하여
그러면 각 수 ls[x]에 대해 ls[x]**2라는 값을 가리키는 인덱스와 어떻게 매칭시킬 수 있을까?
x가 1씩 증가하고 있다. x는 각 값을 가리키는 인덱스인데, 그 값들을 라 하자.
| 1 | 3 |
| 2 | 5 |
| 3 | 7 |
| 4 | 9 |
| 5 | 11 |
| 6 | 13 |
| 7 | 15 |
| 8 | 17 |
| ... | ... |
규칙을 발견했는가?
여기서 우리는 이라는 값과 그 인덱스 의 관계 또한 임을 알 수 있다. 그러므로...
라는 식을 세울 수 있다. 이 식을 풀어 각 수에 대해 제곱이 되는 수 의 인덱스를 로 나타내면
가 된다. 그렇게 ls[2*x*(x+1)::2*x+1]로 각 수를 가리키는 x를 사용해 각 수의 제곱부터 각 수의 배로 늘려나가며 0으로 덮어쓸 수 있게 되는 것이다.
우변
우변은 ls[2*x*(x+1)::2*x+1]의 길이에 [0]을 곱해주면 된다. len()함수 또한 시간복잡도 이므로 상황에 맞게 사용할 수 있으나 슬라이싱하는데 드는 시간을 줄이기 위해, 그리고 가능하기 때문에 이미 주어진 변수들을 활용해 계산한 것 같다(BOJ기준 아주 약간 느려진다 104ms -> 108ms). 개수가 맞지 않으면 ValueError가 발생한다.
먼저 위에서 봤듯이 ls의 총 길이는 n까지의 홀수를 모두 포함할 수 있는 길이여야 한다. 예를 들어 101일때 51, 100일때 50이다. rkddus96님의 코드에선 li의 맨 앞에 [False]가 있으니 [True]에 (n + 1) // 2 - 1, 즉 (n - 1) // 2를 곱했고, 총 길이는 1을 더한 수가 된다. 그러면 그 수들 중에서 부터 씩 건너뛰는 리스트는 길이가 얼마나 될까?
n을 100이라 할 때, len(ls[4:])는 이다. 3개씩 건너뛴다면(len(ls[4::3])) 16이다.
>>> len(ls[12:])
38
>>> len(ls[12::5])
8여기서 슬라이스된 리스트의 길이는 , 라 할때, ls의 전체 길이에서 를 뺀 수보다 가장 가까운 같거나 큰 의 배수를 로 나눈 값이라는 규칙을 알아낼 수 있었다. (, ) 이를 공식으로 나타내보자.
ls의 전체 길이는 1+(n-1)//2이고 분배법칙으로 (2+n-1)//2, 즉 (n+1)//2라 쓸 수 있다. 를 빼고 을 더하면 (n+1)//2 - 2*x*x+1이 된다. 다시 을 나누면 ((n+1)//2 - 2*x*x+1)//(2*x+1).
하지만 이대로라면 '1 103'과 같은 입력에서 ValueError가 날 것이다. 전체 길이에서 를 뺀 값보다 같거나 큰 의 배수로 조정할 때 을 다 더해버리면 전체 길이에서 를 뺀 값이 이미 의 배수일 때, 로 나눈 몫이 1만큼 더 증가한다. 이를 방지하기 위해 분자에 1을 뺀다 (또는 을 더하는 시점에서 대신 을 더한다).
((n+1)//2 - 2*x*x)//(2*x+1)
또는 math 라이브러리의 ceil() 함수를 사용해 을 더하지 않고 아래와 같이 계산할 수 있다.
ceil(((n+1)//2-(2*x*x+2*x))/(2*x+1))(나누기 연산에 주의)
ceil()함수는 어떤 값의 가장 가까운 같거나 큰 정수로 올림하는 함수이다.
위와 같이 우변에 대한 설명을 마친다.
출력
if m <= 2:
print(2)
# rkddus96님의 코드
print('\n'.join([f'{x}' for x, val in zip(range(m+(m&1==0), n+1, 2), ls[m//2:]) if val]))
# 조정된 코드
print('\n'.join([f'{val}' for val in ls[m//2:]) if val]))만약 m이 2보다 같거나 작다면, ls는 그것을 나타낼 수 없기 때문에 하드코딩으로 출력한다. (ls의 첫번째 값을 0으로 했다.)
zip(range(m+(m&1==0), n+1, 2), ls[m//2:])
m + (m & 1 == 0):&연산자는 각 비트 단위에 대해 AND연산을 수행한다.ls[m//2:]:m이 3일 때 1부터 (3을 가리키는 인덱스), 4 또는 5일때 2부터 (5를 가리키는 인덱스), 이런식으로 m을 포함하는 홀수부터 출력될 수 있도록 리스트를 슬라이스 한다.
즉 m&1==0은 m%2==0과 같다. 따라서 m이 짝수라면 m+1부터, 홀수라면 m부터 n까지 2씩 증가하는 range객체와 ls[m//2:]를 묶어서 튜플로 반환해 순회한다. 만약 ls[m//2:]의 값(val)이 0이 아니라면(소수가 아닌 수에 대해 0으로 덮어썼다. 즉 val이 소수라면) 해당하는 range에서 나온 값을 문자열로 변환한 리스트를 사이에 공백문자를 두어 출력한다.
rkddus96님은 ls를 True, False값으로 초기화했기 때문에 zip함수를 사용하나 여기서는 값들 그 자체로 초기화했기 때문에 위와 같이 조정하여 바로 val 값을 출력할 수 있다.
완성된 코드
from math import ceil
m, n = map(int, input().split())
ls = [0, *range(3, n + 1, 2)]
for x in range(1, int(n ** .5 / 2 + 1)):
if ls[x]:
ls[2*x*(x+1)::x*2+1] = [0] * ceil(((n+1)//2-(2*x*x+2*x))/(2*x+1))
if m <= 2:
print(2)
print('\n'.join([f'{val}' for val in ls[m//2:] if val]))백준온라인저지 기준 메모리 61MB, 시간 104ms로 원래 코드보다 훨씬 빨라졌다. 가능한 비효율의 원인을 짚어보자면,
-
ls를 초기화 할 때range를 순회하는데서, -
정수를
ls에 저장하는데서?sys.getsizeof(True) # 28sys.getsizeof(1) # 28sys.getsizeof(10**6) # 28
-
ceil()함수를 사용하는데서 (사용하지 않을 때 메모리 59MB)
사실 3번을 제외한 나머지는 확실하지 않고, 어떻게 확인해야할지도 아직은 모르겠다. 실력이 어느정도 늘고 나면 다시 돌아봐야겠다.
마치면서
고된 작업이었지만 보람 있었다.
