1. 구글 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive')2. 이미지 데이터 로드
데이터 불러와서 히스토그램 그리는 부분까지는 저번에 한 과정과 같다.
import os
import shutil
import glob
import cv2
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.applications import *
from tensorflow.keras.callbacks import *
from tensorflow.keras.initializers import *
from tensorflow.keras.preprocessing.image import ImageDataGenerator
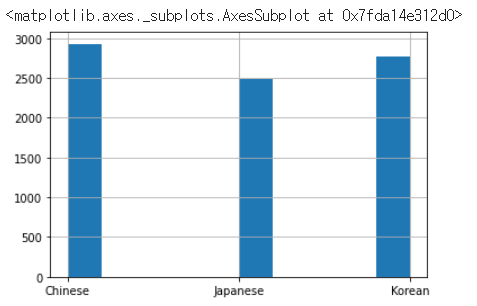
Path = "./drive/MyDrive/Colab Notebooks/datasets/Dishes/"
cuisines = ['Chinese', 'Japanese', 'Korean']
images = []
label = []
for dish in cuisines:
#print(os.path.exists('/content/drive'))
food = os.listdir(Path+dish)
for i in food:
images.append(dish+'_'+i)
label.append(dish)
df = pd.DataFrame(list(zip(images, label)), columns=['Image', 'Cuisine'])
df.Cuisine.unique()
df.Cuisine.hist()결과:
3. 훈련 데이터, 검증 데이터 생성
# Augment data
batch_size = 64
train_input_shape = (224, 224, 3)
n_classes = 3
train_datagen = ImageDataGenerator(validation_split=0.2,
rescale=1./255.,
rotation_range=15,
shear_range=0.1,
zoom_range=0.5
)
train_generator = train_datagen.flow_from_directory(directory=Path,
class_mode='categorical',
target_size=train_input_shape[0:2],
batch_size=batch_size,
subset="training",
shuffle=True,
classes=df.Cuisine.unique().tolist()
)
valid_generator = train_datagen.flow_from_directory(directory=Path,
class_mode='categorical',
target_size=train_input_shape[0:2],
batch_size=batch_size,
subset="validation",
shuffle=True,
classes=df.Cuisine.unique().tolist()
)
STEP_SIZE_TRAIN = train_generator.n//train_generator.batch_size
STEP_SIZE_VALID = valid_generator.n//valid_generator.batch_sizeImageDataGenerator를 사용할 경우 여러 함수를 통해 이미지 로드 및 이미지 증식을 할 수 있다. 파라미터 설정을 통해 이미지 증식 방식에 대해 정해줄 수 있다.
flow_from_directory는 이미지를 불러올 때 폴더명에 맞춰 자동으로 labelling을 해준다. flow_from_directory() 함수의 주요 파라미터는 다음과 같다.
첫번재 파라미터 : 이미지 경로.
target_size : 패치 이미지 크기. 폴더에 있는 원본 이미지 크기가 다르더라도 target_size에 지정된 크기로 자동 조절됨.
batch_size : 배치 크기.
class_mode : 분류 방식.
categorical : 2D one-hot 부호화된 라벨이 반환됨.
binary : 1D 이진 라벨이 반환됨.
sparse : 1D 정수 라벨이 반환됨.
None : 라벨이 반환되지 않는다.
본 실습에서는 이미지 크기를 224 x 224로 하였으니 target_size도 (224, 224)로 설정하였다. 다중 클래스 문제이므로 class_mode는 ‘categorical’로 지정하였다. 그리고 제네레이터는 훈련용과 검증용으로 두 개를 만들었다.
4. imagenet에 사전 훈련된 모델 ResNet 50 사용하기
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=train_input_shape)
for layer in base_model.layers:
layer.trainable = True
X = base_model.output
X = Flatten()(X)
X = Dense(512, kernel_initializer='he_uniform')(X)
X = Dropout(0.4)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Dense(128, kernel_initializer='he_uniform')(X)
X = Dropout(0.4)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Dense(16, kernel_initializer='he_uniform')(X)
X = Dropout(0.4)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
output = Dense(n_classes, activation='softmax')(X)
model = Model(inputs=base_model.input, outputs=output)Adam을 이용하여 최적화한다.
optimizer = Adam(lr=0.00001)
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])5. 모델 훈련시키기
가중치 고정..
한 번 더 훈련시킴.
n_epoch = 50
early_stop = EarlyStopping(monitor='val_loss', patience=20, verbose=1,
mode='auto', restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=5,
verbose=1, mode='auto')
# Train the model - all layers
history1 = model.fit_generator(generator=train_generator, steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator, validation_steps=STEP_SIZE_VALID,
epochs=n_epoch,
shuffle=True,
verbose=1,
callbacks=[reduce_lr],
use_multiprocessing=False,
workers=4
)
# Freeze core ResNet layers and train again
for layer in model.layers[-6:]:
layer.trainable = False
for layer in model.layers:
layer.trainable = True
optimizer = Adam(lr=0.00001)
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])결과:

n_epoch = 50
history2 = model.fit_generator(generator=train_generator, steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator, validation_steps=STEP_SIZE_VALID,
epochs=n_epoch,
shuffle=True,
verbose=1,
callbacks=[reduce_lr, early_stop],
use_multiprocessing=False,
workers=4
)결과:

# Merge history1 and history2
history = {}
history['loss'] = history1.history['loss'] + history2.history['loss']
history['acc'] = history1.history['accuracy'] + history2.history['accuracy']
history['val_loss'] = history1.history['val_loss'] + history2.history['val_loss']
history['val_acc'] = history1.history['val_accuracy'] + history2.history['val_accuracy']
history['lr'] = history1.history['lr'] + history2.history['lr']6. 훈련 그래프 그리기
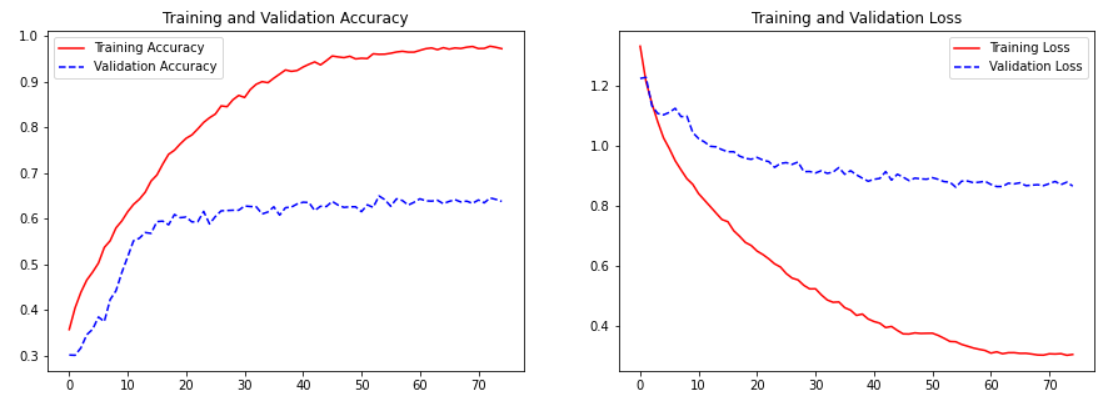
# Plot the training graph
import matplotlib.pyplot as plt
def plot_training(history):
acc = history['acc']
val_acc = history['val_acc']
loss = history['loss']
val_loss = history['val_loss']
epochs = range(len(acc))
fig, axes = plt.subplots(1, 2, figsize=(15,5))
axes[0].plot(epochs, acc, 'r-', label='Training Accuracy')
axes[0].plot(epochs, val_acc, 'b--', label='Validation Accuracy')
axes[0].set_title('Training and Validation Accuracy')
axes[0].legend(loc='best')
axes[1].plot(epochs, loss, 'r-', label='Training Loss')
axes[1].plot(epochs, val_loss, 'b--', label='Validation Loss')
axes[1].set_title('Training and Validation Loss')
axes[1].legend(loc='best')
plt.show()
plot_training(history)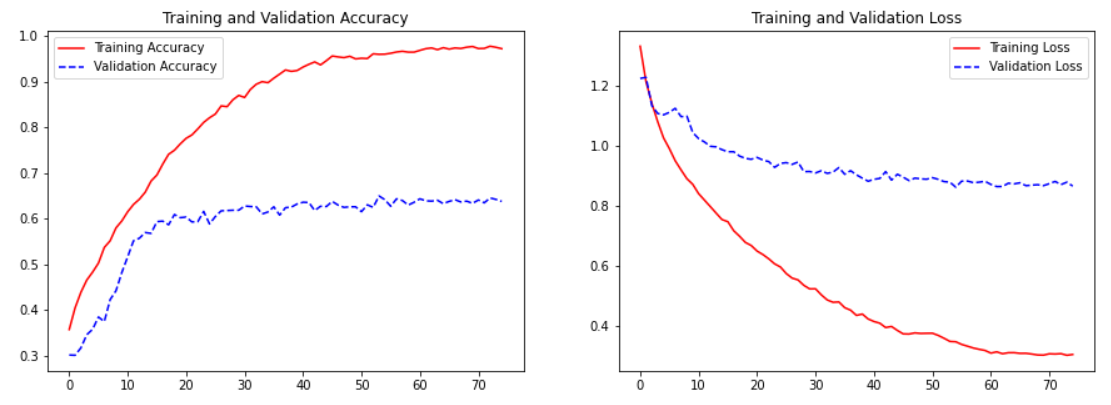
7. 훈련시킨 모델로 예측하기
# Prediction accuracy on train data
score = model.evaluate_generator(train_generator)
print("Prediction accuracy on train data =", score[1])
# Prediction accuracy on CV data
score = model.evaluate_generator(valid_generator)
print("Prediction accuracy on CV data =", score[1])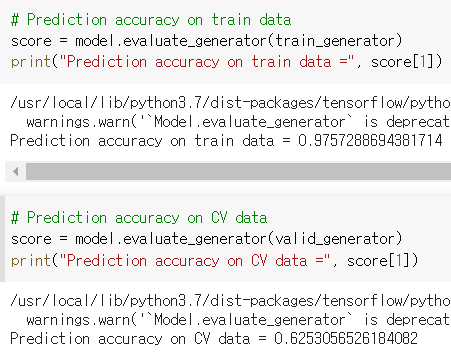
Confusion Matrix 그리기
from sklearn.metrics import *
import seaborn as sns
tick_labels = df.Cuisine.unique().tolist()
def showClassficationReport_Generator(model, valid_generator, STEP_SIZE_VALID):
# Loop on each generator batch and predict
y_pred, y_true = [], []
for i in range(STEP_SIZE_VALID):
(X,y) = next(valid_generator)
y_pred.append(model.predict(X))
y_true.append(y)
# Create a flat list for y_true and y_pred
y_pred = [subresult for result in y_pred for subresult in result]
y_true = [subresult for result in y_true for subresult in result]
# Update Truth vector based on argmax
y_true = np.argmax(y_true, axis=1)
y_true = np.asarray(y_true).ravel()
# Update Prediction vector based on argmax
y_pred = np.argmax(y_pred, axis=1)
y_pred = np.asarray(y_pred).ravel()
# Confusion Matrix
fig, ax = plt.subplots(figsize=(10,10))
conf_matrix = confusion_matrix(y_true, y_pred, labels=np.arange(n_classes))
conf_matrix = conf_matrix/np.sum(conf_matrix, axis=1)
sns.heatmap(conf_matrix, annot=True, fmt=".2f", square=True, cbar=False,
cmap=plt.cm.jet, xticklabels=tick_labels, yticklabels=tick_labels,
ax=ax)
ax.set_ylabel('Actual')
ax.set_xlabel('Predicted')
ax.set_title('Confusion Matrix')
plt.show()
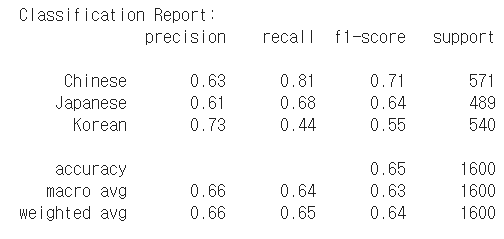
print('Classification Report:')
print(classification_report(y_true, y_pred, labels=np.arange(n_classes), target_names=df.Cuisine.unique().tolist()))
showClassficationReport_Generator(model, valid_generator, STEP_SIZE_VALID)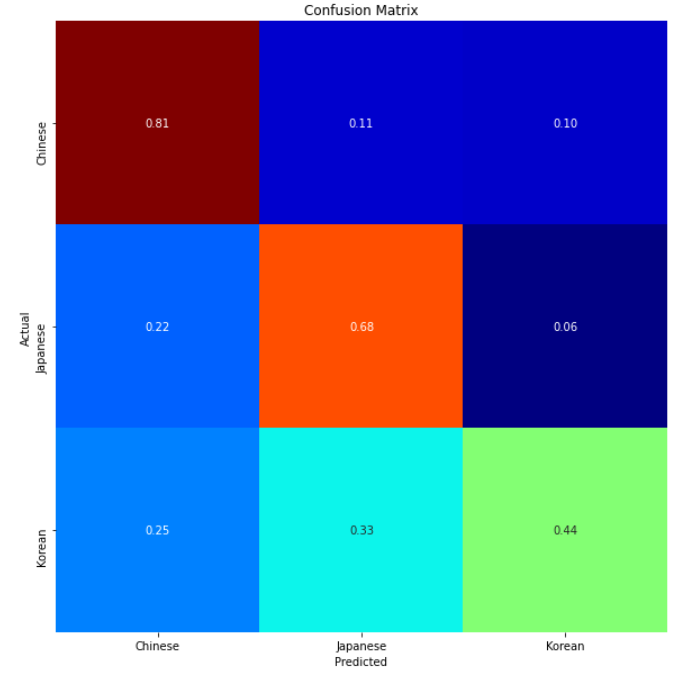
[ResNet 50]
ResNet-50은 50개 계층으로 구성된 컨벌루션 신경망이다. ImageNet 데이터베이스의 1백만 개가 넘는 영상에 대해 훈련된 신경망의 사전 훈련된 버전을 불러올 수 있습니다. 사전 훈련된 신경망은 영상을 키보드, 마우스, 연필, 각종 동물 등 1,000가지 사물 범주로 분류할 수 있다. 그 결과 이 신경망은 다양한 영상을 대표하는 다양한 특징을 학습했고 신경망의 영상 입력 크기는 224×224이다.
[분류 모델 성능 평가 지표]
- Confusion Matrix
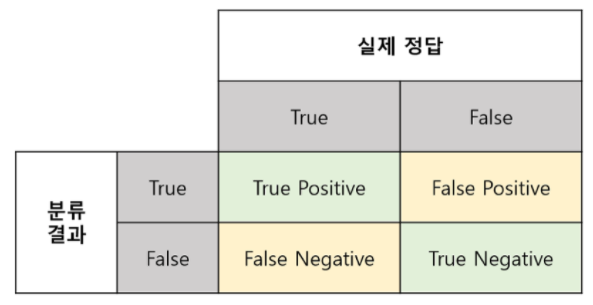
True Positive (TP) : 정답은 True이고, 분류 결과도 True인 것 (정답)
False Positive (FP): 정답은 False이고, 분류 결과는 True인 것 (오답)
False Negative (FN): 정답은 True이고, 분류 결과는 False인 것 (오답)
True Negative (TN): 정답은 False이고, 분류 결과도 False인 것 (정답)
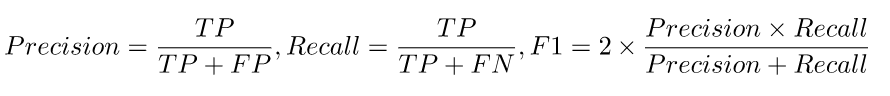
-
Precision(정밀도)
모델이 True라고 한 것 중에 실제 정답이 True인 것 (모델의 관점) -
Recall(재현율)
실제 정답이 True인 것 중에 모델이 True라고 한 것 (데이터의 관점) -
F1 Score
Precision과 Recall의 조화평균 -
Accuracy(정확도)
실제 True를 모델이 True라고 예측한것 + 실제 False를 모델이 False라고 예측한 것의 비율
[참고]
