삽입 정렬
선택 정렬은 알고리즘 풀이에 사용하기에는 느린 편이다.
선택 정렬에 비해 실행 시간 측면에서 더 효율적인 알고리즘으로 알려져 있다.
특히, 데이터가 거의 정렬되어 있을 때 훨씬 효율적임.
특정한 데이터를 적절한 위치에 '삽입'한다는 의미에서 삽입 정렬이라고 한다.
특정한 데이터가 적절한 위치에 들어가기 이전에, 그 앞까지의 데이터는 이미 정렬되어 있다고 가정한다.
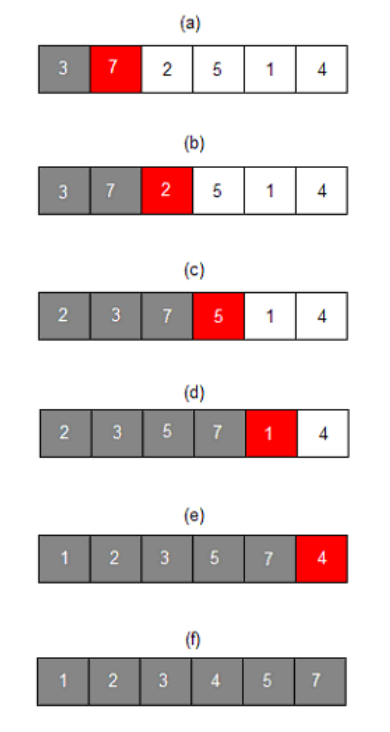
두 번째 데이터부터 시작한다.
(a): 첫 번째 데이터 '3'은 그 자체로 정렬되어 있다고 판단하고, 두 번째 데이터인 '7'이 어떤 위치로 들어갈지 판단한다.
'3'의 왼쪽이나 '3'의 오른쪽으로 들어가는 두 가지 경우 존재
오름차순으로 정렬하고자 하니 원래 자리에 둔다.
(b): 이어서 '2'가 어떤 위치에 들어갈지 판단한다. 삽입될 수 있는 위치는 총 3가지이며 '2'가 '3'보다 작으므로 '3'의 왼쪽에 삽입한다.
(c): '5'가 어떤 위치에 들어갈지 판단한다. '3'과 '7'사이에 삽입한다.
(d): '1'가 어떤 위치에 들어갈지 판단한다. '2'보다 작으므로 맨 앞 위치에 삽입한다.
(e): '4'가 어떤 위치에 들어갈지 판단한다. '3'과 '5' 사이에 삽입한다.
삽입 정렬 c++ 코드 (오름차순)
#include <iostream>
using namespace std;
int main()
{
int arr[10] = { 4,3,2,5,6,1,7,8,9,0 };
for (int i = 1; i < 10; i++)
{
for (int j = i; j > 0; j--)
{
if (arr[j] < arr[j - 1])
swap(arr[j], arr[j - 1]);
else break;
}
}
for (int i = 0; i < 10; i++)
cout << arr[i] << ' ';
}삽입정렬의 시간복잡도
O(N^2) 인데, 현재 데이터가 거의 정렬되어 있는 상태라면 매우 빠르게 동작한다는 점.
최선의 경우 O(N)의 시간 복잡도를 가진다.
삽입 정렬이 비효율적이나 정렬이 거의 되어 있는 상황에서는 퀵 정렬 알고리즘보다 더 강력하다.

HI there