논문 제목: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
📕 Summary
Abstract
Introduction
- The paper introduces SegNet, a deep convolutional neural network architecture for semantic pixel-wise segmentation, which consists of an encoder network, a decoder network, and a pixel-wise classification layer.
- SegNet is designed to be efficient in terms of memory and computational time during inference, with competitive performance and efficient memory usage compared to other architectures.
📕 Solution
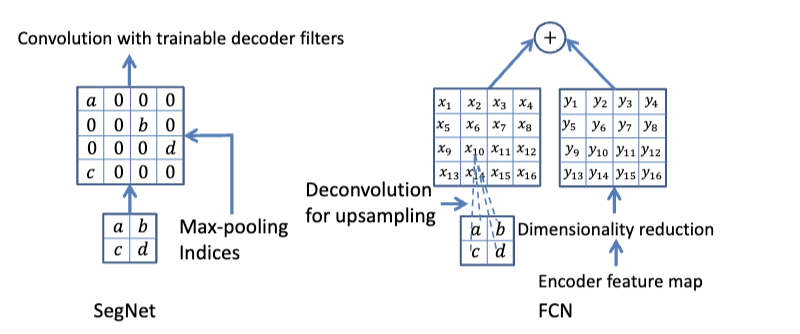
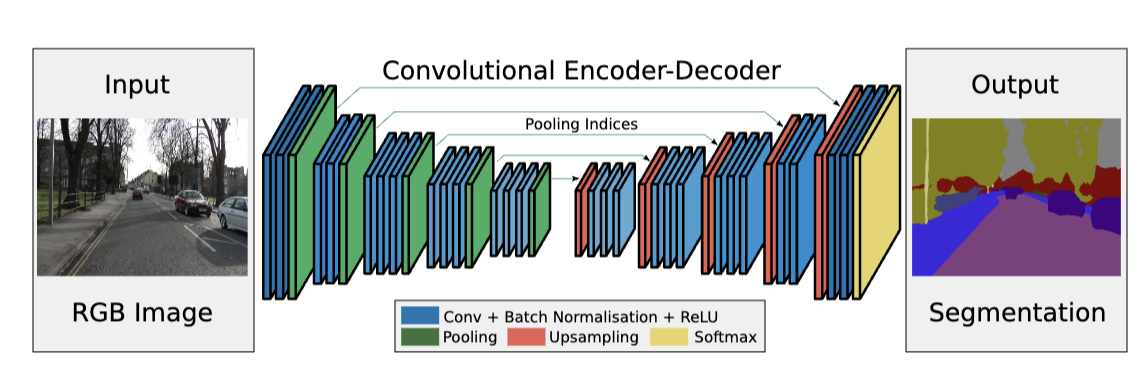
- The paper proposes a deep convolutional neural network architecture called SegNet for image segmentation. It consists of an encoder network, a decoder network, and a pixel-wise classification layer. The encoder network has 13 convolutional layers, similar to the VGG16 network, and the decoder network has 13 layers as well. The encoder feature maps are stored using max-pooling indices to capture boundary information before sub-sampling is performed. The decoder network uses these indices to perform non-linear upsampling. The final decoder output is fed to a multi-class softmax classifier for pixel-wise classification. The training process can be initialized from weights trained for classification on large datasets. The performance of SegNet is evaluated on road scene and indoor scene segmentation tasks, comparing it with other architectures like FCN and DeepLab-LargeFOV.
Algorithm
📕 Conclusion
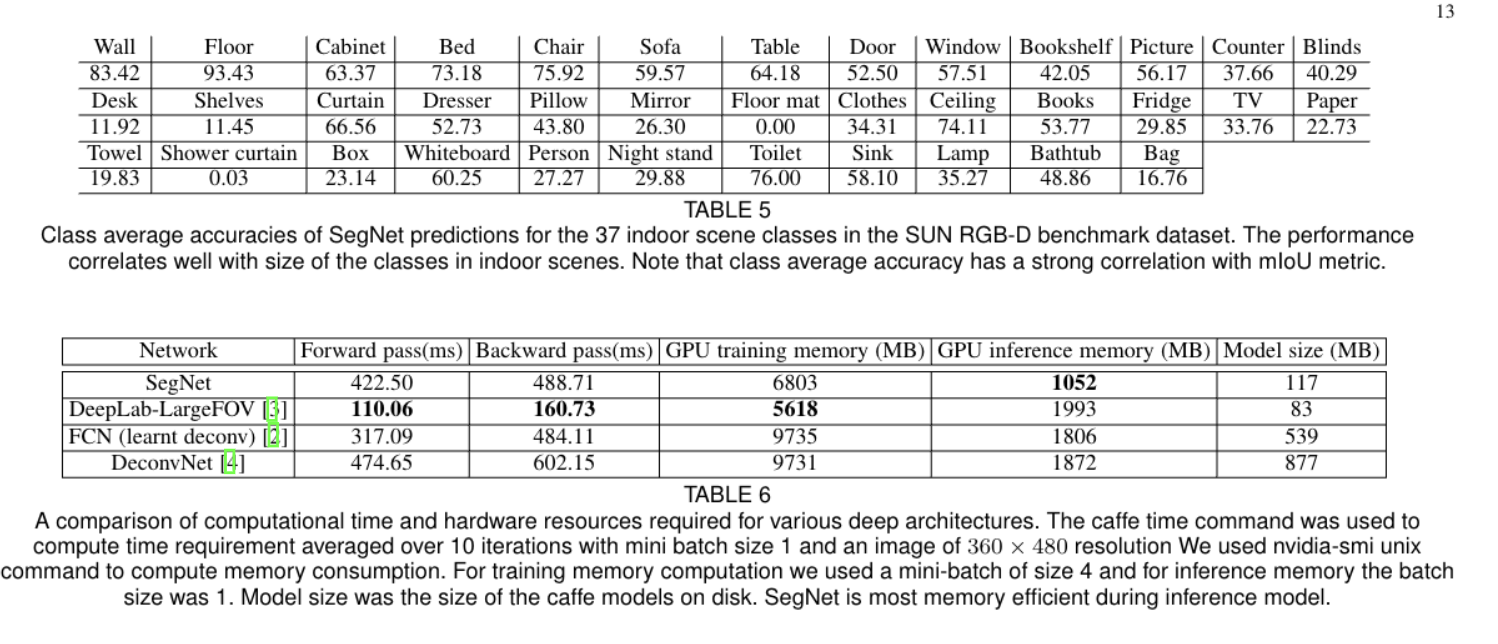
- SegNet is designed to be an efficient architecture for road and indoor scene understanding, with a focus on memory and computational time efficiency. It achieves good segmentation performance with competitive inference time and efficient memory usage compared to other architectures.
- The paper compares SegNet with other architectures like FCN, DeepLab-LargeFOV, and DeconvNet, revealing the trade-offs involved in achieving segmentation performance, particularly in terms of memory versus accuracy. SegNet is shown to be more memory efficient during inference, as it only stores max-pooling indices and uses them in the decoder network.
- SegNet performs well on road scene understanding tasks and achieves high scores on large and well-known datasets. The paper emphasizes the importance of end-to-end learning for deep segmentation architectures and hopes for more attention to be paid to this challenge.
Contribution
-
The paper presents a novel deep convolutional neural network architecture called SegNet, which is designed for semantic pixel-wise segmentation. It consists of an encoder network, a decoder network, and a pixel-wise classification layer.
-
The paper analyzes the decoding technique of SegNet and compares it with the widely used Fully Convolutional Network (FCN). It evaluates the performance of SegNet on two scene segmentation tasks: CamVid road scene segmentation and SUN RGB-D indoor scene segmentation.
-
The paper demonstrates the efficacy of SegNet by providing a real-time online demo of road scene segmentation for autonomous driving.
-
SegNet is shown to be efficient in terms of memory and computational time during inference, with competitive performance and efficient memory usage compared to other architectures.
