[논문리뷰] ModelDiff: Testing-Based DNN Similarity Comparison for Model Reuse Detection
2023 LeSN
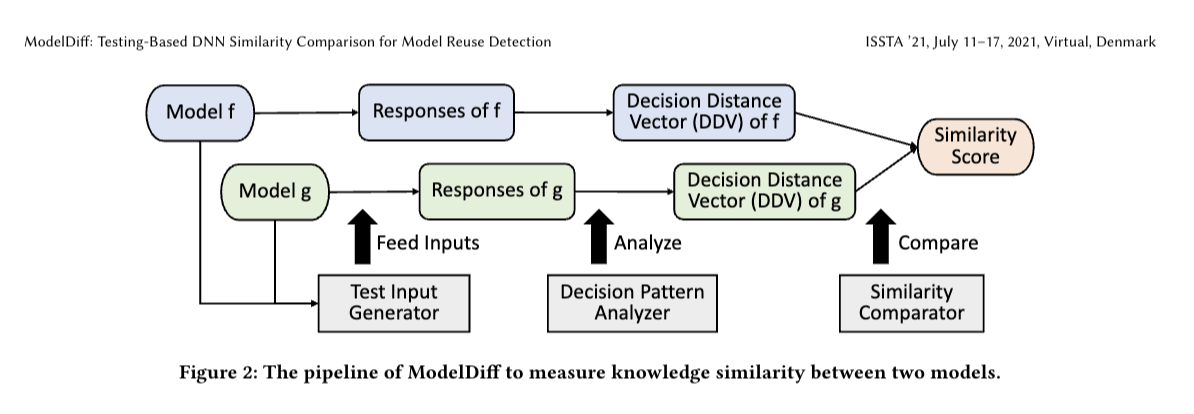
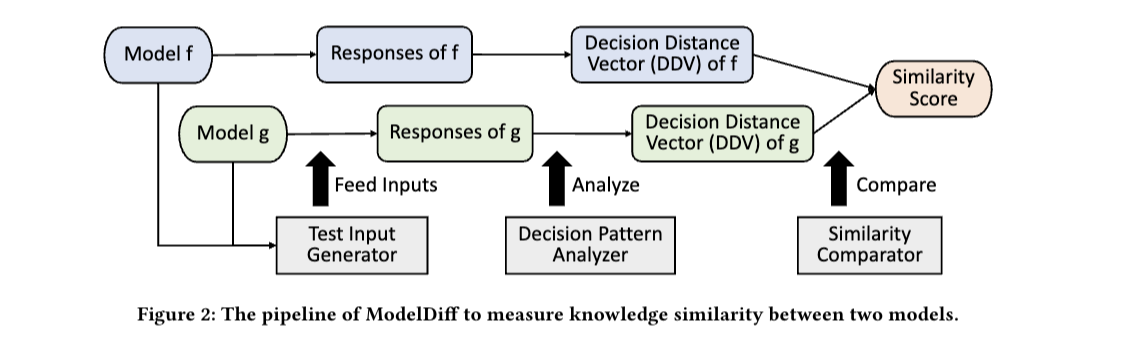
논문리뷰: ModelDiff: Testing-Based DNN Similarity Comparison for Model Reuse Detection
📕 Summary
Background
various model reuse techniques have been proposed to help developers build models based on existing models.
Problem (summarize)
- Reusing a model without authorization or license compliance would violate the IP right
- some pretrained models may have security defects and
the models based on them may inherit the defects
Solution (This paper's keywork, key insight)
Clone detection using abstract syntax trees
The paper proposes a method for detecting code clones based on the comparison of abstract syntax trees.
- Parsing the source code of a program into an abstract syntax tree (AST).
- Extracting subtrees from the AST that represent code fragments.
- Computing a hash value for each subtree based on its structure and content.
- Comparing the hash values of all pairs of subtrees to identify clones.
The paper also describes several optimizations to improve the efficiency of the method, such as filtering out small and dissimilar subtrees, and using a clustering algorithm to group similar subtrees together.
(this method is specifically designed for detecting code clones)
Algorithm

알고리즘은 세 가지 하이퍼파라미터를 입력으로 사용합니다.이러한 하이퍼파라미터는 각각 발산과 다양성, 돌연변이 강도 및 반복 횟수 간의 균형을 제어합니다.
1 알고리즘이 시드 입력 을 사용하여 입력 세트 '을 초기화합니다.
2 발산과 다양성을 계산하고 점수 변수를 합계로 초기화합니다.
3~5 알고리즘을 N번 반복하고 각 반복에서 다음 단계를 수행합니다.
6 입력 차원에서 임의의 인덱스를 선택합니다.
7~9 그런 다음 선택한 차원 에서 인덱스를 더하고 빼서 두 개의 새 입력을 계산합니다.
10~13 새 입력의 점수를 계산하고 새 입력의 점수가 현재 점수보다 높으면 X′ 및 점수 변수를 업데이트합니다.
14 마지막으로 알고리즘은 생성된 테스트 입력 X′를 반환합니다.
이 알고리즘은 블랙박스 접근 방식을 사용하므로 대상 모델 의 내부 작동에 대한 지식이 필요하지 않습니다.
알고리즘은 다이버전스와 다이버시티의 균형을 유지하여 생성된 입력이 시드 입력과 다르고 광범위한 입력 공간을 포괄하도록 합니다.
알고리즘은 돌연변이 강도 를 사용하여 각 반복에서 입력 차원에 대한 변화의 크기를 제어합니다.
반복 횟수 는 최적 입력값에 대한 검색 길이를 결정합니다
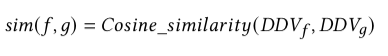
(DDv는 두 함수의 추상 구문 트리를 문서 벡터로 표현한 것입니다.)
(추상 구문 트리는 코드의 구문 구조를 나타내는 트리와 같은 데이터 구조입니다.)
코사인 유사성은 내부 제품 공간에 있는 0이 아닌 두 벡터 간의 유사도를 측정한 것으로, 두 벡터 간의 각도의 코사인을 측정합니다.
코사인 유사성 범위는 -1부터 1까지입니다. 여기서 1은 동일한 문서, 0은 완전히 다른 문서, -1은 완전히 반대되는 문서를 나타냅니다.
Contribution
- Proposing a method for detecting code clones using abstract syntax trees.
- Demonstrating the effectiveness and efficiency of the proposed method through experiments.
- Showing that the proposed method can detect clones that are not detected by other methods and can handle large code bases.
- Providing a tool, called CCFinder, that implements the proposed method.
- Suggesting that the proposed method can be used for software maintenance and evolution, as well as for detecting plagiarism in programming assignments.
📕 Strength
The paper "Clone detection using abstract syntax trees" proposes a method for detecting code clones based on the comparison of abstract syntax trees. The method involves parsing the source code to generate abstract syntax trees (ASTs) for each code fragment, comparing the ASTs to identify similar or identical code fragments, applying a set of heuristics to filter out false positives and improve the precision of the clone detection, and presenting the results of the clone detection in a user-friendly format.
📕 Weakness
-
The proposed method is limited to detecting clones within a single programming language, as it relies on the generation of ASTs specific to that language.
-
The method may not be scalable to very large codebases, as the comparison of ASTs can be computationally expensive.
📕 Think Better Solution
