BigQuery에 웹행동 이벤트 데이터를 수집하고 있다.
그 데이터들을 이리저리 만지고 옮기고 위해 Airflow를 활용하기로 했다.(물론 나혼자 결정)
Airflow 는 데이터 엔지니어 직무에서 주로 ETL 작업에서 주로 사용하는 툴로 알고 있다.
데이터 엔지니어 분이 곧 오시는데 그분한테 일을 내가 줘야 하는 이런..뭐 같은 상황이다.
(이 와중에 그 데이터 엔지니어 분도 airflow에 대한 경험이 거의 전무하다고 하심)
그래서 업무을 주고 피드백과 관리하는 걸 대비할 겸 airflow 책을 하나 보고 있다.

Data Pipelines with Apache Airflow 이라는 원본 서적을 번역한 책이다.
찾아보면 영문으로 PDF 파일도 있는데, 거의 내용의 변화는 없는 것으로 보였다.
해당 책을 읽으면서 airflow 설치해봤는데 일단 책의 내용으로는 나에게 적합하지 않아
airflow 공식사이트에서 제공하는 docker-compose.yaml 파일을 활용해 Docker 위에서 airflow를 설치 및 실행했다.
( 책에 나온 docker상에 설치하는 방식도 가능하긴 했는데, 중간에 오류들이 발생해 docker compose 방식을 사용했다. )
암튼 해당 책을 읽으면서 airflow에 대한 개념을 잡아갔고, 처음 시작할 때 하고자 했던 airflow 와 BigQuery를 연결하는 작업을 진행했다.
GCP 에서 service account key 파일 다운로드
빅쿼리는 Google Cloud 서비스 중에 하나로 여기에 접근하기 위해선 GCP에서 service account key가 필요하다.
아래와 같이 type에 "service_account" 라고 적힌 json 파일이다.
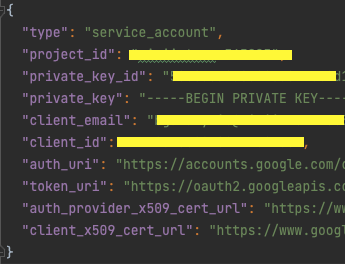
해당 파일을 다운로드 하기 위해서 service account가 있어야 하고,
해당 account에 빅쿼리를 컨트롤할 수 있는 역할 및 권한이 부여되어 있는 상태에서 파일을 다운로드 한다.
그 파일을 docker에 올리는 airflow 관련 파일들이 있는 directory의 새로운 폴더를 만들어 저장해두면 좋다.
나중에 git에 올리게 될때는 해당 폴더 및 파일은 ignore 처리는 필수.
docker-compose.yaml 수정
도커에 올리기 전에 docker-compose.yaml 을 수정해야 한다. 공식문서에서 다운로드 받은 docker-compose.yaml에는 앞서 저장한 service account Key 파일에 접근할 수 없도록 했기 때문이다.
로컬과 도커 컨테이너가 연결하는 Mount 작업이 필요하다. docker-compose.yaml 파일에서 volumes 부분에 한 줄만 추가해주면 된다. airflow 를 도커에 올릴 때 무조건 /dags, /logs, /plugins 폴더를 사전에 생성해주어야 하는데, 그 폴더가 mount 되어 있다는 것을 docker-compose.yaml 을 보면 알 수 있다. 이처럼 우리가 필요한 폴더 및 파일을 연결작업이다.
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
- ${AIRFLOW_PROJ_DIR:-.}/data:/opt/airflow/data # <-- 이 부분/data 폴더에 account Key 파일이 저장해 주었고 해당 폴더를 docker에서 사용할 수 있도록 연결할 것이다. 이렇게 수정하여 docker compose 파일을 up 하면 된다.
docker-compose up -dAirflow Connection 생성
docker에서 airflow를 실행하고 나면 환경변수들을 변경하지 않았다면 http://localhost:8080 주소를 통해 airflow 접근할 수 있다.
여기서 상단 메뉴 중 Admin -> Connections 버튼을 클릭해 Connections 페이지로 이동한다.
이동 후 + 버튼을 클릭해 connection 을 생성할 수 있다.
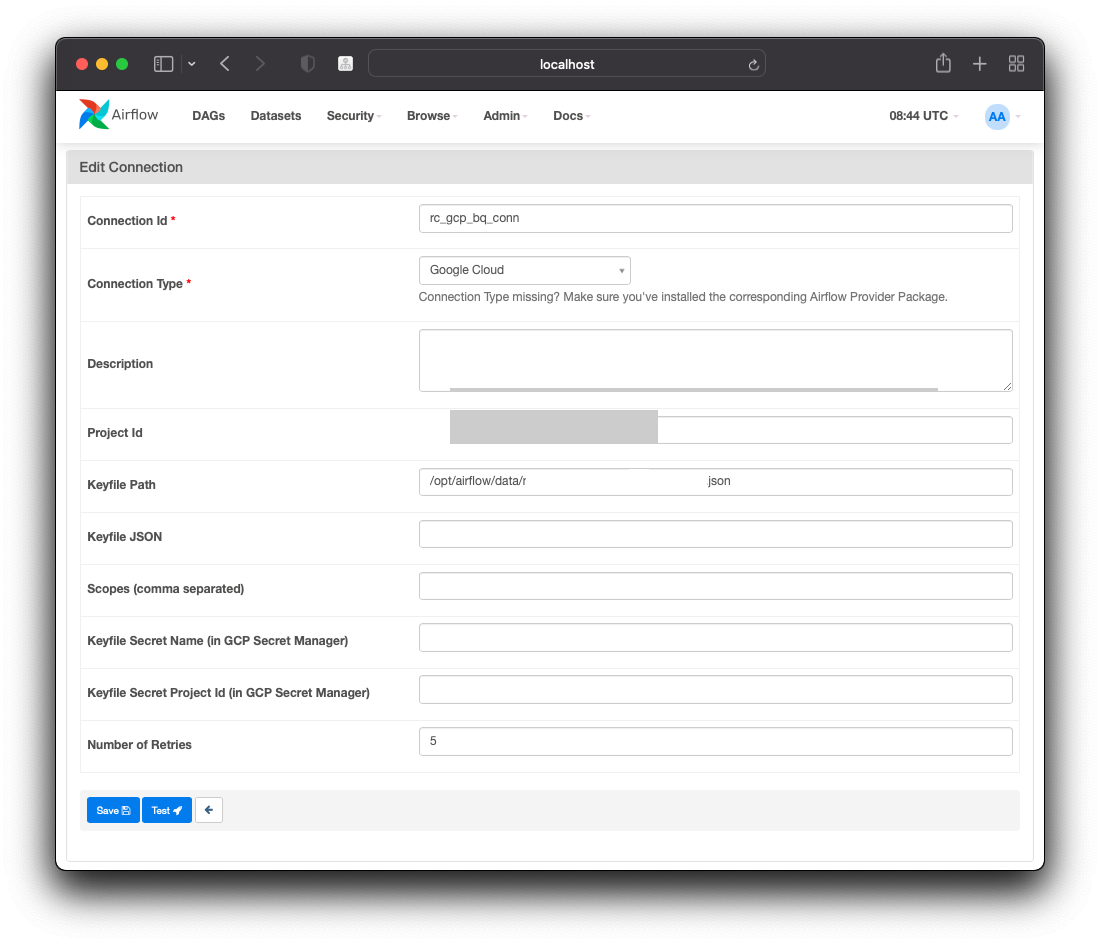
- Connection Id : DAG 를 작성할 때 지정할 id
- Connection Type : Google Cloud 로 지정
- Project Id : 빅쿼리 프로젝트 id
- Keyfile Path : service account Key 파일 지정
Task 에 gcp_conn_id 지정
BigQuery 관련 Operator를 사용할 때 conn_id를 default로 지정하지 않은 경우 gcp_conn_id 옵션을 설정해주어 했다.
gcp_conn_id 에는 connection 을 생성할 때 connection Id 를 넣어주면 된다.
BigQuery Operator 를 사용하기 위해선 apache-airflow-providers-google 라이브러리가 설치되어 있어야 한다.
pip install apache-airflow-providers-google하세요# BigQuery DAG 예시 파일
from airflow import DAG
from datetime import datetime
from airflow.providers.google.cloud.operators.bigquery import BigQueryCreateEmptyTableOperator
from airflow.providers.google.cloud.operators.bigquery import BigQueryCreateEmptyDatasetOperator
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 3, 15),
}
DATASET = "simple_bigquery_example_dag"
TABLE = "forestfires"
with DAG('example_bigquery_dag',
default_args=default_args,
schedule_interval=None) as dag:
create_dataset = BigQueryCreateEmptyDatasetOperator(
task_id="create_dataset", dataset_id=DATASET,
gcp_conn_id='rc_gcp_bq_conn'
)
create_table = BigQueryCreateEmptyTableOperator(
task_id="create_table",
dataset_id=DATASET,
table_id=TABLE,
schema_fields=[
{"name": "id", "type": "INTEGER", "mode": "REQUIRED"},
{"name": "y", "type": "INTEGER", "mode": "NULLABLE"},
{"name": "month", "type": "STRING", "mode": "NULLABLE"},
{"name": "day", "type": "STRING", "mode": "NULLABLE"},
],
gcp_conn_id='rc_gcp_bq_conn'
)
create_dataset >> create_table위의 코드는 빅쿼리에 데이터세트를 생성하는 task와 해당 데이터세트 안에 테이블을 생성하는 task 로 이루어져 있다. 해당 DAG는 schedule_interval=None 이기 때문에 직접 실행해야 하며, 실행하며 BigQuery 에서 데이터 세트와 데이터테이블이 생성된 결과를 확인할 수 있다.
airflow 에 대한 장점만 들어보고 접근했더니 생각보다 환경세팅이 어려워 BigQuery 연결 작업도 오래 걸릴 거라고 생각했었는데,
연결자체는 어렵지 않았다. 다만 처리해주어야 할게 조금 많다는 건 아쉽지만.
그래도 일단 연결을 완료했으니 이제 필요한 데이터를 추출하고 저장하는 작업, 그리고 해당 작업을 스케줄링 하는 작업을 진행해야겠다.
