시퀀스형 자료형
- list
- str
list
- 기본 타입은 아니지만, 거의 기본타입처럼 사용됨.
- 여러 데이터들의 집합으로 이루어진 자료형
- int, float, str 등 여러 형태의 데이터를 할당할 수 있음.
(JAVA의 경우, 같은 타입만 리스트에 넣을 수 있음.
파이썬은 다른 언어와 달리, 메모리의 주소를 계속 참조하기 때문.
list =['1','a','blue']
list 특징
- 인덱싱
- 슬라이싱
- 라스트 연산
- 추가삭제
- 메모리 저장 방식
- 패킹과 언패킹
- 이차원 리스트
1. 인덱싱
- list의 값은 주소(offset)을 가짐
- 주소를 통해 값을 호출
fruit = ['banana', 'apple', 'orange']
fruit[0] # banana
2. 슬라이싱
- list 값 일부만 사용
- 주소값의 일부만 반환
fruit = ['banana', 'apple', 'orange','kiwi','mango']
# 범위를 넘어서면 자동으로 최대 범위 지정
print(fruit[-10: 10]) #'banana', 'apple', 'orange'
# 모든 내용
print(fruit[:])
# 역
print(fruit[::-1]) #['mango', 'kiwi','orange','apple','banana']
#두 칸 단위로 역으로
print(fruit[::2])
# 시작, 끝, 스텝
#print(fruit[0:10:2]) # ['banana', 'orange','mango']
3. list 기본 연산
-
리스트 연결( concatenation)
a= [1,2,3]
b=[4,5,6,7]
print(a+b) = [1,2,3,4,5,6,7] -
길이 반환
len(a)= 3 -
특정 인덱스값 변경
a[0]=10 -
반복
print(a*2) # [1,2,3,1,2,3] -
존재여부
2 in a # True
2 in b # False -
할당
- 할당을 해야 메모리에 저장
c= a+b
4. list 추가삭제
-
extend : list의 가장 끝 쪽에 모든 항목을 삽입
-
append : 리스트 가장 끝에 값을 그대로 삽입
-
remove(): 값을 삭제
del list[0]: 인덱스 값 삭제
- append vs extend

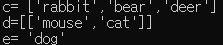
append
- 받은 값 그대로를 리스트에 추가
- 문자열일 경우 단어를 추가


extend
- 받은 값에서 객체를 리스트에 추가
- 문자열일 경우 알파벳을 추가


5. 리스트의 메모리
-
다른 언어와 달리, 파이썬은 메모리 주소를 계속 참조한다.
-
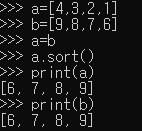
a=b : a와 b는 동일한 메모리 공간을 할당 받게 됨. sort를 a에만 적용했음에도 b도 동일한 결과를 갖음(메모리 주소 참조)
-
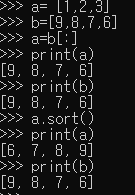
a=b[:] : 메모리 공간을 공유하지 않고, 값만 복사.sort를 a에만 적용했을 경우, b도 동일한 결과를 같지 않음. 서로 다른 메모리 공간을 갖기 때문
6. 패킹과 언패킹
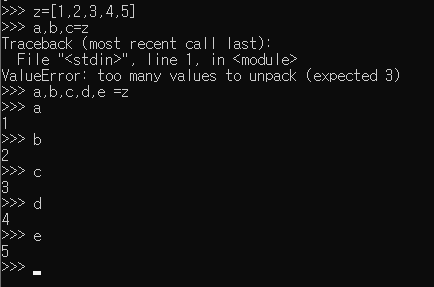
- 패킹: z에 값들을 패킹
- 언패킹: a~e변수에 z값을 언패킹
7. 이차원 리스트
-
리스트 속에 리스트를 넣어 행렬(matrix) 생성
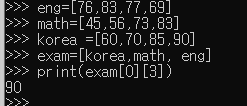
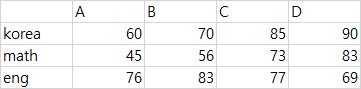
A B C Dkorea 60 70 85 90
math 45 56 73 83
eng 76 83 77 69
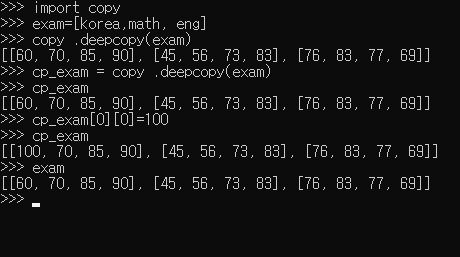
-
copy = array[:]로 값만 복사하는 것 1D에서는 가능, 그러나 2D에서 불가 (메모리 참조)되는 현상

-
copy를 하고 싶을 때 import cpoy를 하여 de - copy 해야한다.
String
- 문자열 : 시퀀스 자료형, 문자형. 영문자 한 글자는 1byte 메모리 차지
import sys
print(sys.getsizeof("a")) #a의 메모리 출력- 1byte
- PC는 이진수로 데이터 변환 및 처리
- 2진수 한 자리는 1bit
- 1 bit는 0또는1
- 1byte= 8bit
- 한글은 UTF-8을 사용을 가장 많이 함
- 메모리 관리는 데이터처리에서 중요
문자열의 특징
-
리스트와 특징이 유사.
-
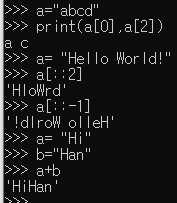
인덱싱
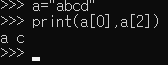
-
슬라이싱
문자열 함수
- len(a)
- a.upper()
- a.lower
- a.capitalize()
- a.title(): 제목 형태로 변환(첫글자들만 대문자로 변환)
- a.count('abc') : 문자열 a에 abc가 들어간 횟수 반환(대소문자)
- a.find('abc')/ a.rfind('abc') : 문자열a에 abc가 들어간 위치 반환
- a.startswith('abc') : 문자열 a는 'abc'로 시작하는 지 여부 반환
- a.endswith('abc') :문자열 a가 'abc'로 끝나는 지 여부반환
- a.strip() :공백 삭제/" Hello ".strip()
- a.rstrip() : 오른쪽 공백 삭제
- a.lstrip()
- a. split('abc'): abc 기준으로 나누어 리스트로 반환
- a.isdigit(): 문자열이 숫자인지
- a.islower(): 문자열이 소문자인지 여부
-a.issupper(): 문자열이 대문자인지 여부 반환
문자열 표현
-
a ='It\' ok.' # \' ->문자 '로 구분
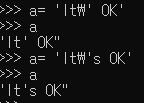
-
a ="it's ok." #
-
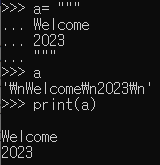
따옴표 3번 사용
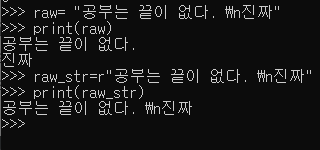
raw string
- 특수문자 \escape 글자 무시하고 출력
- str 앞에 r추가, \n 무시
- wdget URL: URL 다운로드
- cat
- code py : py파일 vscode에서 읽기
- ctrl+/ 주석처리
num_a= a.upper().count("APPLE") #대소문자 구분 제거
참고
