프로젝트 마무리와 함께 하는 정리,,
어느덧 몰입해있던 프로젝트를 마무리하고 편히 쉴까,,,,하다가 '언제든 보아도 다시 구현 할 수 있는 정리를 해내자!'라는 마음으로 정리를 해본다.
블로그 머리에 써둔 것처럼 '제대로 아는 것만 정리하기'로 했기에, 정말 제대로 알고 있다고 생각하는 질리도록 보아왔지만 이후 보지 않을 수 있는 내용들을 정리해 나가려 한다.
kafka는 두 가지 프로젝트에서 사용했다. MSA 아키텍쳐이자 여러 데이터베이스를 가지는 서비스에서 데이터 전송을 용이하게 하고 또 다른 모듈을 개발할 계획이 있었기 때문에 확장성을 고려했던 프로젝트, 실시간 데이터 전송을 하고자하는 프로젝트에서 사용했다.
사실 이 포스팅의 초안은 팀 동료들과 kafka에 대한 이해와 구축 방법에 대한 공유를 위해 작성되었으나, 이후에 볼 나와 모두를 위해 블로그에 작성하기로 했다.
그래서 kafka는 왜 쓰는데..?
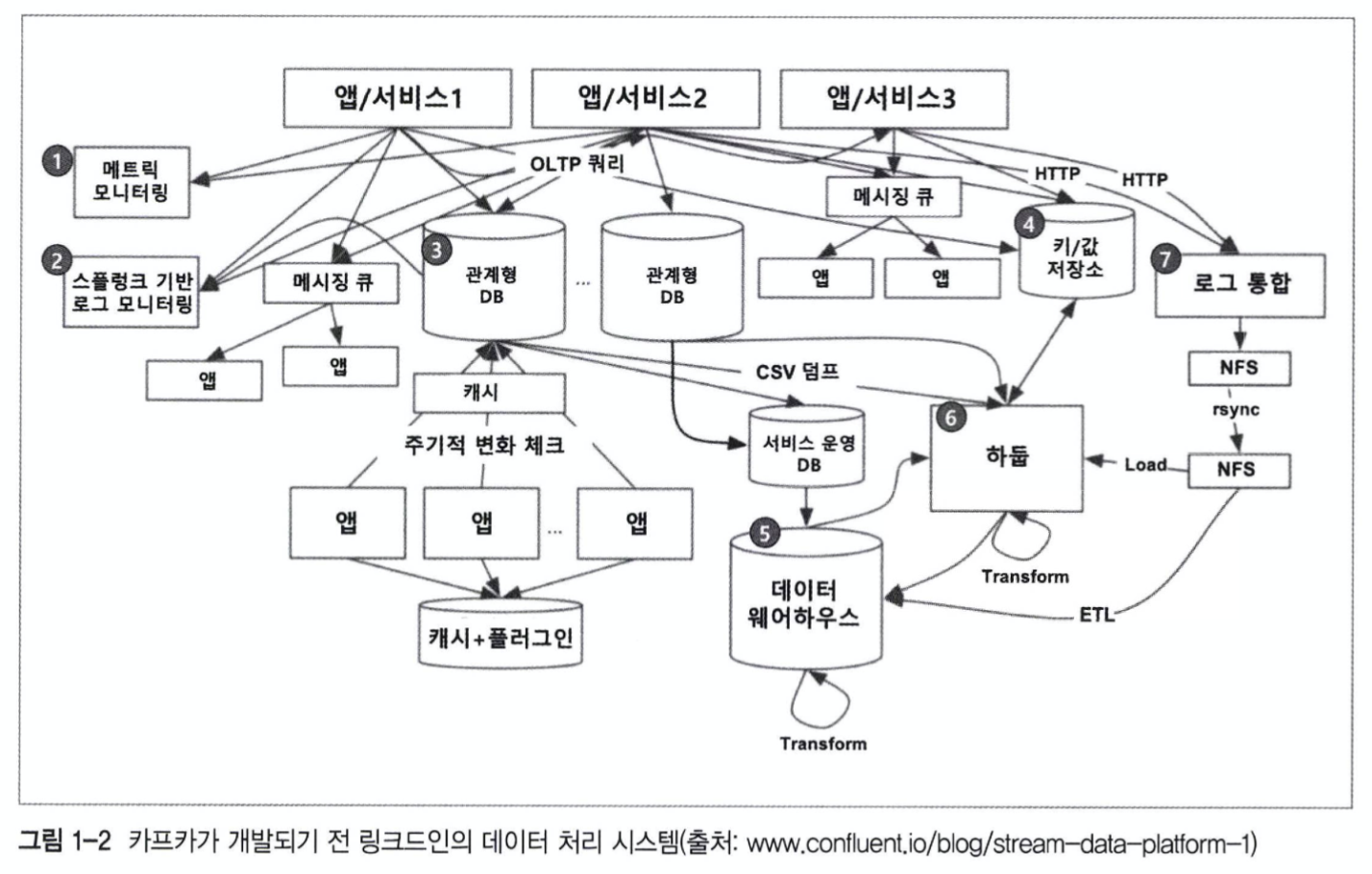
카프카는 미국 큰 기업 링크드인에서 만든 기술이다. 기존 링크드인의 데이터 처리 구조는 위 사진과 같이 굉장히 복잡한 형태를 띄는데, 만약 문제가 발생할 경우 해당 문제와 연관된 모든 노드를 찾아 파악해야 한다. 그만큼 문제 해결에 어려움을 겪는다는 것, 생산성이 떨어진다는 뜻이다.
또한 만약 모듈 개발, 데이터베이스와 같은 확장이 일어날 경우, 중앙화된 전송 영역이 없어 그만큼 기존 데이터베이스, 시스템에 더 많은 부하가 발생할 것이다.
이 마저 같은 방식, 같은 형식을 가진다면 다행이지만, 기존 팀이 교체되어 새로운 방식으로 개발하게 된다면 또 다른 문제가 발생할 가능성이 생기며, 그만큼 파이프라인의 확장이 어려워진다는 것을 의미한다.
결론적으로, 전송 표준화/중앙화의 부재로 인한 문제를 해결하기 위한 수단으로 kafka를 개발했다고 볼 수 있다.
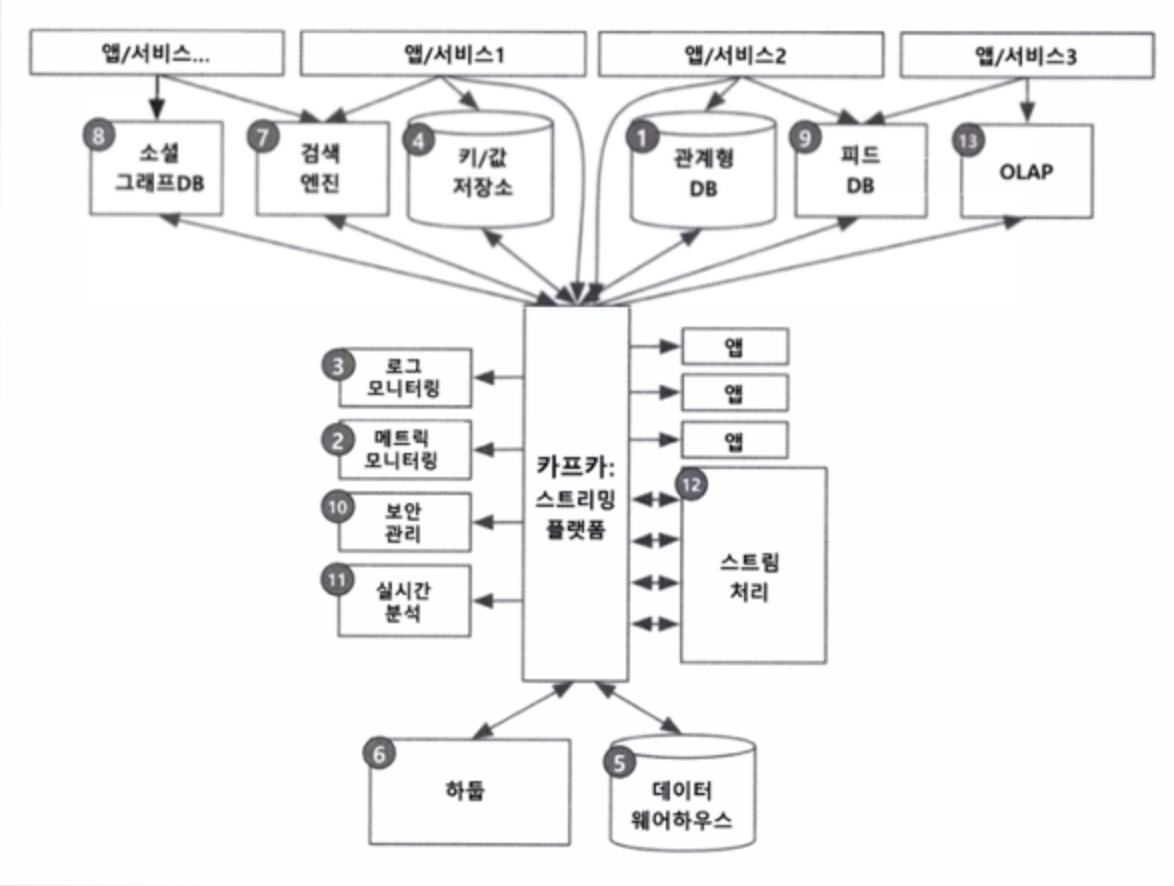
카프카는 확장성을 가지기 어려운 end to end로 데이터를 직접 전달하는 방식에서 벗어나 중앙에서 관리함으로써 복잡한 시스템 구조에서 데이터 전송/수신에 용이한 특징을 가진다.
간단 정리!
1. 카프카는 확장성을 고려한다면, 전송 중앙화를 위해 사용한다!
2. 어플리케이션 자체와 별도로 동작하기 때문에 하나에 어플리케이션에 에러가 발생해도 다른 어플리케이션에 지장을 주지 않는다!
3. 실시간 처리가 가능하다!
Kafka는?

카프카 공식 홈페이지에는 '오픈소스 분산 이벤트 스트리밍 플랫폼'이라고 소개한다. 쉽게 말해 이벤트 전송로인 '파이프라인'을 관리하여 스토리지 간 연결을 통합, 관리하는 플랫폼이라는 것이다,, 더 쉽게는 여러 데이터들을 분산 관리해주는 플랫폼이다.
kafka는 검색을 하다보면 알 수 있듯, pub-sub모델, 즉 발행자와 구독자의 관계로 이루어져 있다. 쉽게 말해 발행자 - 구독자가 바로 이어져 있는 것이 아니라, 발행자가 kafka의 관심사에 정보를 올려두면, 이 관심사를 구독하고 있는 구독자가 해당 정보를 가져오는 방식으로, 소켓 연결과 같이 직접 연결하는 방식과는 다른 연결 방식을 가지고 있다.
그럼 kafka에서 이벤트는?
kafka에서 이벤트는 어떤 사건이 발생했을때, 이 사건 자체를 이벤트로 칭한다. kafka 와 비슷한 ActiveMQ, RabbitMQ와 같은 플랫폼의 공식 문서에는 Record나 Message라는 단어를 쓰기도 하는데, 결국 플랫폼 내에서 작용은 비슷하기에 같은 의미로 생각해도 괜찮을 것 같다.
그럼 kafka에서 스트리밍은?
스트리밍은 데이터를 쪼개 순차적으로 받아오는 기법이다. 따라서 이벤트 스트리밍은 이벤트를 스트림 형태로 받아오는 것이다.
kafka는 스트림 형태로 받아온 이벤트를 실시간으로 저장하고, 저장되는 정보들이 적절한 목적지로 제공될 수 있게 해준다.
kafka를 사용하다보면 여러 용어들이 있다. 간단히 정리하자면 이렇다.
producer - 데이터를 보내는 역할
consumer - 데이터를 받는 역할
broker - producer, consumer 사이에서 데이터를 전달하는 역할을 가진 서비스
topic - 이벤트의 종류, 관심사
partition - topic의 분산 처리를 위한 저장 객체
zookeeper - 분산 처리를 위한 관리 도구로, topic, partition과 같은 브로커에서 관리하는 메타정보 저장 및 관리
kafka client - kafka 운영 도구
간단한 예시,,
나는 슈카월드라는 유튜브 채널을 통해 시사 정보나, 세상 돌아가는 꼴을 보곤 하는데, 채널을 구독하고 있어 언제든 유튜브에 들어가면 상단에 슈카월드에서 업로드한 영상이 뜬다. 슈카월드 채널 관리자(producer)는 유튜브(broker) 슈카월드 채널(topic)에 영상(event, record)을 업로드하고 이를 구독하고 있는 구독자들(consumer)은 모두 이 영상을 볼 수 있다.
와 같은 느낌으로 작동 원리를 이해할 수 있지 않을까.. 알겠지 미래의 태선아..?
그럼 어떻게 쓰냐 이걸
1. 환경 세팅
일단 가정하는 환경은 AWS EC2 인스턴스에 kafka를 설치하고 활용하는 방법이다. 보통 연습의 경우 t2.micro 환경을 사용한다.(공짜니까,,)
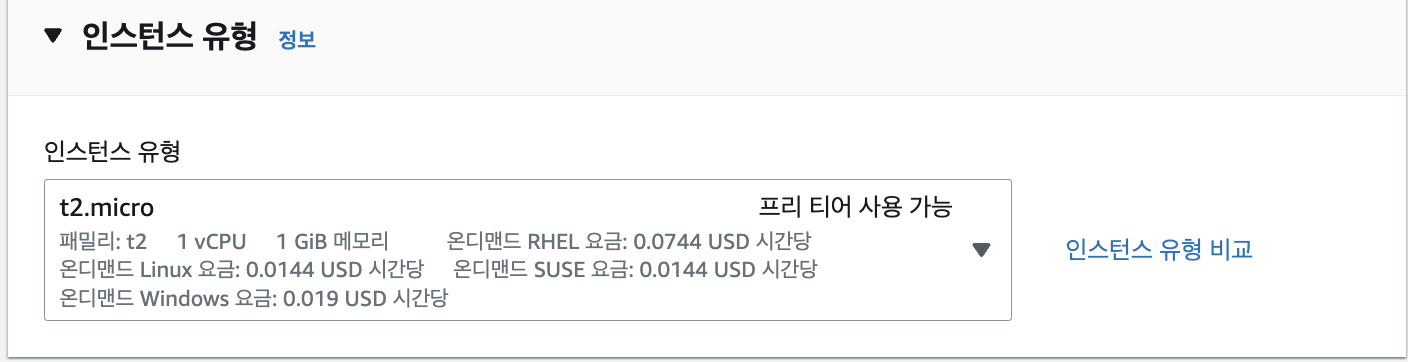
이 경우 볼 수 있다시피 싱글코어에 1GiB 메모리를 가지는 인스턴스 환경이다. 이 점을 생각하고 진행해야 한다.
먼저 ec2 인스턴스를 생성하면, kafka에서 사용하는 포트를 열어주어야 하기에 인바운드 보안 규칙을 설정해준다.
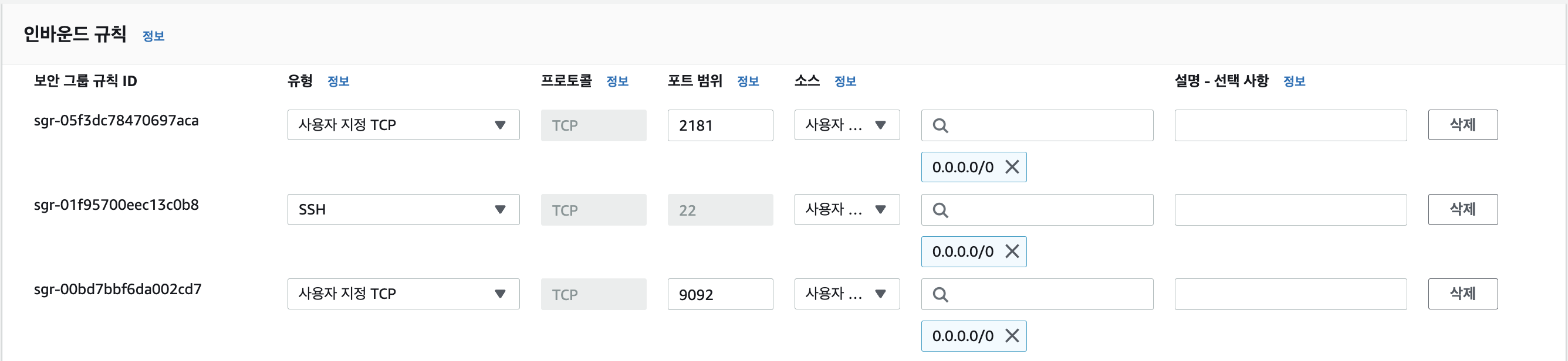
이렇게, zookeeper와 kafka를 동일 인스턴스에 작동시킨다는 가정하에 열어둔 포트이다.
만약 두 가지를 다른 인스턴스에서 작동한다면, zookeeper 서버는 2181, kafka 서버는 9092포트를 열어주면 된다.
참, 그리고 JDK 8버전 이상이 필요하다!
2. kafka 다운로드
그 다음 wget 명령을 통해 kafka를 다운로드 해줄 건데,
https://kafka.apache.org/downloads
kafka 공식 다운로드 페이지에 들어가서 원하는 버전의 binary download의 링크를 우클릭해보면,
이렇게 링크 주소를 복사할 수 있다.
링크 주소를 복사하여 wget 명령어 뒤에 붙여주면,


이렇게 정상적으로 다운로드가 받아지고, tgz 파일이 정상적으로 생성된 모습을 볼 수 있다.
tar xvf kafka_{버전}.tgz
명령어를 통해 해당 tgz 패키지 파일을 압축 해제해주면 다운로드는 완료된다.
여기에는 kafka, zookeeper와 같은 관리 도구가 모두 동봉되어있다. 다른 프로그램을 굳이 다운로드할 필요는 현재까지 없었다.
3. kafka 설정
사실 여기서 내가 가장 많이 간과했던 것이 앞서 말했던 메모리 부족으로 인한
"Cannot allocate memory" 오류였는데,
이 이유는 bin/kafka-server-start.sh, bin/zookeeper-server-start.sh를 열어보면 알 수 있다.
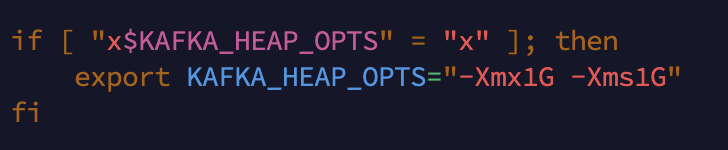

이와 같이 kafka의 기본 힙 메모리는 1G, zookeeper의 기본 힙 메모리는 512M으로 설정되어 있어 1GiB 메모리를 무료 제공하는 t2.micro환경에서는 kafka를 돌릴 수 없게 된 것이다.
사실 해결방법은 간단하다.
저 조건문의 조건은 $KAFKA_HEAP_OPTS라는 변수가 저장되어있지 않을 때이므로,
export KAFKA_HEAP_OPTS="-Xms400m -Xmx400m"
명령어를 통해 변수를 등록하여 힙메모리를 설정해주거나, 서버를 재실행할 일이 많을 경우 해당 명령어를 .bashrc에 저장해두면 된다.
다음은 kafka 설정파일인 config/server.properties를 설정해줄 것이다.
열어보면 많은 명령어들이 나오는데,
advertised.listeners=PLAINTEXT://{현재 인스턴스 ip}:9092
zookeeper.connect=localhost:2181 요렇게 두가지만 저장해줄 것이다. 만약 zookeeper를 다른 서버에서 작동한다면, zookeeper.connect 항목의 localhost를 해당 서버의 ip로 바꿔주면 된다.
이렇게 해서 설정하는 방법에 대한 정리는 마치고, 명령어에 대한 것으로 넘어간다.
명령어 정리
bin/zookeeper-server-start.sh config/zookeeper.propertieszookeeper 실행 명령어이다. bin/zookeeper-server-start.sh 뒤에 -daemon 명령어를 넣어 백그라운드에서 실행할 수 있다. kafka를 작동하기 전 가장 먼저 작동해야 하는 명령어이다.
bin/kafka-server-start.sh config/server.propertieskafka 실행 명령어이다. 이 또한 위와 같은 방식으로 백그라운드 실행이 가능하다.
bin/kafka-topics.sh --create --topic {생성하고자 하는 topic명}
--bootstrap-server localhost:9092토픽 생성 명령어이다.
--partition {숫자} 옵션을 통해 파티션 갯수를 설정할 수 있다.
bin/kafka-console-producer.sh --topic {topic명}
--bootstrap-server localhost:9092topic에 producer 역할로 접근하는 명령어이다. 해당 명령어를 통해 접근하면 topic에 event(or record)를 저장할 수 있다.
bin/kafka-console-consumer.sh --topic {topic명}
--bootstrap-server localhost:9092topic에 consumer 역할로 접근하는 명령어이다. 해당 명령어를 통해 접근하면 topic에 저장되는 event(or record)를 볼 수 있다.
--from-beginning 옵션을 통해 해당 topic에 저장된 데이터를 처음부터 볼 수 있다.
bin/kafka-topics.sh --bootstrap-server localhost:9092 --listzookeeper에 저장된 topic리스트를 확인하는 명령어이다.
만약 토픽을 삭제하고 싶다면?
config/server.properties에
delete.topic.enable = true 이 한줄을 먼저 추가해주고,
zookeeper-shell localhost:2181zookeeper shell에 접근하는 명령어이다. 만약 zookeeper를 다른 인스턴스에서 작동한다면, localhost를 해당 ip로 바꿔준다.
해당 명령어를 통해 zookeeper shell에 접근한 후,
ls /brokers/topics명령어를 통해 현재 topic 목록을 확인하고,
deleteall /brokers/topics/{지우고 싶은 topic명}명령어를 통해 해당 topic과 관련된 모든 내용을 삭제할 수 있다.

대단하십니다!