
...솔직히 FSD(Feature Sliced Design)를 프로젝트에 도입해보려 했는데, 이론적으로는 그럴듯해 보이지만 막상 해보면 오히려 복잡성만 가중시키는 느낌입니다. feature와 entity의 경계도 애매한 경우가 많고, 이걸 팀원들에게 설득하기도 어렵습니다. 문서를 봐도 각 레이어에 딱 맞는 컴포넌트 구분이 현실적으로 가능한지 의문이고요. 테오는 FSD를 사용하기 전에 선호했던 폴더구조는 어떤 것인가요?

프롤로그
FSD를 쓰기 전에도 프로젝트의 규모가 커짐에 따라 전통적인 폴더구조와 실제로 코드의 흐름이나 생각을 반영하는게 맞지 않다 여겨져서 조금씩 변화를 시도했던 막연한 생각에서 FSD가 제안하는 실질적인 구조의 형태를 보니 흐릿했던 생각들이 선명해짐을 느낄 수 있었습니다. 기능을 중심으로 응집도를 높인다는 아키텍쳐는 공감이 되었고 FSD는 이러한 기능 중심 아키텍처를 이해하는 데 유용한 도구라고 생각합니다.
FSD의 구조적 체계의 완성도는 높지만, 일부 규칙은 경직되어 있고 아주 세분화된 구조로 인해 작은 규모의 프로젝트에서는 오히려 복잡함을 유발하기도 합니다. 특히나 모든 프로젝트에 일괄적으로 문제없이 들어맞는 모델은 아닙니다. 어찌보면 보편적인 방식이라기 보단 조금 특수한 케이스를 푸는 방법에 더 가깝다고 생각합니다.
그렇기에 저 역시 현업에서는 온전히 FSD의 규칙을 그대로 따르기보다는, 프론트엔드 아키텍처를 바라보는 하나의 사고 방식, 즉 멘탈 모델로 삼아 참고하며 적절히 변용해서 사용하고 있습니다. 그래서 이를 설명할 때에도 "FSD를 그대로 따르기보다는 구조를 이해하는 데 도움을 주는 렌즈처럼 활용해 달라"고 덧붙여 왔습니다. 그리고 이 점은 프론트엔드의 계층과 체계를 선명하게 바라보는데 상당히 유용합니다.
하지만 실제로 기능 중심 아키텍처를 적용할 때에는 '왜 이런 기능 중심 구조가 필요한가?'라는 질문보다는 entities, features, widgets와 같은 이름에 맞춰 분류하고 규칙을 적용하는 데에 매몰되기 쉬운 경향이 생깁니다. 가령 '이건 entities일까? features일까?' 라는 선택의 고민을 더 하게 되죠. 사실 저도 처음에는 엄청 이 분류 고민만 했었습니다. 하지만 이건 당연하죠. 해봐야 이해를 할 수 있으니까요.
저 역시 FSD 구조에 맞춰서 이리저리 헤매 보면서 알게된 FSD 구조가 왜 그렇게 설계되었는지에 대해 철학이 분명하게 생기게 되었고, 동시에 그대로 적용하기에는 여러 제약들도 겪으면서 좋았던 점들과 아쉬운 점들, 그리고 그 과정에서 알게 된 통찰들을 공유하고 싶었습니다.
이번 글에서는 FSD라는 특정 방법론의 사용법을 설명하기보다는, 프론트엔의 폴더구조가 어떤 필요와 문제 해결 과정을 통해 자연스럽게 진화해 왔는지 그 여정을 따라가보려 합니다. 역할 기반 구조에서 시작해서 도메인 중심, 그리고 계층적 구조로 발전하는 과정에서 각 단계마다 어떤 한계를 마주했고, 그것을 해결하기 위해 어떤 사고의 전환이 필요했는지를 살펴볼 예정입니다.
폴더 구조, 프론트엔드 아키텍처를 바라보는 멘탈 모델
멘탈 모델이란, 사람들이 어떤 시스템이나 개념을 이해하고 예측하기 위해 머릿속에 그리는 구조적 이미지 또는 틀을 말합니다. 개발자에게 멘탈 모델은 "이 프로젝트가 어떻게 구성되어 있고, 각 부분이 어떻게 연결되어 있는가?"에 대한 직관적 이해를 의미합니다.
인간의 뇌는 정보를 기억할 때 위치와 함께 저장하는 특성이 있습니다. 그래서 체계적으로 조직된 정보를 더 쉽게 기억하고 활용할 수 있으며, 폴더 구조가 잘 짜여 있으면 개발자는 "이 코드가 어디 있더라?"를 매번 고민할 필요 없이 자연스럽게 위치를 떠올릴 수 있습니다.
또한 뇌는 예측 가능한 패턴을 선호하기 때문에, 일관성 있는 구조는 새로운 코드를 어디에 배치해야 할지에 대한 불필요한 고민을 줄여줍니다. 좋은 폴더 구조는 이런 인지적 부담을 최소화하여 개발자가 본질적인 문제 해결에 집중할 수 있도록 도와주며, 특히 작은 프로젝트에서는 별 문제가 없던 구조가 규모가 커지면서 문제가 되는 것도 결국 개발자의 머릿속 멘탈 모델과 실제 코드 구조가 일치하지 않기 때문입니다.
그렇다면 이런 불일치는 왜 발생하는 걸까요? 프론트엔드 개발을 하다 보면 자연스럽게 마주하게 되는 이런 고민들이 어떤 과정을 통해 점진적으로 해결되어 왔는지, 그리고 그 과정에서 어떤 식의 사고 전환이 필요했는지를 차근차근 풀어보겠습니다.
이러한 자연스러운 발전 과정을 이해하면, FSD의 각 레이어가 왜 필요한지도 저절로 이해가 되고, 더 나아가 각자의 프로젝트 상황에 맞는 최적의 구조를 스스로 설계할 수 있는 판단력을 기를 수 있을 것이라 생각합니다.
1부. 프론트엔드 폴더 구조의 진화
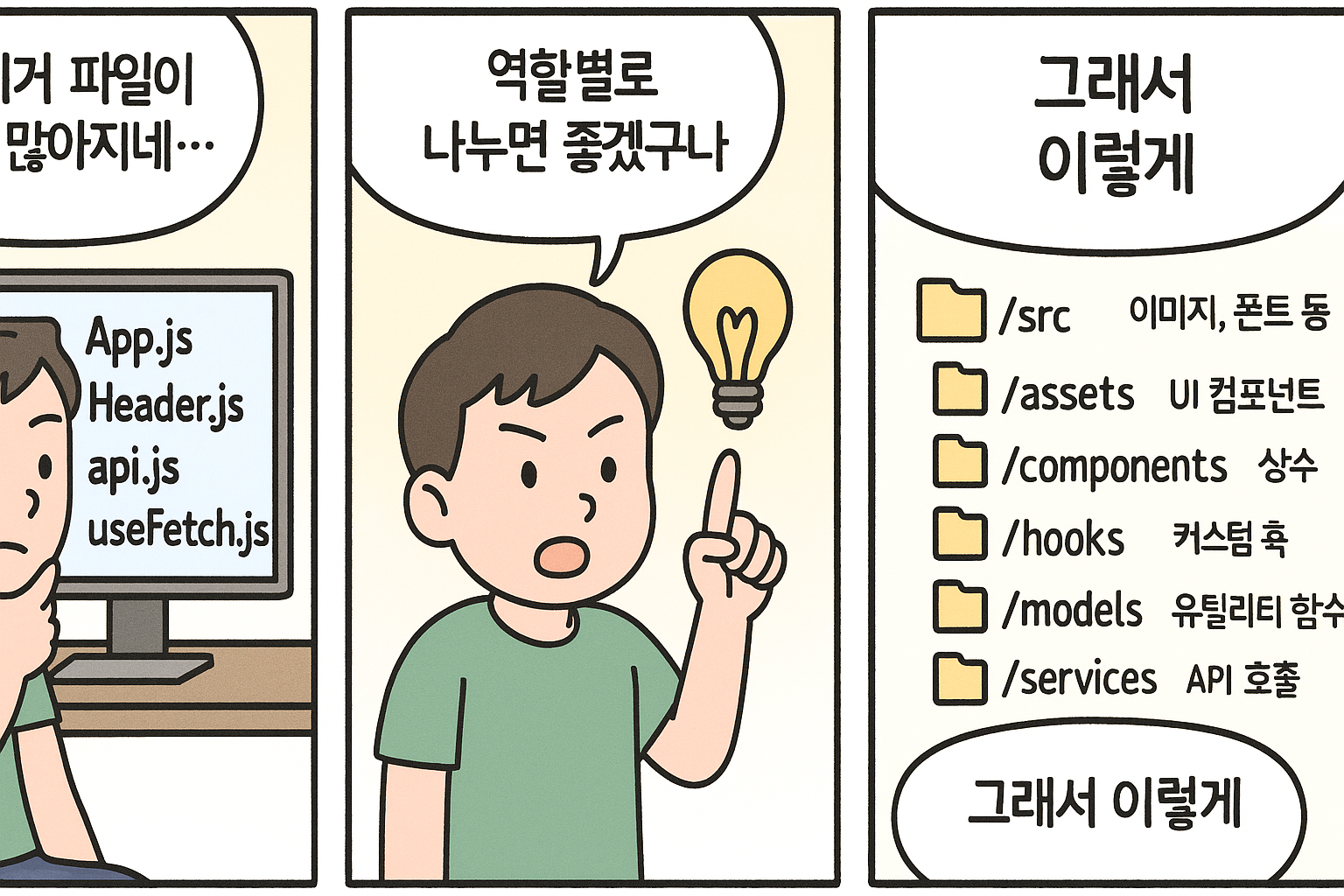
전통적인 역할 기반 폴더 구조
대부분의 프론트엔드 프로젝트는 대부분 비슷한 출발점에서 시작합니다. 바로 가장 직관적이고 이해하기 쉬운 역할별 폴더 구조입니다. /components, /hooks, /services, /utils 등 여러분도 이름만 보아도 아주 익숙하죠.
/src
/assets # 이미지, 폰트 등
/components # UI 컴포넌트
/constants # 상수
/hooks # 커스텀 훅
/models # 유틸리티 함수
/services # API 호출
/utils # 유틸리티 함수이러한 구조는 처음 시작할 때 매우 자연스럽고 명확합니다. "이건 UI 컴포넌트니까 components에, 이건 API 통신이니까 services에" 하는 식으로 직관적으로 파일을 분류할 수 있습니다. 그래서 대부분의 튜토리얼이나 스타터 키트들도 이런 구조를 채택하고 있고 입문자에게도 아주 친숙합니다.
작은 프로젝트나 시작 단계에서는 이 구조가 특히나 효과적입니다. 파일 수가 적고, 각 폴더의 역할이 명확하며, 특정 종류의 코드를 찾기 쉽기 때문입니다. 개발을 시작할 때 정신적 부담 없이 코드를 쉽게 나눌 수 있는 구조라고 할 수 있겠습니다.
파일 증가에 따른 하위 폴더 세분화가 필요해졌다.
프로젝트가 성장하면서 첫 번째로 마주하는 문제는 각 폴더 내 파일 수가 많아진다는 것입니다. 파일이 지나치게 쌓이면 관리가 어려워집니다. 한 폴더에 10개~20개씩 컴포넌트가 모여있으면 어지럽게 느껴지죠. 재밌는 사실은 저는 폴더구조로 찾아가기 보다는 파일찾기 기능을 통해서 접근을 하기에 사실상 하나의 거대한 구조임에도 가끔씩 그걸 볼때마다 스트레스를 받습니다.

아마 저만 그런 것은 아닐걸닙니다. 인간의 뇌는 구체적인 정보들이 빽빽하게 나열되어 있는 것을 싫어하고 예측가능하고 체계가 있는 구조를 선호한다고 합니다. 그래서인지 한 폴더에 파일이 많아지게 되면 보다보다 거슬림을 참지(?) 못하고 자연스럽게 다음과 같이 하위 폴더를 만들기 시작합니다. 의식하지 않아도 인지적 부담이 쌓이고 피로도가 높아지는 것이죠.
그러다 보면 /components , /hooks , /services, /utils , /libs 와 같은 폴더들의 세부구조를 어떻게 나눌지 고민을 하게 됩니다. 그리고 이게 참 어렵습니다. 왜내하면 이 단계의 세부 폴더 구조에 대해서는 정형화된 규칙도 없고 프로젝트마다 달라지다 보니 어떻게 해야 좋을지 판단의 기준이 모호해지기 때문이죠.
# 역할별 폴더의 하위구조를 어떻게 가져가야 할까?
/components
/ui # 기본 UI 컴포넌트 (버튼, 인풋 등)
/layout # 레이아웃 관련 컴포넌트
/icons # 아이콘 컴포넌트
/form # 폼 관련 컴포넌트
...
/hooks
/form # 폼 관련 훅
/auth # 인증 관련 훅
/api # API 관련 훅
...프론트엔드의 주된 역할은 화면을 중심으로 이루어지는 만큼 대부분의 파일들이 컴포넌트로 되어 있기에 대개 폴더 구조의 세분화의 시작의 주인공은 바로 /components 가 됩니다.
Atomic Design Pattern: 컴포넌트 계층 구조화의 시도
사실 이러한 계층과 구조화에 대한 생각은 프론트엔드 개발자라면 피해갈 수 없습니다. 체계가 없는 구조에서 개발을 한다는 것은 상당해 인지적 소모가 큰 행동이니까요. 그리고 여러가지 모델들이 제안이 되는데 컴포넌트 분류에서 인기가 많았던 것이 바로 Atomic Design Pattern 이었습니다.
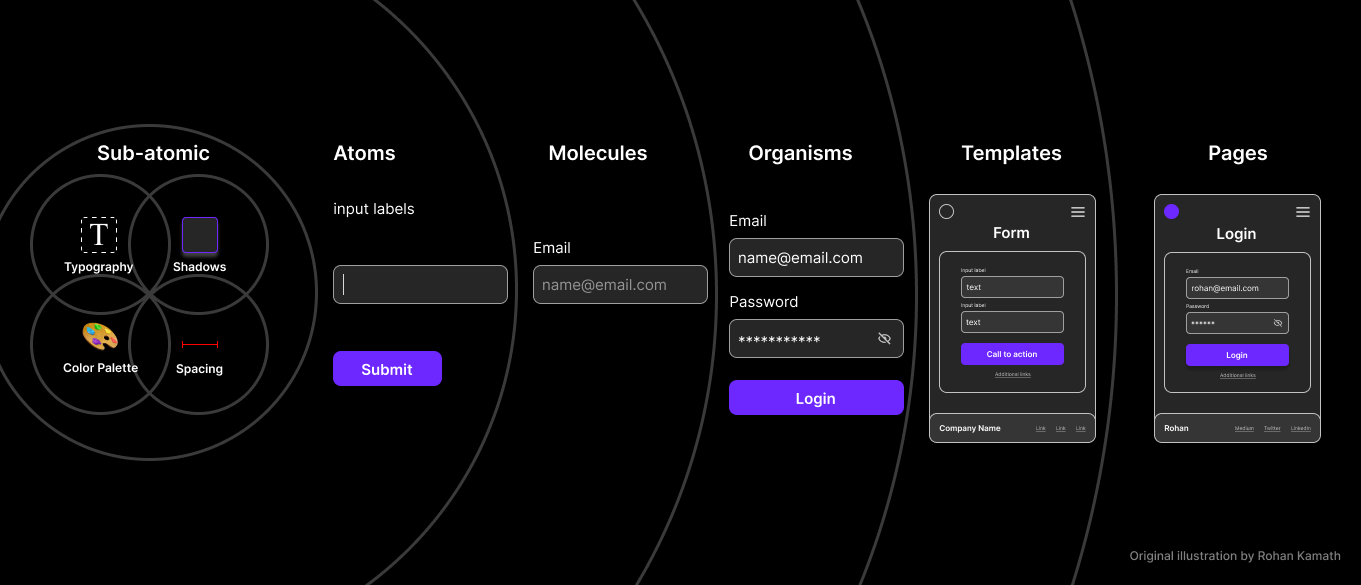
Atomic Design Pattern은 UI 컴포넌트를 구성하는 직관적인 방법론으로, 컴포넌트를 다음과 같은 계층으로 분류합니다:
- 원자(Atoms): 버튼, 입력 필드, 레이블과 같은 기본 UI 요소
- 분자(Molecules): 원자들의 조합으로, 폼 필드, 검색 바와 같은 단일 기능 컴포넌트
- 유기체(Organisms): 분자들의 조합으로, 제품 카드, 내비게이션 바와 같은 복잡한 컴포넌트
- 템플릿(Templates): 페이지의 구조를 정의하는 와이어프레임
- 페이지(Pages): 실제 콘텐츠가 채워진 완성된 화면
어렵지 않고 직관적인 개념에 원자가 모여 분자가 되고, 분자가 모여 유기체가 된다는 이해하기 쉬운 비유적인 네이밍을 하고 있기 때문에 많은 사람들에게 주목을 받았습니다.
Atomic Design Pattern은 사실 디자인 시스템을 효과적으로 구축하기 위해 제안된 체계이기에, 개발자들 역시 디자인 시스템을 구축하거나 사용하기 마련이니 이러한 체계를 폴더 구조를 통해 UI 요소 간의 계층적 관계를 명확히하고 일관성을 유지하는 데 도움을 받고자 했습니다. 그래서 Atomic Design Pattern을 적용한 폴더구조는 다음과 같이 표현될 수 있겠습니다.
/components
/atoms # 기본 요소
Button.tsx
Input.tsx
Label.tsx
/molecules # 간단한 조합
FormField.tsx
SearchBar.tsx
/organisms # 복잡한 조합
ProductCard.tsx
NavigationBar.tsx
/templates # 페이지 템플릿
ProductDetailTemplate.tsx
/pages # 전체 페이지
ProductDetailPage.tsx그런데 이러한 폴더 구조는 실무에서 효과가 있었을까요? 정답은 "반은 그렇고 반은 그렇지 않다"였습니다.
https://velog.io/@teo/Atomic-Design-Pattern
Atomic Design Pattern의 Best Practice 여정기
실제 프로젝트의 폴더구조에 Atomic Design을 적용해보면 유용함과 한계점을 모두 마주하게 됩니다. 분명 디자인 시스템을 직관적으로 보여주는데, 어디서 문제가 되는 걸까요? 한번 ProductCard 같은 컴포넌트를 생각해봅시다. ProductCard는 어디에 두어야 할까요? 내부적으로 Card와 Button을 사용하니 atom은 당연히 아닌 것 확실한데... 그래서 간단한 원자들로 조립했으니 molecules일까요? 아니면 비즈니스 로직을 포함하고 복잡하니 organisms?

문제은 이 뿐만이 아닙니다. 이렇게 원자 - 분자 - 유기체 이렇게 3개의 폴더 구조만으로는 점점 더 많아지는 컴포넌트들을 감당하기가 어려워 집니다.
/components
/mocules
ProductCard.tsx
UserCard.tsx
PostCard.tsx
CommentCard.tsx
OrderCard.tsx
ReviewCard.tsx
NotificationCard.tsx
// ... 계속 늘어나는 파일들
/organisms
ShoppingCart.tsx
NavigationBar.tsx
Header.tsx
Footer.tsx
ProductList.tsx
UserList.tsx
PostList.tsx
// ... 계속 늘어나는 파일들그러다보면 다시 세부 폴더가 필요한 상황이 됩니다. 그런데 여기서 또 고민이 시작됩니다
# 어떤 방식이 맞을까?
# 방식 1: 계층 내 도메인별 세분화
/organisms
/product
ProductCard.tsx
ProductList.tsx
/user
UserCard.tsx
UserList.tsx
# 방식 2: 도메인 내 계층 세분화
/product
/molcues
ProductCard.tsx
UserCard.tsx
/organisms
ProductList.tsx왜 이런 문제가 생기는 걸까요? 그 이유는 Atomic Design Pattern이 간과한 중요한 점이 있었습니다. 바로 모든 컴포넌트를 단순히 계층만으로 분류할 수 없다는 것이었죠. Atomic Design Pattern은 디자인 시스템에는 적합했지만, 실제 프로젝트의 컴포넌트들은 디자인 시스템에서 말하는 UI 컴포넌트로만 되어 있는 것이 아니었기 때문입니다.
컴포넌트의 두 가지 본질: 순수 UI와 도메인 컴포넌트
프론트엔드 개발에는 근본적으로 두 가지 다른 종류의 컴포넌트가 존재합니다. 디자인 시스템을 구성하는 순수한 UI 컴포넌트가 있다면, 그 컴포넌트들을 활용해서 비즈니스 로직을 구동하는 도메인 컴포넌트도 존재합니다. Atomic Design Pattern은 디자인 시스템의 계층(atoms, molecules, organisms)을 표현하기에는 유용했지만, 또 다른 중요한 축인 도메인(product, user, order)을 다루는 컴포넌트들을 제대로 분류하지 못한다는 한계가 있었습니다.
도메인이란 무엇일까요? 도메인이란 비즈니스에서 다루는 개념적 영역을 말합니다. 쇼핑몰을 예로 들면 '제품', '장바구니', '사용자', '주문' 등이 주요 도메인이 됩니다. 그리고 제품목록, 주문내역, 사용자 다이얼로그 등이 바로 도메인정보를 다루는 컴포넌트, 즉 도메인 컴포넌트가 되겠습니다.
도메인 정보를 다루는 컴포넌트들은 기존의 버튼, 드롭다운, 모달 같은 순수한 화면 요소를 다루는 것에서 확장되면서 어떤 차이점을 가지고 있는지 한번 자세히 알아보겠습니다.
컴포넌트는 재사용이 가능하도록 작성하는 것이 원칙인데...
웹 개발 방식이 컴포넌트 기반 개발이 주류가 되면서, "컴포넌트는 재사용 가능해야 한다"는 원칙이 프론트엔드 개발의 핵심 철학으로 자리잡았습니다. 개발자들은 반복되는 버튼, 카드, 입력필드등에서의 중복 코드를 줄이고 일관된 UI를 구현하고 싶어했습니다. 그러면서도 컴포넌트를 최대한 독립적으로 만들려고 노력했고, 공통 코드는 모으되 props를 통해 외부에서 모든 것을 주입받도록 설계하는 것이 베스트 프랙티스로 여겨졌습니다.
function Button({ children, onClick, variant, size, disabled }) {
return (
<button
className={`btn btn-${variant} btn-${size}`}
onClick={onClick}
disabled={disabled}
>
{children}
</button>
);
}Button 같은 순수 UI 컴포넌트에서 이 접근법은 주효했습니다. 어디서든 사용할 수 있었고, 로그인 버튼이든, 장바구니 추가 버튼이든, 삭제 버튼이든 상관없이 일관된 동작을 보여주었습니다. 필요에 따라서 적절히 props를 통해서 공통 코드를 재사용하면서도 커스텀도 가능해지면서 컴포넌트를 "재사용성"이라는 원칙을 지키도록 작성하는 것은 중요한 덕목이 되었습니다.
그러나... 도메인 컴포넌트에서 발견한 예상치 못한 문제들
이런 경험을 바탕으로 개발자들은 자연스럽게 다른 컴포넌트에도 같은 원칙을 적용하기 시작했습니다. 가령 상품 목록 리스트 항목을 그리는 ProductItem 같은 도메인 컴포넌트가 검색결과나 카탈로그, 찜 목록 등에 사용되니 다음과 같이 만들어 props를 통해 적절히 원하는대로 커스텀이 가능하도록 만들어 보았습니다.
function ProductItem({ product, onAddToCart, onToggleFavorite, showPrice, showRating }) {
return (
<div className="product-item">
<img src={product.image} alt={product.name} />
<h3>{product.name}</h3>
{showPrice && <span>{product.price}</span>}
{showRating && <Rating value={product.rating} />}
<Button onClick={() => onAddToCart(product)}>장바구니</Button>
<Button onClick={() => onToggleFavorite(product)}>♡</Button>
</div>
);
}이러한 방식은 초기에는 잘 작동했습니다. 두 화면 모두에서 ProductItem을 재사용할 수 있었고, 옵션에 따라 원하는 필드의 노출이나 기능을 달리 할 수 있었죠. Button에서처럼 컴포넌트의 재사용이라는 목표를 달성하는 것 같았습니다.
하지망 프로젝트가 복잡해지면서 컴포넌트의 재사용성에 대한 의문이 생기기 시작했습니다. 가령 장바구니에서는 수량 조절이, 위시리스트에서는 다른 UI가 필요해지니 아래와 같이 재사용을 하기 시작했습니다.
// 처음엔 간단했는데...
<ProductItem product={product} />
// 장바구니용 기능이 필요해지니...
<ProductItem product={product} showQuantity={true} onQuantityChange={handleQuantity} />
// 위시리스트용도 추가하니...
<ProductItem
product={product}
variant="wishlist"
showDate={true}
showPriceAlert={true}
onRemove={handleRemove}
/>각각의 새로운 요구사항마다 props를 추가하는 것이 재사용이라는 측면에서는 당연한 조치였지만 예상과는 달리 코드는 점점 더 복잡해져갔습니다. props가 늘어날수록 컴포넌트를 사용하기가 더 어려워졌고, 내부 로직은 조건문으로 가득해졌습니다. 또한 새로운 기능을 추가할 때마다 다른 variant에서는 문제가 없는지 계속 확인해야 했죠.
나중에야 알게 된 사실이지만 이런 유형의 컴포넌트들은 전통적인 방식으로는 재사용리 잘 되지 않습니다. 카탈로그의 ProductItem과 장바구니의 ProductItem은 겉보기에 같은 컴포넌트였지만 실제로는 다른 목적과 동작을 가지고 있었습니다. 그럼에도 하나의 컴포넌트로 억지로 묶어두다 보니 둘 다 최적화되지 못한 어정쩡한 결과물이 나온 것입니다.
같은 화면, 다른 도메인: 만능 컴포넌트의 한계
구체적으로 잘못된 재사용을 하는 경우란 데이터가 다른 데도 같은 UI를 사용한다는 이유로 하나의 컴포넌트로 추상화를 하는 방식입니다.
가령 게시판를 만든다고 생각해 봅시다. 공지사항, 문의게시판, 방명록 등이 프로젝트 전체에서 유사한 기능과 화면을 가지고 있으니 이를 하나의 컴포넌트로 만들어 API나 일부 화면만 분기하는 방식으로 재사용을 하려고 합니다.
그래서 다음과 같이 BoardList와 같은 컴포넌트를 만들고 API와 타입 등을 받아서 다른 데이터들을 일부 분기되는 처리와 옵션을 달리 하는 방식으로 만들어 보았습니다.
function BoardList({
boardType,
apiEndpoint,
showAuthor = true,
showCategory = false,
allowReply = false
}) {
const { data: posts } = useFetch(apiEndpoint);
return (
<div className="board-list">
{posts?.map(post => (
<div key={post.id} className="board-item">
<h3>{post.title}</h3>
{showAuthor && <span>작성자: {post.author}</span>}
{showCategory && <span>분류: {post.category}</span>}
<span>{post.createdAt}</span>
{allowReply && <ReplyButton postId={post.id} />}
</div>
))}
</div>
);
}
// 사용 예시
<BoardList boardType="notice" apiEndpoint="/api/notices" showCategory={true} />
<BoardList boardType="qna" apiEndpoint="/api/qna" allowReply={true} />
<BoardList boardType="guestbook" apiEndpoint="/api/guestbook" showAuthor={false} />이러한 방식은 얼핏 괜찮은 방식처럼 보입니다. 실제로 더 이상 프로젝트가 변하지 않거나 이 요구사항으로만 모든 기획을 처리해야할때 까지는 맞는 이야기입니다. 이 하나의 컴포넌트로 여러 종류의 게시판을 처리할 수 있었고, 코드 중복도 줄일 수 있었죠. 하지만 문제는 서비스가 잘되면 프로젝트와 요구사항은 언제나 변하고 커진다는 데에 있습니다.
요구사항은 화면이 아니라 도메인에 따라 방향성이 달라집니다. 공지사항은 '중요' 배지 기능을 요구했고, 문의 게시판은 답변 상태나 비밀글 기능이 필요했으며, 방명록은 본문 미리보기도 같이 보여달라는 등 처음에는 같은 화면이었지만 점점 요구사항이 특수성에 따라 달라지는 것이고 이는 도메인의 특성에 기인하는 것이죠.
만일 현명하게 이를 대처하고자 했다면 BoardList는 데이터와 무관하게 화면과 기능을 확장할 수 있도록 하고 props가 아니라 다양한 컴포넌터를 조립할 수 있도록 만들어야 합니다. 그리거 각자 도메인별로는 코드의 중복을 인정하고 BoardList를 활용해서 각자의 방식으로 독립적으로 발전 할 수 있는 구조로 만들어야 하죠.
도메인 컴포넌트를 관리하기 위한 접근법 - 로직과 화면의 분리
이러한 시행착오를 겪으면서 개발자들은 컴포넌트를 다음과 같이 2가지로 구분을 하면 더 좋다는 것을 알게 되었습니다.
순수 UI 컴포넌트:
- Button, Input, Modal, Dropdown 등
- 도메인 지식이 전혀 필요 없음
- 어떤 맥락에서든 동일하게 동작
- 높은 재사용성이 가능하고 재사용성을 갖추는게 바람직한 방향
- 디자인 시스템의 변화를 따라감
도메인 컴포넌트:
- ProductItem, UserProfile, OrderSummary 등
- 특정 비즈니스 도메인의 개념을 표현
- 맥락에 따라 다른 UI와 동작이 필요
- 컴포넌트의 재사용이 중요한 가치가 아님
- 비즈니스 요구사항의 변화를 따라감
우리가 얻은 교훈은 요구사항은 도메인을 중심으로 발전한다는 것이었습니다. 그렇기에 같은 화면을 가진 컴포넌트라도 코드가 중복되더라도 도메인에 따라 분리하는 것이 장기적으로 더 유지보수하기 좋은 방향이 되는만큼, 도메인을 다루는 컴포넌트와 UI를 다루는 컴포넌트는 서로 다른 관점에서 접근하고 이를 분리해서 관리하는 방향으로 진화하게 되었습니다.
Container - Presenter Pattern
그렇다면 도메인 컴포넌트를 더 잘 만들기 위해서는 어떻게 해야 할까요? 문제의 핵심은 도메인 컴포넌트에 비즈니스 로직이 섞여 있다는 점이었습니다. 이를 해결하기 위해 컨테이너-프레젠터 패턴이 등장했습니다.
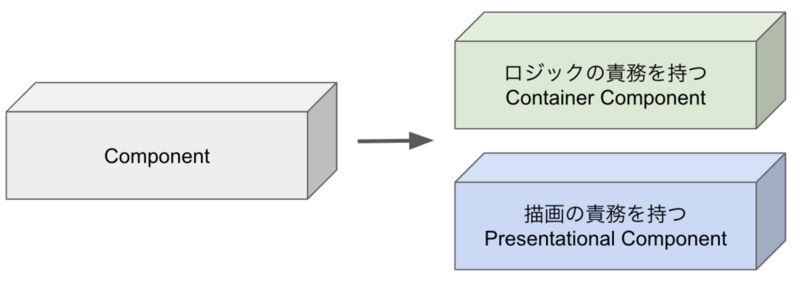
이 패턴의 핵심은 로직을 담당하는 컨테이너 컴포넌트와 UI만 담당하는 프레젠터 컴포넌트를 분리하는 것이었습니다.
// 프레젠터: 순수하게 UI만 담당
function ProductItemView({
product,
isInCart,
isFavorite,
onAddToCart,
onToggleFavorite
}) {
return (
<div className="product-item">
<img src={product.image} alt={product.name} />
<h3>{product.name}</h3>
<span>{product.price}</span>
<Button
onClick={onAddToCart}
disabled={isInCart}
>
{isInCart ? '이미 담김' : '장바구니'}
</Button>
<Button
onClick={onToggleFavorite}
variant={isFavorite ? 'filled' : 'outline'}
>
♡
</Button>
</div>
);
}
// 컨테이너: 로직을 담당
function CatalogProductItem({ product }) {
const { addToCart, isInCart } = useCart();
const { toggleFavorite, isFavorite } = useFavorites();
const handleAddToCart = () => {
addToCart(product);
// 카탈로그 특화 로직: 추천 시스템에 데이터 전송
analytics.track('product_added_from_catalog', { productId: product.id });
};
const handleToggleFavorite = () => {
toggleFavorite(product);
// 카탈로그 특화 로직
analytics.track('product_favorited_from_catalog', { productId: product.id });
};
return (
<ProductItemView
product={product}
isInCart={isInCart(product.id)}
isFavorite={isFavorite(product.id)}
onAddToCart={handleAddToCart}
onToggleFavorite={handleToggleFavorite}
/>
);
}
// 장바구니용 컨테이너는 완전히 다른 로직
function CartProductItem({ item }) {
const { updateQuantity, removeItem } = useCart();
const handleQuantityChange = (newQuantity) => {
updateQuantity(item.id, newQuantity);
analytics.track('cart_quantity_updated', {
productId: item.product.id,
quantity: newQuantity
});
};
// 장바구니에는 ProductItemView가 아닌 완전히 다른 UI 사용
return (
<div className="cart-item">
<img src={item.product.image} alt={item.product.name} />
<div className="item-details">
<h4>{item.product.name}</h4>
<span>{item.product.price} × {item.quantity}</span>
</div>
<QuantitySelector
value={item.quantity}
onChange={handleQuantityChange}
/>
<Button onClick={() => removeItem(item.id)}>삭제</Button>
</div>
);
}이런 접근법은 각 컨테이너가 자신의 맥락에 최적화된 로직을 가질 수 있게 해주었습니다. 카탈로그에서는 "구매 유도"에, 장바구니에서는 "수량 관리"에 집중할 수 있었죠.
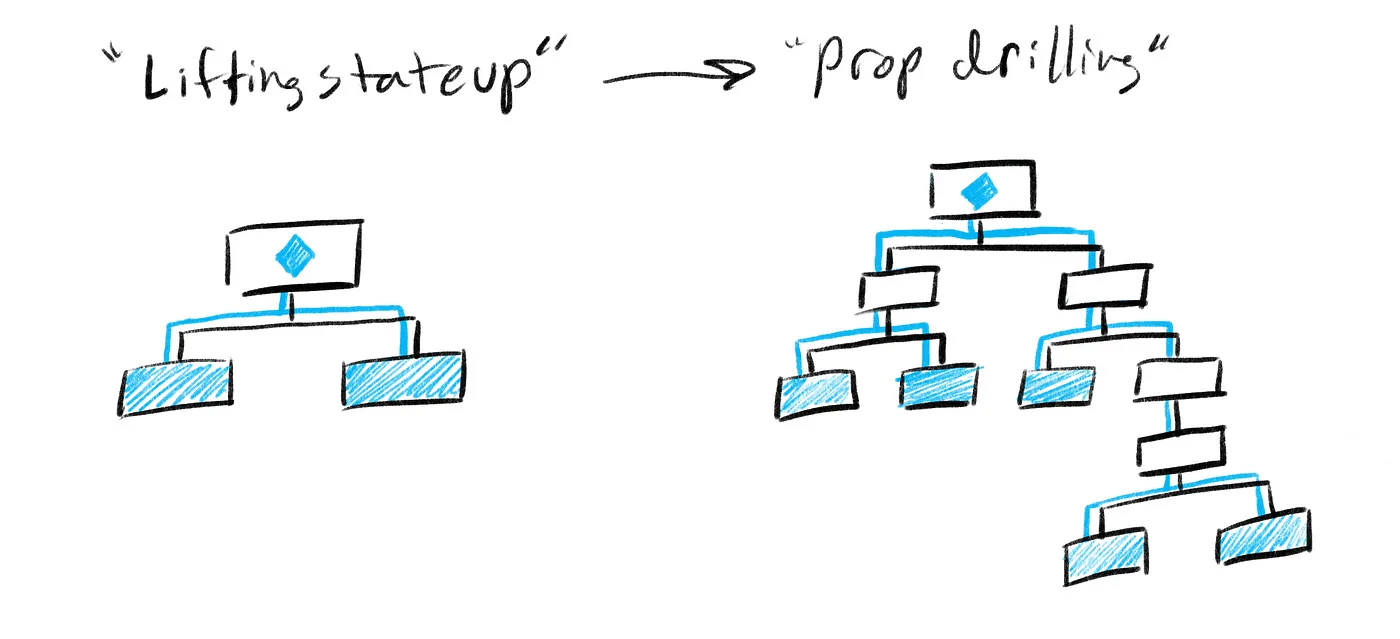
Props Drilling Problem과 전역 상태 관리의 필요성
하지만 컨테이너-프레젠터 패턴으로도 해결되지 않는 문제가 있었습니다. 바로 Props Drilling이었습니다. 독립성을 위해 필요한 데이터와 함수들을 계속 props로 전달해야 했고, 중간 계층 컴포넌트들은 실제로는 데이터 전달만 하면서도 모든 props를 받아서 다시 전달해야 했습니다.
function ProductSection({ products, onAddToCart, onToggleFavorite }) {
return (
<ProductList
products={products}
onAddToCart={onAddToCart}
onToggleFavorite={onToggleFavorite}
/>
);
}
function ProductList({ products, onAddToCart, onToggleFavorite }) {
return (
<div>
{products.map(product => (
<ProductItem
key={product.id}
product={product}
onAddToCart={onAddToCart}
onToggleFavorite={onToggleFavorite}
/>
))}
</div>
);
}중간 계층의 컴포넌트들은 실제로는 데이터를 전달하는 역할만 하면서도, 독립성을 위해 모든 props를 받아서 다시 전달해야 했습니다. 재사용은 되지 않으면서 복잡도만 증가하는 상황이 벌어진 것입니다. 이는 UI 컴포넌트를 만들때에는 발생하지 않던 개념이었습니다.
새로운 아키텍처 패턴으로의 발전: 전역상태관리
이런 문제들을 해결하기 위해 프론트엔드 커뮤니티에서는 여러 패턴들이 자연스럽게 발전했습니다. Container-Presenter 패턴은 로직과 UI를 명확히 분리하려는 시도였고, 커스텀 훅의 부상은 비즈니스 로직을 컴포넌트에서 분리하여 재사용 가능한 형태로 만드는 패턴이었습니다. Context API와 전역 상태 관리는 Props drilling 문제를 해결하고 도메인 상태를 효율적으로 관리하기 위한 패턴들이었습니다.
// 전역 상태를 활용한 도메인 컴포넌트
function CatalogProductItem({ product }) {
// props drilling 없이 직접 필요한 로직에 접근
const { addToCart, isInCart } = useCart();
const { toggleFavorite, isFavorite } = useFavorites();
return (
<div className="product-item">
<img src={product.image} alt={product.name} />
<h3>{product.name}</h3>
<span>{product.price}</span>
<Button onClick={() => addToCart(product)}>
{isInCart(product.id) ? '이미 담김' : '장바구니'}
</Button>
<Button onClick={() => toggleFavorite(product.id)}>
{isFavorite(product.id) ? '❤️' : '♡'}
</Button>
</div>
);
}이런 패턴들이 등장한 배경에는 공통된 인식이 있었습니다. 도메인 컴포넌트는 props drilling 없이 필요한 도메인 로직에 직접 접근할 수 있어야 한다는 것이었습니다. 이는 기존의 "모든 것을 props로"라는 패러다임에서 "필요한 것을 직접 가져오기"라는 패러다임으로의 전환을 의미했습니다.
프론트엔드의 이원성: 도메인과 비도메인
컴포넌트를 통해 발견한 "순수 UI"와 "도메인"의 구분은 사실 컴포넌트만의 이야기가 아니었습니다. 프로젝트가 성장하면서 이런 구분이 프론트엔드 개발의 모든 영역에서 나타나기 시작했죠.
훅(Hooks)에서도 마찬가지였습니다. useToggle(), useDebounce(), useClickOutside() 같은 훅들은 어떤 도메인 지식도 필요 없는 순수한 유틸리티 훅이었습니다. 반면 useCart(), useAuth(), useProductSearch() 같은 훅들은 특정 비즈니스 로직과 밀접하게 연관되어 있었죠.
// 순수 유틸리티 훅 - 어디서든 사용 가능
function useDebounce(value: string, delay: number) {
const [debouncedValue, setDebouncedValue] = useState(value);
useEffect(() => {
const handler = setTimeout(() => setDebouncedValue(value), delay);
return () => clearTimeout(handler);
}, [value, delay]);
return debouncedValue;
}
// 도메인 훅 - 장바구니 비즈니스 로직 포함
function useCart() {
const dispatch = useDispatch();
const items = useSelector(selectCartItems);
const addToCart = (product: Product) => {
dispatch(cartActions.add(product));
analytics.track('cart.item_added', { productId: product.id });
};
return { items, addToCart, totalPrice: calculateTotal(items) };
}API 레이어에서도 동일한 패턴이 보였습니다. httpClient.get(), httpClient.post() 같은 기본 HTTP 통신 유틸리티와 productApi.getAll(), cartApi.checkout() 같은 도메인 특화 API는 성격이 완전히 달랐습니다. 전자는 어떤 프로젝트에서도 그대로 사용할 수 있지만, 후자는 해당 도메인의 비즈니스 규칙을 반영하고 있었죠.
심지어 유틸리티 함수들도 마찬가지였습니다. formatDate(), debounce(), deepClone() 같은 범용 유틸리티와 calculateShippingFee(), validateProductCode(), formatProductPrice() 같은 도메인 유틸리티는 근본적으로 다른 성격을 가지고 있었습니다.
역할 기반 구조의 세부 진화
이런 발견은 자연스럽게 폴더 구조에도 반영되기 시작했습니다. 처음에는 단순히 /components, /hooks, /services, /utils로 나누었지만, 각 폴더 내부에서는 도메인을 기준으로 세분화가 일어났죠.
/hooks
/ui # 순수 UI 관련 훅
useModal.ts
useDebounce.ts
useToggle.ts
/product # 제품 도메인 훅
useProducts.ts
useProductDetail.ts
/cart # 장바구니 도메인 훅
useCart.ts
useCheckout.ts
/services
/common # 기본 API 클라이언트
client.ts
interceptors.ts
/product # 제품 도메인 API
productApi.ts
/cart # 장바구니 도메인 API
cartApi.ts그리고 페이지 컴포넌트의 독립
컴포넌트는 도메인 중심의 세분화가 정착되면서 폴더 구조는 한층 체계적이 되었습니다. 하지만 여전히 해결되지 않은 불편함이 하나 있었죠. 바로 페이지 컴포넌트의 애매한 위치였습니다.
React로 처음 프로젝트를 시작했던 시절에는 모든 컴포넌트를 단순히 /components 폴더 안에 넣었습니다. HomePage, ProductListPage 같은 페이지 컴포넌트도, Button이나 Modal 같은 일반 컴포넌트도 모두 한 곳에 있었죠. 이름에 'Page'를 붙여서 구분하려 했지만, 프로젝트가 커질수록 이런 네이밍 컨벤션만으로는 부족했습니다.
/components
Button.tsx
Modal.tsx
Header.tsx
HomePage.tsx # 페이지? 컴포넌트?
LoginPage.tsx
ProductCard.tsx
ProductListPage.tsx # 이름으로만 구분
ProductDetailPage.tsx
CartIcon.tsx
CartPage.tsx
UserProfile.tsx
UserSettingsPage.tsx더 큰 문제는 라우팅 설정과 실제 컴포넌트 사이의 거리였습니다. React Router 설정은 보통 App.js나 별도의 routes.js 파일에 있었고, 실제 페이지 컴포넌트는 components 폴더 깊숙한 곳에 있었죠. 새로운 개발자가 "이 URL은 어떤 컴포넌트를 렌더링하지?"라는 질문을 받으면, 라우팅 설정 파일을 열어보고, 거기서 import 경로를 따라가서, 해당 컴포넌트를 찾아야 했습니다. 단순해 보이지만 은근히 번거로운 과정이었죠.
페이지 컴포넌트는 분명 다른 컴포넌트들과는 다른 역할을 했습니다. URL과 직접 연결되고, 데이터 페칭의 시작점이 되며, SEO와 관련된 메타데이터를 설정하는 곳이었죠. 하지만 폴더 구조상으로는 이런 특별함이 전혀 드러나지 않았습니다. Button 컴포넌트 옆에 HomePage 컴포넌트가 나란히 있는 것은 뭔가 어색했습니다.
페이지의 독립: 파일 기반 라우팅
이런 불편함을 해소한 것이 바로 파일 기반 라우팅이었습니다. 파일 시스템의 구조가 곧 URL 구조가 된다는 간단한 아이디어였지만, 그 영향력은 대단했습니다. 이제 /pages/products/[id].tsx 파일을 만들면 자동으로 /products/:id 라우트가 생성되었습니다.
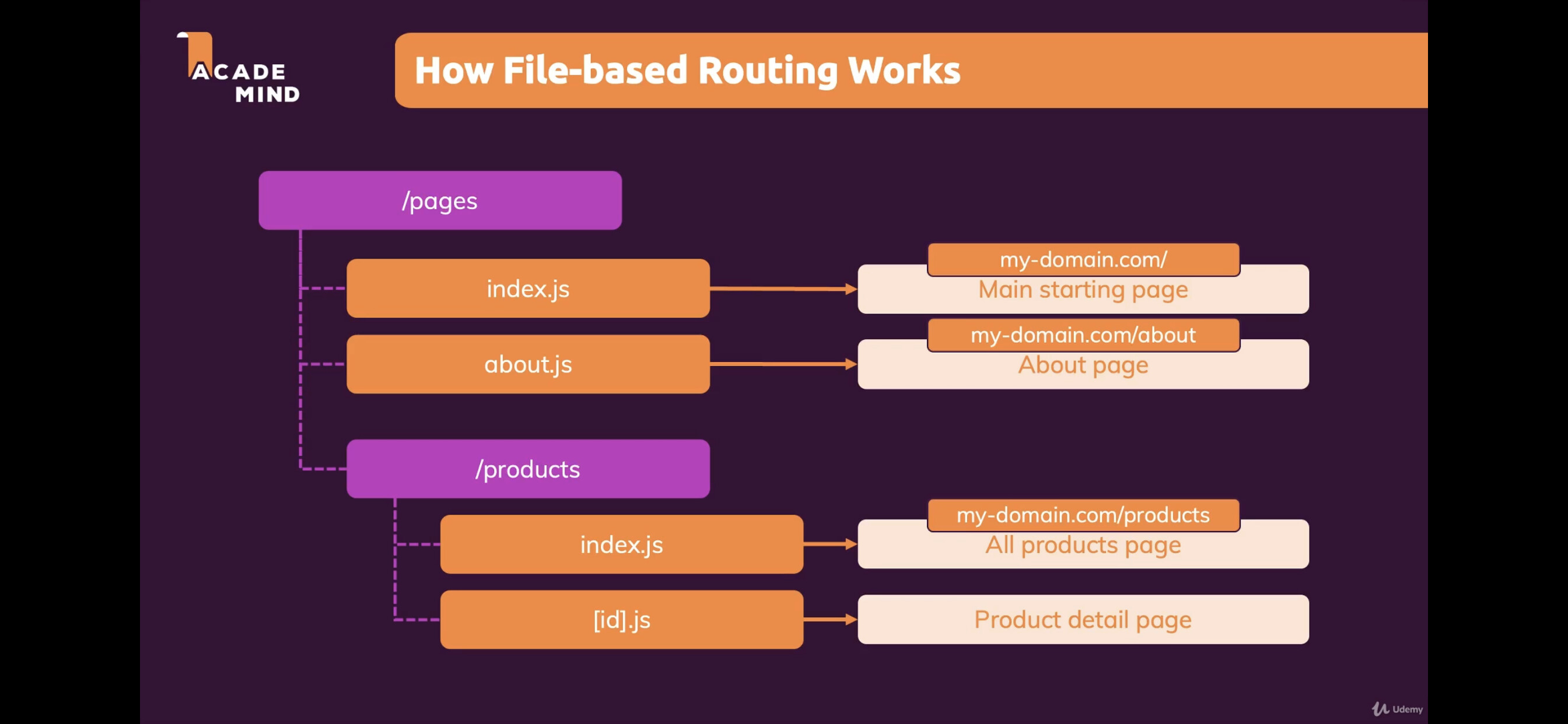
이와 같은 방법은 라우팅 설정을 별도로 관리할 필요가 없었고, URL만 보면 어떤 파일을 찾아가야 하는지 즉시 알 수 있었죠. 이는 단순히 편의성의 문제가 아니었습니다. 페이지라는 개념이 다른 컴포넌트들과는 본질적으로 다른 역할을 한다는 것을 구조적으로 개념화 한것이죠.
페이지는 애플리케이션의 진입점입니다. 사용자가 URL을 통해 직접 접근하는 곳이고, SEO가 중요한 곳이며, 데이터 페칭이 시작되는 곳이죠. 이런 특별한 역할을 하는 컴포넌트들을 일반 컴포넌트와 같은 폴더에 두는 것은 그 중요성을 제대로 반영하지 못한 것이었습니다.
현대의 일반적인 폴더 구조 - 역할별 분류, 도메인별 세분화, 그리고 페이지
이렇게 역할별 분류, 도메인별 세분화, 그리고 페이지의 독립이라는 세 가지 진화가 만나면서 현대 프론트엔드 프로젝트의 일반적인 구조가 형성되었습니다. 대부분의 스타터 키트나 보일러플레이트를 열어보면 비슷한 패턴을 발견할 수 있죠.
/src
/pages (또는 /app) # 라우팅 진입점
index.tsx
about.tsx
/products
index.tsx
[id].tsx
/cart
index.tsx
checkout.tsx
/auth
login.tsx
register.tsx
/components # UI 컴포넌트
/ui # 순수 UI (도메인 무관)
Button.tsx
Modal.tsx
Card.tsx
Input.tsx
/product # 제품 도메인
ProductCard.tsx
ProductList.tsx
/cart # 장바구니 도메인
CartItem.tsx
CartSummary.tsx
/layout # 레이아웃 컴포넌트
Header.tsx
Footer.tsx
Sidebar.tsx
/hooks # 커스텀 훅
/ui
useModal.ts
useDebounce.ts
/product
useProducts.ts
useProductDetail.ts
/cart
useCart.ts
/auth
useAuth.ts
usePermissions.ts
/services # API 레이어
/api
client.ts
interceptors.ts
/product
productApi.ts
/cart
cartApi.ts
/auth
authApi.ts
/store # 상태 관리
/slices
productSlice.ts
cartSlice.ts
authSlice.ts
store.ts
/utils # 유틸리티
/common
formatters.ts
validators.ts
constants.ts
/product
priceCalculator.ts
/date
dateHelpers.ts
/types # TypeScript 타입 정의
/models
product.ts
user.ts
cart.ts
/api
responses.ts
requests.ts
/styles # 스타일 파일
/globals
reset.css
variables.css
/components
button.module.css
/assets # 정적 리소스
/images
/fonts
/icons최상위에는 여전히 components, hooks, services 같은 역할별 폴더들이 있습니다. 하지만 이제 각 폴더 내부를 들여다보면 ui, product, cart 같은 도메인별 하위 폴더들이 있죠. 그리고 pages나 app 폴더는 독립적으로 존재하며 라우팅 구조를 담당합니다.
이런 구조에서 개발자의 사고 흐름은 대체로 이렇습니다. "장바구니에 상품을 추가하는 훅이 필요해. 그러면 hooks 폴더로 가서, cart 하위 폴더를 찾아보자." 또는 "제품 상세 페이지를 수정해야 해. pages 폴더의 products 아래에 있겠군." 역할이라는 큰 분류 아래 도메인이라는 세부 분류가 있는 이중 구조는 직관적이면서도 체계적이었습니다.
특히 이 구조가 인기를 얻은 이유는 점진적인 확장이 가능했기 때문입니다. 처음에는 단순히 components와 pages만으로 시작할 수 있습니다. 프로젝트가 커지면서 hooks 폴더가 추가되고, API 호출이 복잡해지면 services가 생기고, 상태 관리가 필요하면 store가 추가되는 식이죠. 각 단계에서 기존 구조를 크게 바꾸지 않고도 새로운 관심사를 수용할 수 있었습니다.
또한 각 폴더 내부에서도 필요에 따라 도메인별 분류를 추가할 수 있었습니다. 처음에는 모든 컴포넌트가 components 폴더에 평평하게 있다가, 파일이 많아지면 ui와 도메인별 폴더로 나누는 식이죠. 이런 유연성 덕분에 팀의 규모나 프로젝트의 복잡도에 맞춰 구조를 조정할 수 있었습니다.
프론트엔드 폴더구조의 진화의 결과물
지금까지 프론트엔드 폴더 구조의 진화의 여정에 대해서 살펴 보았습니다. 단순한 역할 기반 구조에서 시작해서, 파일이 늘어나면서 관리의 어려움을 겪었고, 컴포넌트의 본질적인 차이를 발견하면서 도메인과 비도메인을 구분하게 되었으며, 마침내 페이지를 독립적인 계층으로 분리하는 데까지 이르렀죠.
이 모든 변화는 어느 천재 개발자가 하루아침에 설계한 것이 아닙니다. 수많은 개발자들이 각자의 프로젝트에서 겪은 고민과 시행착오가 모여서 만들어진 집단 지성의 결과물입니다. 누군가는 components 폴더가 너무 복잡해져서 하위 폴더를 만들기 시작했고, 누군가는 페이지와 컴포넌트를 분리하는 것이 더 직관적이라는 것을 발견했으며, 또 누군가는 도메인별로 코드를 모으는 것이 유지보수에 도움이 된다는 것을 깨달았습니다.
현재 우리가 사용하는 이 구조는 이런 수많은 발견과 개선이 쌓여서 만들어진 것입니다. 그리고 대부분의 중규모 프로젝트에서는 이 정도 구조만으로도 충분히 잘 작동합니다. 역할별 분류는 새로운 기능을 추가할 때 어디에 넣을지 명확하게 알려주고, 도메인별 세분화는 관련 코드를 찾기 쉽게 만들며, 독립된 페이지 구조는 라우팅을 직관적으로 만들어줍니다.
그리고 점점 프로젝트의 규모는 커지고 있습니다. 지금까지 진화해 온 과정보다 더 프로젝트가 더욱 성장하고 복잡해지면서, 이 구조도 새로운 문제점들을 조금씩 마주하게 됩니다. 하나의 기능을 구현하기 위해 여러 폴더를 오가야 하는 불편함, 도메인 로직이 여전히 분산되어 있는 문제, 페이지가 거대해질 때의 관리 어려움... 이런 새로운 도전들이 또 다른 진화를 요구하고 있습니다.
2부에서는 이런 한계를 극복하기 위한 방법 중 제안된 기능 중심의 폴더구조의 배경과 이유에 대해서 한번 알아보고자 합니다.
2부. 한계를 극복하기 위한 다양한 시도들과 기능 중심 아키텍쳐
1부에서 살펴본 폴더 구조의 진화는 대부분의 프로젝트가 자연스럽게 도달하는 지점입니다. 역할별 분류, 도메인별 세분화, 그리고 페이지의 독립이 결합된 구조는 중규모 프로젝트까지는 충분히 잘 작동합니다.
이후 프로젝트가 더욱 복잡해지고 팀이 성장하면, 이 구조도 새로운 한계를 드러내기 시작합니다. 그리고 프론트엔드 커뮤니티에서는 이런 한계를 극복하기 위한 다양한 제안들이 나오고 있죠.
- 모노레포 기반의 패키지 모듈 방식: 도메인별로 독립적인 패키지로 분리해서 명확한 경계를 만드는 방식
- 마이크로 프론트엔드 아키텍처: 각 도메인을 아예 독립적인 애플리케이션으로 만드는 접근
- 레이어드 아키텍처: 전통적인 백엔드 아키텍처를 프론트엔드에 적용해보려는 시도
- 기능 중심 아키텍처: 사용자가 경험하는 기능을 중심으로 코드를 조직화하는 방법
2부에서는 이런 제안 중 하나인 '기능 중심 아키텍처'를 살펴보려고 합니다. FSD(Feature Sliced Design)로 대표되는 이 접근법은 한때 러시아 프론트엔드 커뮤니티를 중심으로 활발히 논의된 바 있습니다. 아직은 논의 중이다 보니 합의가 진행된 최종진화된 형태는 아닙니다. 다만 현재의 일반적인 구조가 가진 한계점들을 무엇이라 생각했는지 그래서 그 구조를 어떻게 해결하려 했는지, 그 과정에서 우리가 어떤 통찰을 얻을 수 있는지 함께 살펴보고자 합니다.
또한 이 글의 시작은 FSD의 엄격한 규칙을 그대로 따르다가 오히려 복잡성만 늘어나는 문제를 겪는 분들을 도움이 되고자 한만큼 FSD 자체의 스펙을 가지고 이야기를 하는 것은 최소화하려고 합니다. 따라서 entities, features, widgets와 같은 명세를 이해하기에 앞서 왜 이런 구조가 나왔는지 그 배경과 문제 인식을 중점적으로 다뤄보고자 합니다. 이를 통해 무엇을 문제라고 인식했고 어떠한 방안으로 해결하고 했는지 그 문제 인식과 해법을 통해서 현재 우리 각자의 상황에 맞게 적절히 응용할 수 있는 자신만의 깨달음을 얻을 수 있기를 바랍니다.
역할 중심 구조에 대한 문제인식: 코드의 파편화
역할별 분류와 도메인별 분류가 결합되어 있는 이런 형태의 폴더구조가 아마 대부분에게 가장 익숙한 모양일 거라 생각합니다. 이제 "제품 관련 컴포넌트"와 "장바구니 관련 훅", "문자열 포맷팅 유리틸리" 등을 쉽게 구분할 수 있게 되었죠. 역할에 따른 1차 코드 분류는 매우 직관적이며 도메인과 비도메인을 분리해두니 세분화 그룹도 훨씬 체계가 잡히게 되었습니다.
그런데 임계점을 지나 훨씬 더 규모가 커지기 시작하면 역할 기반 폴더 구조의 문제점이 드러납니다. 바로 코드의 파편화입니다. 하나의 도메인과 관련된 서로 연관되어 있는 코드가 역할(components, hooks, services)에 따라 여러 폴더로 흩어져 있게 되는 거죠.
예를 들어, 장바구니(cart) 기능을 담당하는 개발을 해야 한다면 우리는 이제 다음 폴더들을 모두 오가며 작업해야 합니다.
/components/cart/ # 장바구니 UI 컴포넌트
/hooks/cart/ # 장바구니 로직 훅
/services/cart/ # 장바구니 API 호출
/store/cart/ # 장바구니 상태 관리이렇게 추려내어 보면 별것 아닌 것 같지만 실제 프로젝트에서는 훨씬 더 복잡한 폴더 구조 속에서 원하는 도메인과 관심사를 쫓아가며 코딩을 해야 합니다. 한번 아래와 같은 구조에서 cart와 연관된 내용들을 찾아보세요.
/src
/components
/ui
/atoms
Button.tsx
Input.tsx
Checkbox.tsx
Select.tsx
...20+ 파일
/molecules
FormField.tsx
SearchBar.tsx
Pagination.tsx
...15+ 파일
/layout
Header.tsx
Footer.tsx
Sidebar.tsx
/cart
CartItem.tsx
CartSummary.tsx
CartItemsList.tsx
ShippingForm.tsx
DiscountForm.tsx
/product
ProductCard.tsx
ProductGrid.tsx
ProductDetails.tsx
/checkout
CheckoutForm.tsx
PaymentMethods.tsx
/hooks
/form
useForm.tsx
useFormField.tsx
/api
useFetch.tsx
useQuery.tsx
/ui
useModal.tsx
useToast.tsx
/cart
useCart.tsx
useCartItem.tsx
useShipping.tsx
useDiscount.tsx
/product
useProducts.tsx
useProductDetails.tsx
/services
/api
client.ts
interceptors.ts
/cart
cartApi.ts
cartValidation.ts
cartTransformers.ts
/product
productApi.ts
categoryApi.ts
/checkout
checkoutApi.ts
paymentApi.ts
/store
/cart
cartSlice.ts
cartSelectors.ts
cartActions.ts
/product
productSlice.ts
productSelectors.ts
/user
userSlice.ts
authSlice.ts대개 코드를 작성할때에 초기에는 요구사항을 화면과 동작을 중심으로 사고하게 됩니다. 그러면서 데이터의 흐름과 화면을 연결하면서 마무리를 짓죠. 이후 프로젝트의 성숙도가 올라가면 주로 화면에서 문제보다는 나중에는 복잡한 데이터의 흐름 어딘가에서 문제가 주로 발생합니다. 그러나 이미 역할로 분리되어 있던 구조를 가지고 있다보니 데이터의 흐름을 따라가는 과정에서 이런 파편화가 복잡도를 유발하게 되죠.
인간은 안정된 체계와 분류를 늘 가지고 싶어 합니다. 매번 이런 파편화된 구조 속에서 관련 코드를 찾아다니는 것은 단순한 시간의 문제가 아니라 인지적 부담으로 다가옵니다. 코드를 이해하기 위해 여러 파일의 맥락을 계속 머릿속에서 재구성해야 하고, 그 과정에서 정신적 에너지가 소모되죠. 폴더구조와 생각의 구조가 일치하면 그만큼 부담이 줄어들게 됩니다.
초반에는 화면과 동작 그리고 역할을 중심으로 사고하기에 폴더구조와 사고의 구조가 비슷해지나 점점 더 데이터를 중심으로 사고를 하게 됩니다. 이렇게 도메인 로직을 다룰 때, 이 로직이 컴포넌트, 훅, 서비스, 스토어 등 여러 계층에 분산되어 있으면 계속 머리속 구조와 충돌을 겪게 됩니다. 분명 IDE의 검색 기능으로 코드를 찾을 수는 있지만, 그 코드들 간의 관계와 흐름을 이해하는 것은 별개의 문제니까요.
무엇보다 이 프로젝트를 잘 모르는 사람에게 역할구조는 대규모 프로젝트를 이해하기 어렵게 만듭니다. 역할 구조는 작성할때 분류하기에는 아주 편리한 기준을 제공하지면 이해를 하거나 디버깅을 하기에는 좋은 구조가 아닙니다. 물론 어디까지나 이러한 전제는 프로젝트가 규모가 크다는 전제입니다.
첫 번째 시도: 도메인을 최상위로 배치하다
파편화 문제를 해결하기 위해 역할별 폴더 구조를 도메인 중심 구조로 전환해 보았습니다. 앞서 언급했듯이 프로젝트의 성숙도가 올라가면서 화면보다는 데이터를 중심으로 사고하게 되기에, 도메인을 최상위에 두면 전체 프로젝트의 흐름을 이해하기가 훨씬 수월해질 것으로 기대했습니다.
/src
/Product # 제품 도메인
/components # 제품 관련 컴포넌트
/hooks # 제품 관련 훅
/services # 제품 관련 API
/utils # 제품 관련 유틸리티
/Cart # 장바구니 도메인
/components # 장바구니 관련 컴포넌트
/hooks # 장바구니 관련 훅
/services # 장바구니 관련 API
/store # 장바구니 관련 상태
/User # 사용자 도메인
/components
/hooks
/services
/store
/shared # 공통 코드
/components # 공통 UI 컴포넌트
/hooks # 공통 훅
/utils # 공통 유틸리티이 구조의 가장 큰 장점은 비즈니스 도메인이 코드베이스에 명확히 드러난다는 점입니다. 새로운 개발자가 프로젝트를 처음 접할 때 폴더 구조만으로도 "아, 이 서비스는 제품(Product)을 다루고, 장바구니(Cart) 기능을 제공하며, 사용자(User) 관리를 하는구나" 하고 바로 파악할 수 있게 됩니다.
엔티티: 도메인 안에서의 새로운 응집 기준
도메인을 중심으로 폴더를 재구성하고 나니, 이제 각 도메인 내부를 어떻게 구성할지가 다음 고민거리가 되었습니다. 기존처럼 단순히 역할별로 나누는 것보다, 도메인 안에서도 더 의미 있는 응집도를 높여줄 기준이 필요했습니다.
도메인을 중심으로 폴더를 구성하면 자연스럽게 원천 데이터를 기준으로 사고하게 됩니다. 모든 도메인 로직은 결국 특정 데이터의 형식을 중심으로 전개된다는 것을 깨달았습니다. 예를 들어, 제품 도메인은 'Product'라는 데이터를, 장바구니 도메인은 'Cart'와 'CartItem'이라는 데이터를, 사용자 도메인은 'User'라는 데이터를 중심으로 작동합니다.
이러한 핵심 데이터 모델을 엔티티(Entity)라고 부릅니다. 엔티티의 개념이 다소 막연하다면, 서버 데이터베이스에 저장되는 원천 데이터의 구조 또는 API 응답에서 공통적으로 나타나는 데이터 모델이라고 생각해도 무방합니다.
원천 데이터에서 화면까지: 데이터 흐름의 명확화
이렇게 정의된 엔티티, 예를 들어 '제품(Product)' 엔티티는 다음과 같은 여러 곳에서 활용됩니다. 우리는 이러한 엔티티를 기준으로 응집력 있는 구조를 만들 수 있습니다.
- 제품 목록 조회
- 제품 검색
- 제품 상세 보기
- 장바구니에 제품 추가
- 주문 시 제품 정보 표시
프론트엔드는 데이터를 기반으로 화면을 구성하는 과정이므로, 엔티티를 중심으로 사고하면 원천 데이터로부터 화면에 이르기까지의 데이터 흐름이 더욱 선명해집니다. 대부분의 원천 데이터는 서버의 데이터베이스에서 시작되어 API를 통해 브라우저로 전달되고, 여러 단계의 가공을 거쳐 최종적으로 화면에 표시됩니다. 이 흐름을 엔티티 중심으로 정리하면 다음과 같습니다.
1. API 계층: 엔티티 데이터 획득
// 서버로부터 Product 엔티티와 유사한 구조의 데이터를 받아옴
async function fetchProduct(id: string): Promise<ProductDTO> { // DTO로 명시
return api.get(`/products/${id}`);
}
// 여러 엔티티 관련 데이터를 조합해서 받기도 함
async function fetchCartWithProducts(): Promise<{
cart: CartDTO; // DTO로 명시
products: ProductDTO[]; // DTO로 명시
}> {
return api.get('/cart/with-products');
}2. 변환 계층: 화면용 데이터로 가공
// 서버에서 받는 DTO (Data Transfer Object)
interface ProductDTO {
id: string;
name: string;
price: number;
discount_rate: number;
stock_count: number;
created_at: string;
}
// 프론트엔드 엔티티 (도메인 모델)
interface Product {
id: string;
name: string;
price: number;
discountRate: number;
stock: number;
createdAt: Date;
}
// DTO → Entity 변환 함수
function toProduct(dto: ProductDTO): Product {
return {
id: dto.id,
name: dto.name,
price: dto.price,
discountRate: dto.discount_rate,
stock: dto.stock_count,
createdAt: new Date(dto.created_at)
};
}
async function fetchAndTransformProducts(): Promise<Product[]> {
const response = await api.get<ProductDTO[]>('/products');
return response.map(toProduct);
}3. 계산 계층: 엔티티 기반 비즈니스 로직
// 엔티티를 활용한 계산 로직
function calculateTotalPrice(products: Product[], quantities: number[]): number {
return products.reduce((sum, product, index) => {
const discountedPrice = product.price * (1 - product.discountRate);
return sum + (discountedPrice * quantities[index]);
}, 0);
}
// 엔티티 간의 관계를 활용한 로직 (CartItemWithProduct는 Product와 CartItem 정보를 결합한 ViewModel일 수 있음)
interface CartItemWithProduct { // 예시 ViewModel
productId: string;
quantity: number;
product: Product; // Product 엔티티 포함
}
function getProductsInCart(cartItems: CartItem[], products: Product[]): CartItemWithProduct[] { // Cart는 CartItem의 컬렉션으로 가정
return cartItems.map(item => ({
...item,
product: products.find(p => p.id === item.productId)!
}));
}4. UI 계층: 엔티티 데이터 표현
// 엔티티 또는 ViewModel 기반 UI 컴포넌트
// ProductViewModel은 Product 엔티티에서 파생되어 화면 표시에 필요한 추가 정보/가공된 정보를 가짐
interface Product {
id: string;
name: string;
price: number; // 원가
discountedPrice: number; // 할인가
displayPrice: string; // 표시용 가격 문자열 (원가)
discountPercentage?: string; // 할인율 문자열
stockStatus: 'IN_STOCK' | 'LOW_STOCK' | 'OUT_OF_STOCK';
}
function ProductCard({ product }: { product: Product }) {
return (
<div className="product-card">
<h3>{product.name}</h3>
<div className="price">
{product.discountPercentage && ( // 할인율이 있을 경우
<>
<span className="original">{product.displayPrice}</span>
<span className="discount">{product.discountPercentage}</span>
</>
)}
<span className="final">
{product.discountedPrice.toLocaleString()}원
</span>
</div>
{/* <StockBadge status={product.stockStatus} /> */}
</div>
);
}엔티티 중심 구조의 이점
이렇게 엔티티를 중심으로 각 도메인 내부의 코드를 구성하니, 앞서 도메인별로 폴더를 나누었을 때 얻었던 이점들이 더욱 강화되고 구체화되는 것을 경험할 수 있었습니다. 도메인 중심 구조가 프로젝트의 전체적인 맥락 파악을 도울 수 있었고 엔티티와 데이터 흐름을 중심으로 하는 세부 구조는 각 도메인 내 데이터 흐름의 명확성과 관련 로직들의 응집성을 높이며 다음과 같은 세부적인 이점이 있었습니다.
첫째, 데이터를 이해하는 데 드는 인지 비용이 크게 줄었습니다. 어떤 화면이든, 어떤 기능이든 결국 다루는 중심 데이터가 무엇인지를 명확히 알고 출발할 수 있었고, 그 데이터가 어떻게 가공되고 어떤 방식으로 표현되는지를 일관된 구조 안에서 따라가게 되니, 더 이상 ‘이건 어디서 오는 데이터지?’를 고민하지 않게 되었습니다.
둘째, 도메인 로직이 흩어지지 않고 데이터의 흐름을 중심으로 한곳에 모이게 되었습니다. 원천 데이터에서 시작해 계산, 변환, 표현까지의 흐름이 한눈에 들어오니, 새로운 요구사항이 들어와도 어느 지점에서 변경이 일어나야 하는지 바로 감이 옵니다. 마치 하나의 데이터 파이프라인을 다루듯, 코드를 따라가는 과정과 데이터의 생애주기를 따라가게 된 셈이었습니다.
/Product
/entity # 제품 엔티티 중심 폴더
/interfaces # 엔티티 및 ViewModel 인터페이스
Product.ts # Product 엔티티 인터페이스
ProductViewModel.ts # Product 화면용 ViewModel 인터페이스
/api # 엔티티 데이터 획득 관련 API
productApi.ts
/model # 엔티티 데이터 가공 및 비즈니스 로직
mappers.ts # DTO → Entity, Entity → ViewModel 변환 함수
calculations.ts # 엔티티 기반 계산 로직
/ui # 엔티티/ViewModel 기반 UI 컴포넌트
ProductCard.tsx # 제품 정보 표시 컴포넌트
ProductPrice.tsx # 가격 표시 컴포넌트모든 도메인에 엔티티 중심 구조로 바꿔야 할까?
그렇지만 모든 도메인에 엔티티 중심 구조를 적용할 필요는 없습니다. 페이지 내용이 거의 변하지 않거나 단순히 UI 컴포넌트를 조합하는 수준의 도메인이라면, 복잡한 다층적 엔티티 구조는 오히려 인지 부담을 늘리고 실제 얻는 이점은 미미할 수 있습니다.
만약 데이터 흐름이 복잡하고, 여러 화면이나 기능에서 핵심 데이터가 재사용되는 도메인에서는 이야기가 달라집니다. 예를 들어, 커머스 프로젝트의 Product, User, Order, Cart처럼 서비스의 핵심을 이루면서 데이터의 생애 주기(API 획득, 가공, 표현) 전반에 걸쳐 복잡한 흐름을 보이는 도메인이라면, 엔티티 중심 구조가 강력한 효과를 발휘할 수 있습니다. 이 구조는 관련 로직들을 한곳에 모아 파편화를 막고, 변경이나 확장이 필요할 때 어디를 손봐야 할지 명확하게 보여줍니다.
이처럼 폴더 구조를 역할 중심에서 엔티티 중심의 데이터 흐름으로 세분화하는 방식은, 프로젝트 규모가 커짐에 따라 데이터의 구조와 존재 여부, 그리고 그 흐름을 파악하는 것이 중요해지는 상황에서 제안되었습니다. 이러한 배경과 필요성을 명확히 이해한다면, 단순히 구조를 따르는 것을 넘어 여러분의 프로젝트에 맞게 이 방식을 적절히 응용하고 발전시키는 데 큰 도움이 될 것입니다.
두 번째 시도: 화면을 위젯으로 세분화하기
역할 중심의 구조에서 도메인 중심으로 코드의 응집도를 높여 나가다 보니, 엔티티를 중심으로 데이터 흐름을 고려하는 새로운 관점의 세분화 방식이 생겨났습니다. 이와 마찬가지로, 프론트엔드의 또 다른 주요 관점인 '화면'에 대해서도 모듈화 수준을 높이고자 하는 고민으로 이어졌습니다.
프로젝트 규모가 커지면 하나의 단일 페이지 컴포넌트가 감당해야 할 기능과 상태가 점점 늘어나는 상황은 흔히 발생합니다. 이러한 거대 페이지 컴포넌트는 코드의 복잡성을 증가시켜 전체 흐름을 파악하기 어렵게 만들고, 페이지의 특정 부분을 다른 컨텍스트에서 재사용하기 어렵게 만드는 등의 문제를 야기하게 됩니다.
// 점점 복잡해지는 페이지 컴포넌트의 전형적인 모습
function ProductDetailPage() {
// 관리해야 할 수많은 state와 effect
const [product, setProduct] = useState(null);
// ... (이하 유사 상태들 생략)
// 여러 종류의 데이터를 불러오고 처리하는 복잡한 로직
useEffect(() => {
// 제품 정보, 리뷰, 연관 상품 로딩 및 사용자 상태 확인 등
// 다양한 비동기 로직과 상태 업데이트가 얽힘
}, []);
// 때로는 수백 줄에 달하는 방대한 JSX 구조
return (
<div>
{/* 제품 이미지 갤러리 영역 */}
<div className="product-gallery">{/* 해당 구역 로직 생략 */}</div>
{/* 제품 정보 표시 영역 */}
<div className="product-info">{/* 해당 구역 로직 생략 */}</div>
{/* 사용자 리뷰 표시 영역 */}
<div className="reviews">{/* 해당 구역 로직 생략 */}</div>
{/* 연관 상품 추천 영역 */}
<div className="related-products">{/* 해당 구역 로직 생략 */}</div>
</div>
);
}위젯: 페이지 내부 구조의 독립적 세분화
이러한 문제를 해결하기 위해 거대한 페이지 컴포넌트를 내부적으로 의미 있는 '구획' 또는 '모듈' 단위로 나누려는 시도가 자연스럽게 나타납니다. 이렇게 의미있는 화면 단위를 독립적인 컴포넌트로 만들게 되면 서로 겹치지 않는 props나 상태들이 분리되면서 각 컴포넌트들이 간소화될 수 있습니다.
하나의 페이지를 살펴보면, 페이지가 단순히 하나의 큰 덩어리가 아니라, 기능적으로 구분되거나 화면을 기준으로 독립적인 여러 구획으로 나뉘어 있음을 발견할 수 있습니다. 제품 상세 페이지를 예로 들면, 일반적으로 다음과 같은 화면의 구획들이 존재합니다.
- 상단의 제품 이미지 갤러리
- 제품 정보와 구매 옵션
- 제품의 상세 설명
- 사용자 리뷰
- 연관 상품 추천
이들 각 구획은 페이지 전체의 맥락 속에서 서로 연관되기도 하지만, 각자 독립적인 관심사와 책임을 지닌 단위로 볼 수 있습니다. 이러한 구획들을 '위젯'이라는 개념의 별도 컴포넌트로 분리하여 관리하는 방식이 효과적으로 활용될 수 있으며, 페이지는 위젯의 조립이라는 식으로 분리하여 관리하는 방법을 취할 수 있습니다.
// 페이지 내 기능 구획으로 분리된 구조의 예시
function ProductDetailPage() {
const { id: productId } = useParams();
return (
<Layout>
<ProductImageGallery productId={productId} />
<ProductInfoBoard productId={productId} />
<ProductDescriptionSection productId={productId} />
<ReviewListSection productId={productId} />
<RelatedProductsCard productId={productId} />
</Layout>
);
}
// 각 구획은 독립적인 책임과 데이터를 관리
// 예시: ReviewListSection (리뷰 목록 구역)
function ReviewListSection({ productId }) {
const { data: reviews, loading, error } = useReviews(productId);
const [showWriteReviewModal, setShowWriteReviewModal] = useState(false);
if (loading) return <LoadingSpinner message="리뷰 로딩 중..." />;
if (error) return <ErrorMessage message="리뷰 로딩 실패" />;
if (!reviews?.length && !loading) return <EmptyStateView />;
return (
<section aria-labelledby="reviews-section-title">
<header>
<h2 id="reviews-section-title">고객 리뷰 ({reviews.length})</h2>
<Button onClick={() => setShowWriteReviewModal(true)}>리뷰 작성</Button>
</header>
<ReviewsDisplayList reviews={reviews} />
{showWriteReviewModal && (
<WriteReviewModal
productId={productId}
onClose={() => setShowWriteReviewModal(false)}
onSubmitSuccess={() => { /* 리뷰 목록 갱신 등 */ }}
/>
)}
</section>
);
}이처럼 페이지를 기능 구획 기반으로 구성하는 접근법은 다음과 같은 장점들이 있습니다.
첫째, 페이지 컴포넌트의 역할이 간결하고 명확해집니다. 페이지는 주로 각 구획 컴포넌트들을 조합하고 전체 레이아웃을 구성하며, 필요시 구획 간 상호작용을 조율하거나 라우팅 관련 로직만을 처리합니다. 복잡한 로직은 각 구획이 독립적으로 담당합니다.
둘째, 각 구획 컴포넌트를 독립적으로 개발, 테스트 및 유지보수할 수 있게 됩니다. 특정 구획의 문제는 해당 범위 내에서 해결 가능하며, 이는 다른 부분에 미치는 영향을 최소화합니다.
셋째, 구획 컴포넌트의 재사용성이 향상됩니다. 예를 들어, RelatedProductsCard는 제품 상세 페이지 외에 장바구니, 검색 결과 페이지 등 다양한 컨텍스트에서 효과적으로 재사용될 수 있습니다.
// 기능 구획 컴포넌트 재사용성의 예시
function CartPage() {
const representativeProductId = useCartRepresentativeProductId();
return (
<Layout>
<CartItemsList />
<CartSummaryBoard />
{representativeProductId && <RelatedProductsCard productId={representativeProductId} />}
</Layout>
);
}화면의 계층 구조와 폴더구조의 의의
이러한 계층 구조가 단순히 코드 분할을 넘어 팀의 생산성에 기여하는 핵심은 바로 개발자의 멘탈 모델을 폴더 구조에 명확히 드러냄으로써 얻는 시너지 효과에 있습니다. '위젯'과 같은 화면 구획 컴포넌트 구조가 정착되면서 나타나는 페이지(Page) → 화면 구획 컴포넌트 (예: List, Card, Board 등) → UI 컴포넌트 계층은 각기 다음과 같은 특징적인 책임과 역할을 담당합니다.
페이지 (Page)
- 애플리케이션의 주요 라우팅 진입점(entry point) 역할을 합니다.
- 전체적인 페이지 레이아웃과 해당 페이지 고유의 템플릿을 구성합니다.
- 여러 화면 구획 컴포넌트를 조립하고 배치하여 페이지의 전체적인 내용을 구성합니다.
- 필요에 따라 페이지 수준의 데이터를 가져오거나, 구획 간 상태 흐름을 조율합니다.
- 라우팅 파라미터 및 공통 컨텍스트를 처리하고 하위 구획으로 전달합니다.
화면 구획 컴포넌트 (예: ProductInfoBoard, ReviewListSection 등)
- 페이지 내 특정 기능 구획이나 독립적인 관심사를 담당합니다.
- 자체적으로 필요한 데이터 로딩 및 상태 관리를 통해 독립성을 유지합니다.
- 다른 페이지나 컨텍스트에서 재사용될 수 있도록 설계하는 것이 바람직합니다.
- 관련된 하위 UI 컴포넌트들을 조합하여 하나의 응집력 있는 기능 단위를 제공합니다.
UI 컴포넌트 (Component)
- 주로 UI의 시각적 표현에 집중하는 가장 작은 단위입니다 (예: 버튼, 입력 필드).
- 대부분
props를 통해 데이터를 전달받아 렌더링하는 순수 함수(Stateless) 형태를 지향합니다.- 애플리케이션 전반에 걸쳐 높은 재사용성을 가지며, 디자인 시스템의 기본 요소가 되기도 합니다.
- 독자적인 비즈니스 로직이나 데이터 호출 로직을 거의 포함하지 않습니다.
실제 화면의 감각에 맞춘 구조화
페이지를 화면 단위의 더 작은 구획으로 나누어 개발하는 접근 방식 자체가 새로운 발상은 아닙니다. 대부분의 개발자들도 규모가 커진 페이지 컴포넌트들을 암묵적으로 세부 컴포넌트들로 만들어서 적절히 '뷰(View)', '섹션(Section)', '컨테이너(Container)', '에어리어(Area)', '블록(Block)', '모듈(Module)' 등 저마다의 다양한 용어로 불리며 개념적으로 분리된 컴포넌트로 다루었을 것입니다.
화면 중심의 폴더 구조 세분화는 이러한 암묵적인 방법들을 화면을 중심으로 하는 별도의 폴더 구조 및 역할을 부여함으로써, 이를 명시적인 컨벤션으로 발전시키는 과정이라 할 수 있습니다. 이러한 접근을 통해 '페이지 - 화면 구획 컴포넌트 - UI 컴포넌트'라는 자연스럽고 명확한 계층 구조가 형성됩니다.
위젯이라는 단위를 도입하는 이유는 단지 코드 재사용성을 높이거나 페이지 컴포넌트를 나누기 위해서가 아니라, 우리가 화면을 바라볼 때 자연스럽게 감지하게 되는 시각적, 기능적 구획을 코드 구조에 반영하기 위해서입니다. 실제로 제품 상세 페이지를 처음 봤을 때, 우리는 제품 이미지와 리뷰, 설명, 추천 상품을 하나의 일관된 흐름으로 받아들이되, 그 각각을 명확히 분리된 영역으로 인식하게 됩니다. 그리고 이 인식이 자연스러울수록 코드도 그러한 "시각적 구획"에 가까운 단위로 나누는 것이 개발자 사이의 이해와 협업을 훨씬 쉽게 만들어줍니다.
이런 분리는 단지 코드상의 계층화만이 아니라, 화면이 제공하는 의미적 구조를 그대로 코드로 옮기는 작업입니다. 다시 말해, 실제 결과로 보이는 페이지와 코드로 보이는 폴더구조간의 괴리를 줄이기 위함이며, 이는 곧 멘탈모델과 코드 구조 사이의 정렬을 의미합니다.
세 번째 시도: '행동'을 기반의 기능 응집 구조
프론트엔드 개발의 핵심 사이클은 데이터 → 화면 → (사용자) -> 행동 -> 데이터 -> 화면 ... 으로 이어지는 흐름입니다. 지금까지 우리는 엔티티를 통해 '데이터' 중심의 응집도를, 위젯을 통해 '화면' 중심의 응집도를 높이는 방법을 살펴보았습니다. 그리고 나머지 사용자의 '행동'을 중심으로 하는 기능 사이클을 중심으로 한 응집도를 높이는 방법을 한번 살펴봅시다.
이러한 '행동' 중심의 기능은 단순히 데이터나 화면 단위로 쪼개기 어려운 복합적인 흐름을 가집니다. 엔티티나 위젯으로 응집도를 높이려는 시도만으로는 이 '행동' 전체를 아우르는 응집성을 확보하기 어렵다는 한계에 직면하게 된 것입니다.
예를 들어, '제품 검색'이라는 기능을 개발한다고 가정해 봅시다.
- 사용자가 검색창에 키워드를 입력하고 검색 버튼을 누르는 '행동'.
- 이 행동이 서버에 검색 요청을 보내고 데이터를 받아오는 과정.
- 받아온 데이터를 가공하여 화면에 검색 결과를 표시하는 과정.
기존 역할 중심 구조에서는 이러한 '행동'에 따른 데이터 흐름이 여전히 여러 폴더에 흩어져 있었습니다.
- 검색 입력 폼은
/components/search/에- 검색 로직을 담은 훅은
/hooks/search/에- API 호출은
/services/product/에- 데이터 가공 로직은
/utils/product/에- 결과 표시 컴포넌트는
/components/product/에
개발자가 "제품 검색 기능을 수정해달라"는 요청을 받으면, 여전히 데이터의 흐름을 따라가며 여러 폴더를 오가야 했습니다. '데이터'와 '화면'을 위한 응집 노력이 있었음에도 불구하고, 하나의 '사용자 행동'에 대한 완전한 맥락은 여전히 파편화되어 머릿속에서 재구성해야 하는 인지적 부담으로 남아있었던 것이죠.
'기능' 중심의 흐름을 한 곳에 모아보자.
우리는 이 문제를 해결하기 위해 사용자의 하나의 '행동'에서 시작되어 완료까지 이어지는 모든 데이터 흐름을 한곳에서 볼 수 있게 만드는 새로운 응집 기준을 모색했습니다. 이것이 바로 기능 중심 응집의 핵심입니다.
제품 검색 기능이라면, 검색 입력부터 결과 표시까지의 모든 과정을 하나의 '기능 단위(Feature Unit)'로 보고, 관련 코드를 한 폴더 안에서 추적할 수 있도록 만드는 것입니다.
/features/product-search/
├── 입력 처리 (UI 컴포넌트)
├── 행동 정의 (이벤트 → 액션 변환)
├── 서비스 호출 (API 요청)
├── 데이터 가공 (응답 처리)
└── 결과 표시 (결과 UI)이렇게 구성하면 데이터가 어디서 와서 어떻게 변환되고 최종적으로 어떻게 표시되는지 그 전체 여정을 한눈에 파악할 수 있습니다. 새로운 개발자가 프로젝트에 합류해도 특정 기능의 동작 방식을 이해하기 위해 여러 폴더를 헤맬 필요가 없어집니다.
이는 단순히 파일 찾기 편의성을 넘어, 개발자의 멘탈 모델이 '기능의 완전한 흐름'과 일치하게 되면서, 코드를 이해하고 수정하는 과정에서 발생하는 인지적 부담을 크게 줄여줍니다. 특히 복잡한 비즈니스 로직을 다룰 때 이런 차이는 더욱 두드러집니다.
기능 중심 구조에서 개발자의 사고 과정은 다음과 같이 변화합니다.
- 기존 방식: "검색 버튼 로직을 고쳐야 해 →
hooks폴더에서useSearch찾기 → API 호출 부분 확인하려면services폴더 → 결과 처리는utils폴더 → 화면 업데이트는components폴더"- 기능 중심 방식: "제품 검색 기능을 고쳐야 해 →
product-search폴더 → 전체 흐름 파악 → 필요한 부분 수정"
이는 단순히 편의성의 문제가 아닙니다. 개발자의 멘탈 모델이 "기능의 완전한 흐름"과 일치하게 되면서, 코드를 이해하고 수정하는 과정에서 발생하는 인지적 부담이 크게 줄어듭니다. 특히 복잡한 비즈니스 로직을 다룰 때 이런 차이는 더욱 두드러집니다. 또한 기능 단위로 코드가 응집되어 있으면, 해당 기능의 테스트, 문서화, 리팩토링도 훨씬 체계적으로 접근할 수 있습니다. 기능의 경계가 명확하니 다른 기능에 미치는 영향을 최소화하면서 안전하게 개선 작업을 진행할 수 있죠.
행동 중심의 흐름 이해하기
사용자가 경험하는 하나의 완전한 기능은 다음과 같은 연속적인 데이터 흐름으로 구성됩니다.
-
입력 화면 → 이벤트 발생
사용자가 검색창에 키워드를 입력하고 검색 버튼을 클릭합니다. 이 순간 단순한 UI 이벤트가 발생하죠.// 사용자 입력 수집 <input onChange={e => setSearchTerm(e.target.value)} /> <button onClick={handleSearch}>검색</button> -
이벤트 → 행동 결정
클릭 이벤트는 "제품을 검색한다"는 구체적인 행동으로 해석됩니다. 여기서 중요한 것은 이벤트와 행동은 다르다는 점입니다. 같은 클릭 이벤트라도 맥락에 따라 "검색", "필터링", "정렬" 등 다른 행동이 될 수 있습니다.// 이벤트를 구체적 행동으로 해석 const handleSearch = () => { if (searchTerm.trim()) { performProductSearch(searchTerm); // "제품 검색" 행동 } }; -
행동 → 서비스 호출
"제품 검색"이라는 행동은 필요한 데이터를 얻기 위해 적절한 API를 호출하게 됩니다. 이때 사용자 입력을 서버가 이해할 수 있는 요청 파라미터로 변환하는 과정이 필요합니다.// 사용자 입력을 API 파라미터로 변환 const performProductSearch = (term) => { const apiParams = { q: term, category: selectedCategory, page: 1 }; searchProductsAPI(apiParams); }; -
서비스 → 데이터 처리
서버로부터 받은 원천 데이터는 바로 화면에 표시할 수 있는 형태가 아닙니다. 정렬, 필터링, 포맷팅 등의 가공 과정을 거쳐야 합니다.// 원천 데이터를 화면용으로 가공 const processSearchResults = (rawData) => { return rawData.items.map(item => ({ id: item.id, name: item.title, price: formatPrice(item.price), isAvailable: item.stock > 0 })); }; -
데이터 → 화면 표시
가공된 데이터가 최종적으로 사용자가 볼 수 있는 화면으로 렌더링됩니다. 검색 결과 목록, 로딩 상태, 에러 메시지 등이 모두 포함됩니다.// 가공된 데이터를 UI로 렌더링 {isLoading ? <Spinner /> : <ProductList products={processedResults} /> } -
화면 → 다음 행동 준비
표시된 결과를 바탕으로 사용자는 다시 새로운 행동(상세보기, 필터 추가, 페이지 이동 등)을 준비하게 됩니다.// 다음 행동을 위한 인터랙션 준비 <ProductItem product={item} onDetailView={() => navigateToDetail(item.id)} onAddToCart={() => addToCart(item.id)} />
'엔티티'와 '위젯' 그리고 '기능'간의 경계는 어떻게 정해야 할까?
이러한 멘탈 모델에서 가장 헷갈리는 점은 아마 같은 기능이 화면과 데이터를 모두 공유하고 있기에 데이터 중심의 엔티티와 화면 중심의 위젯과 기능간의 경계일 것입니다. 분명히 기능은 화면과 데이터를 모두 포함하고 있는 계층이죠. 이 질문에 대한 답은 각 계층의 '관심사'가 다르다는 점에서 찾을 수 있습니다.
엔티티: "무엇을" 표시할지에 집중
// entities/product - 제품 데이터 자체의 기본 표현
interface Product {
id: string;
name: string;
price: number;
image: string;
}
function ProductCard({ product }) {
return (
<div>
<img src={product.image} />
<h3>{product.name}</h3>
<span>{product.price}원</span>
</div>
);
}엔티티는 데이터 그 자체의 표현에 집중합니다. 제품 데이터의 순수한 형태와 기본적인 표현 방식을 정의합니다.
위젯: "어디에/어떤 구조로" 배치할지에 집중
// widgets/product-showcase - 제품들을 하나의 화면 구획으로 조직화
function ProductShowcase({ title, productIds, layout = 'grid' }) {
const { data: products } = useProducts(productIds);
return (
<section className="product-showcase">
<header className="showcase-header">
<h2>{title}</h2>
<ViewToggle value={layout} onChange={setLayout} />
</header>
<div className={`showcase-content ${layout}`}>
{products?.map(product => (
<ProductCard key={product.id} product={product} />
))}
</div>
{products?.length === 0 && (
<EmptyState message="표시할 제품이 없습니다" />
)}
</section>
);
}위젯은 여러 컴포넌트를 조합하여 하나의 의미있는 화면 구획을 만드는 것에 집중합니다. 제품 카드들을 어떻게 배열하고, 어떤 레이아웃으로 보여줄지, 빈 상태는 어떻게 처리할지 등 화면 구성의 관심사를 다룹니다.
기능: "어떻게/왜" 표시할지에 집중
// features/product-search - 검색 결과라는 맥락에서의 표현
function SearchResultItem({ product, searchTerm }) {
return (
<div>
<img src={product.image} />
<h3>
<HighlightText text={product.name} highlight={searchTerm} />
</h3>
<span>{product.price}원</span>
<div className="search-metadata">
검색 일치도: {product.relevanceScore}
</div>
</div>
);
}기능은 특정 사용자 행동의 맥락에서 데이터를 어떻게 표현하고 처리할지에 집중합니다. 검색 결과에서는 검색어 하이라이트, 관련도 점수 등 해당 기능에만 필요한 정보가 추가됩니다.
핵심 차이점을 정리하면:
- 엔티티: 데이터 그 자체의 표현 (Product를 어떻게 표시할 것인가)
- 위젯: 화면 구획의 구성과 배치 (여러 Product들을 하나의 섹션으로 어떻게 조직할 것인가)
- 기능: 특정 맥락에서의 행동과 흐름 (검색이라는 행동에서 Product를 어떻게 다룰 것인가)
그래서 다음과 같이 구분을 해볼 수 있습니다.
- 엔티티: 데이터 중심의 순수한 표현이므로 특별한 상호작용 로직이 없음
- 위젯: 화면 구획 내에서의 사용자 상호작용 (레이아웃 변경, 더보기 등)
- 기능: 특정 목적을 위한 복합적인 사용자 행동 (검색, 필터링, 주문 등)
결론적으로, 세 계층은 서로 데이터를 주고 받는 접점은 존재하나 서로 다른 추상화 수준에서 서로 다른 관심사를 다루게 됩니다.
소프트웨어 공학 원칙과 제안을 현실적으로 나에게 맞게 적용하기
지금까지 엔티티, 위젯, 그리고 기능이라는 세 가지 응집 기준으로의 폴더 구조의 변화에 대한 제안적 배경을 함께 살펴보았습니다.
사실 이런 내용들은 FSD 공식 문서에 직접 나와있는 설명은 아닙니다. 제가 FSD 문서를 읽고 실제 적용을 시도해보면서 느낀 개인적인 해석과 이해를 바탕으로 정리한 내용입니다. 그리고 이 과정에서 깨달은 점들을 공유하고 싶어서 이 글을 쓰게 되었습니다.
FSD 적용 시도와 깨달음
처음에 FSD를 접했을 때는 "기능을 중심으로 응집도를 높인다"는 아이디어 자체가 흥미로웠습니다. 그래서 실제 프로젝트에 적용해보려고 했는데, 막상 해보니 예상과는 달랐어요.
entities와 features의 경계가 생각보다 애매했고, 팀원들과 이 구조에 대해 논의하는 것도 쉽지 않았습니다. "이 컴포넌트는 entities에 둬야 할까, features에 둬야 할까?" 같은 분류 문제에 시간을 많이 쓰게 되더라구요. 오히려 복잡성만 늘어나는 느낌이었어요.
특히 저희가 진행했던 대형 홈페이지 서비스 프로젝트에서는 FSD 구조가 잘 맞지 않았습니다. 페이지들이 각자 독립적인 특성을 가지고 있었고, 공통으로 사용하는 엔티티도 생각보다 많지 않았거든요. 오히려 FSD를 적용하려다 보니 원래보다 더 파편화가 일어나는 상황이 벌어졌어요.
하지만 흥미로운 점은, FSD가 지적하는 문제들 자체는 정말 공감이 되었다는 것입니다. 프로젝트 규모가 커지면서 겪게 되는 코드 파편화, 관련 코드를 찾기 위해 여러 폴더를 오가야 하는 불편함, 페이지 컴포넌트가 점점 거대해지는 문제... 이런 것들은 분명 계층적 구조가 필요한 지점들이었거든요.
그래서 "FSD 구조 자체보다는, 이런 접근 방식을 어떻게 해석하고 이해할 수 있을지 한번 시도해보자"는 생각이 들었습니다.
소프트웨어 공학 원칙으로 해석한 기능 중심 아키텍처
FSD는 구체적인 구조와 규칙들을 제안하고 있지만, 왜 이런 방식이 효과적인지에 대한 이론적 배경은 많이 설명되어 있지 않더라구요. 그래서 제가 알고 있는 소프트웨어 공학 원칙들을 바탕으로 이를 해석해보려고 시도했습니다.
관심사의 분리(Separation of Concerns)는 소프트웨어의 각 부분이 서로 다른 관심사를 다루도록 설계하는 원칙입니다. 쉽게 말해, 데이터 처리하는 코드와 화면 그리는 코드, 사용자 행동 처리하는 코드를 뒤섞지 말고 명확히 구분하자는 거죠. FSD에서 entities는 데이터 관심사를, widgets는 화면 구성 관심사를, features는 사용자 행동 흐름 관심사를 각각 담당하도록 설계된 것으로 해석할 수 있습니다. 이렇게 분리하면 장바구니 기능을 수정할 때 여러 폴더를 오가며 머릿속에서 조각들을 맞추는 부담을 줄일 수 있어요.
단일 책임 원칙(Single Responsibility Principle)은 하나의 모듈이나 클래스가 변경되는 이유가 단 하나여야 한다는 원칙입니다. 즉, 각 코드가 명확한 하나의 책임만 가져야 한다는 거죠. FSD의 계층 구조를 보면, entities는 순수한 데이터 구조와 기본 연산만, widgets는 화면 영역의 구성과 배치만, features는 사용자 행동의 완전한 흐름만을 책임지도록 설계되어 있습니다. 이렇게 하면 제품 데이터 구조가 바뀌어도 화면 레이아웃까지 영향받는 상황을 방지할 수 있어요.
의존성 역전 원칙(Dependency Inversion Principle)은 상위 모듈이 하위 모듈에 의존해야 하고, 그 반대는 안 된다는 원칙입니다. 안정적인 것에 의존하고 불안정한 것에는 의존하지 말라는 뜻이기도 하죠. FSD의 Pages → Widgets → Features → Entities → Shared 방향이 바로 이 원칙을 구현한 것으로 보입니다. 하위 계층일수록 더 안정적이고 범용적이며, 상위 계층일수록 더 구체적이고 변경 가능성이 높죠. 이 방향을 지키면 entities를 수정해도 pages까지 영향이 가지 않고, 변경의 파급효과를 제한할 수 있습니다.
이런 식으로 분석해보니, 기능 중심 아키텍처라는 접근법이 사실 소프트웨어 공학의 검증된 원칙들을 프론트엔드 상황에 맞게 응용한 것이라는 게 제 해석입니다. FSD는 그런 원칙들의 구체적인 구현 방법 중 하나를 제안한 거였던 거죠.
방법론보다 배경을 이해하는 것의 힘
이런 해석 과정을 거치면서 깨달은 것은, 결국 소프트웨어 공학의 기초 원칙들을 이해하는 것이 가장 중요하다는 점이었습니다. 처음에는 "FSD 사용법"을 익히려고 했었거든요. entities에는 뭘 넣고, features에는 뭘 넣고... 이런 분류 방법에 매몰되어 있었어요.
그런데 소프트웨어 공학 원칙으로 해석해보니, 분류 자체는 그리 중요하지 않다는 걸 알게 되었습니다. 중요한 건 "이 코드가 어떤 관심사를 다루는가? 어떤 책임을 져야 하는가? 다른 코드와 어떤 의존성을 가져야 하는가?"였던 거죠. 이런 근본적인 질문들에 답할 수 있게 되니, 어떤 방법론을 마주해도 그 본질을 파악할 수 있게 되었습니다.
그리고 이런 관점을 가지게 되니, 프로젝트마다 다른 특성에 맞게 이 원칙들을 유연하게 응용할 수 있게 되었어요. 어플리케이션 성격의 프로젝트에서는 FSD와 비슷한 구조가 잘 맞지만, 홈페이지 성격의 프로젝트에서는 페이지 중심의 구조가 더 적합하다는 것도 판단할 수 있게 되었고요.
무엇보다 원칙을 이해하고 나니 각자의 상황에 맞는 구조를 스스로 설계할 수 있는 자신감이 생겼습니다. FSD든 다른 방법론이든, 그 방법론이 어떤 원칙을 바탕으로 하고 있는지 이해하면 내 프로젝트에 맞게 변용할 수 있다는 걸 깨달았거든요.
결국 도구더라
사실 저도 FSD를 적용하면서 많은 시행착오를 겪었고, 그대로 쓰기는 어려웠습니다. 하지만 이걸 이해하고 분석하고 응용하는 과정에서 전보다 훨씬 더 좋은 구조를 만들 수 있었어요. 문제는 이런 경험을 어떻게 공유할지였습니다.
FSD가 아닌 방식으로 소개하자니 애매했고, 그렇다고 FSD 사용법을 그대로 소개하는 글을 쓰자니 똑같은 시행착오에 빠뜨리는 것 같더라구요. 그래서 이런 글을 쓰게 되었습니다. 특정 방법론의 사용법보다는, 그 방법론을 어떻게 해석하고 이해할 수 있는지, 그리고 그런 접근이 왜 유용한지를 전달하고 싶었어요.
많은 분들이 FSD를 시도해보다가 "entities와 features 구분이 어렵다", "팀에 설득하기 힘들다", "오히려 복잡해진다" 같은 어려움을 겪는 것 같은데, 저 역시 같은 길을 걸었거든요. 그런데 표면적인 규칙에서 벗어나 그 뒤에 있는 원칙을 이해하니까 훨씬 유연하게 접근할 수 있게 되더라구요.
결국 FSD든 다른 방법론이든, 소프트웨어 공학 원칙들을 실현하기 위한 도구일 뿐입니다. 그 도구를 맹목적으로 따르기보다는, 도구가 추구하는 원칙을 이해하고 각자의 프로젝트와 팀 상황에 맞게 변용할 수 있다면 더 의미가 있을 거라고 생각해요. 구조는 결국 우리가 더 나은 코드를 작성하고 유지보수할 수 있도록 돕는 도구이니까요.
개인적인 기능 분할 아키텍처 활용기
앞서 말했듯이 FSD를 그대로 적용하기는 어려웠지만, 소프트웨어 공학 원칙으로 해석한 기능 분할 아키텍처의 접근법은 정말 유용했습니다. 다만 프로젝트 성격에 따라 적용 방식을 많이 달리해야 한다는 걸 경험했어요.
개인적인 해석으로는 FSD는 어플리케이션 성격의 프로젝트에 조금 더 잘 어울린다고 생각합니다. 페이지가 많지 않고 사용자들은 여러 기능을 오가며 사용하고, 도메인 엔티티들이 전체 앱에서 공통으로 활용되는 경우에는 FSD의 계층 구조가 잘 맞더라구요.
하지만 제가 현재 진행하고 있는 대형 웹페이지 서비스 리뉴얼에서는 상황이 달랐습니다. 페이지가 상당히 많고 각 페이지들이 독립적인 특성을 가지고 있다보니, FSD를 그대로 적용하면 되려 파편화가 발생했어요.
예를 들어, 문의 페이지와 소개 페이지, 제품 소개 페이지는 같은 서비스 내에 있지만 사실상 완전히 다른 미니 사이트 같은 느낌이었거든요. 공통된 엔티티라고 해봤자 계정 정보와 일부 설정 그리고 상품 정보 정도였고, 나머지는 각 메뉴별로는 함께 쓰지만 페이지 간에는 상당히 독립적이었죠.
그래서 메뉴별로 MSA스러운 구조가 훨씬 더 잘 어울린다는 판단을 했습니다. 전체적으로는 페이지와 메뉴를 중심으로 하는 상위 구조를 만들고, 각 메뉴 안에서는 다시 엔티티, 화면, 기능으로 분리하는 이중 구조로 설계했어요.
또한 계층적 구조를 폴더명의 알파벳 순서로도 표현하고 싶어서 이름을 조금 바꿔봤다는 점입니다. base, entities, features, modules, pages 이렇게 해서 알파벳순으로 나열했을 때 자연스럽게 계층 관계가 드러나도록 만들어봤습니다.
그래서 최종 채택된 모양은 다음과 같습니다. 주요 메뉴별로 분리하고 페이지별로 FSD를 적용해서 계층형 구조와 페이지내 어떤 기능, 어떤 데이터를 쓰는지 시각적으로 알 수 있게 하면서 너무 세분화가 심화되지 않도록 조정해보았습니다.
/apps # MSA하도록 서비스를 분리
/1-intro # 주요 메뉴
/app # Route및 레이아웃
/entities # 메뉴 내 공통 데이터
/pages # 세부 페이지들
/cases
/base # 페이지 공통 코드 (UI, library)
/entities # 페이지 엔티티
/features # 내부 기능
/modules # 화면 구성 모듈 (widgets 대신)
/PageCase.tsx
/news
/2-product
/3-support멘탈 모델과 폴더 구조의 일치
결과적으로 폴더 구조가 개념적인 구조와 더 가까워지면서 프로젝트의 코드를 이해하는 게 한결 더 쉬워졌습니다. 새로운 개발자가 합류해도 "제품 소개 관련 기능을 수정해달라"고 하면 자연스럽게 /pages/products 폴더로 가서 관련 코드를 찾을 수 있게 되었고요.
무엇보다 내 머리속에 있는 프로젝트의 개념적 구조가 폴더 구조와 닮아있다는 느낌이 들 때 정말 만족스러웠어요. 코드를 찾기 위해 여러 폴더를 헤매지 않아도 되고, 새로운 기능을 어디에 넣을지 고민하는 시간도 줄어들었습니다.
이런 경험을 통해 깨달은 건, 좋은 폴더 구조란 결국 그 프로젝트를 다루는 사람들의 멘탈 모델과 얼마나 일치하느냐의 문제라는 점입니다. FSD든 다른 방법론이든, 그 방법론이 우리 프로젝트의 특성과 팀의 사고방식에 맞게 변용될 수 있다면 그게 바로 우리에게 맞는 최적의 구조가 되는 거라 생각합니다.
끝으로...
이 글을 시작할 때 받은 질문은 "FSD가 복잡해 보이는데, 테오는 어떤 구조를 선호하나요?"였습니다. 프로젝트마다 그리고 제가 성장함에 따라 프로젝트의 폴더구조는 변해갔구요 지금은 FSD와 유사한 형태지만 완전하게 동일한 형태는 아닙니다. 다만 지금 제가 쓰고 있는 폴더구조를 직접적으로 설명하는 것으로는 좋은 폴더 구조의 고민에 대한 대답이 되기가 어렵다 생각했습니다. 그래서 단순히 "이런 구조를 선호합니다"고 답하기보다는, 왜 그런 구조들이 필요해졌는지, 어떤 문제들을 해결하려다가 자연스럽게 진화해온 것인지를 알려드리고 싶었습니다.
최대한 맥락을 담아내고자 했고 아직 정형화된 주제가 아니라 하나의 제안이자 담론을 풀어내는 것이기에 혹여나 마치 이게 정답인것 처럼 전달되지 않도록, 그러나 충분한 소프트웨어와 프론트엔드 전공지식 기반의 정보를 전달할 수 있도록 많은 노력을 했습니다.
프론트엔드 아키텍처의 발전은 결국 개발하면서 겪게 되는 현실적인 문제들에 고민들이 수렴하는 결과입니다. /component, /hooks, /service, /utils 등의 역할 기반 구조도 프론트엔드 체계가 확립되어감에 따라 자리 매김을 한 것이죠. 컴포넌트 재사용성에 대해서 여러가지 시행착오을 겪어가며 순수 UI와 도메인 컴포넌트의 본질적 차이를 구분하기 시작하며 폴더 구조 또한 세분화 되었습니다. 데이터를 중심으로 하는 도메인 중심의 구조와 화면을 점진적으로 분리하는 구조가 그리고 요구사항을 더 잘 이해하기 위해 기능을 중심으로 하는 폴더 구조등이 제안이 되고 있습니다.
개발자로서 우리가 폴더 구조를 고민하는 것은 단순히 파일 정리가 아닙니다. 그것은 코드의 관계와 의도를 명확히 표현하고, 팀원들과 효율적으로 소통하며, 미래의 변경에 유연하게 대응할 수 있는 기반을 만드는 일입니다. 좋은 아키텍처는 개발자가 본질적인 문제 해결에 집중할 수 있게 해주는 든든한 발판이 되어줍니다.
이 글을 통해서 얻어가셨으면 하는 것은 특정한 폴더구조가 아니라 소프트웨어 공학의 원칙에 따라 진화해가는 사고의 흐름 입니다. FSD뿐만 아니라 다른 아키텍처든, 그 구조가 왜 그렇게 설계되었는지 이해하고, 여러분의 프로젝트 상황에 맞게 유연하게 적용할 수 있는 판단력을 기르는 것이 목표였습니다. 프로젝트 규모, 팀 크기, 도메인 복잡도, 성장 단계에 따라 최적의 구조는 달라집니다. 중요한 것은 코드의 자연스러운 경계를 이해하고, 응집력 있게 구성하는 원칙을 갖는 것입니다.
이런 고민을 하고 계신 모든 개발자분들께 이 글이 조금이나마 도움이 되었기를 바랍니다. 완벽한 구조는 없지만, 더 나은 구조를 찾아가는 여정 자체가 우리를 성장시키는 소중한 경험이라고 생각합니다. 혹여 폴더 구조에 관련해서 고민을 하거나 시행착오를 겪는 중이라면 여러분만의 최적의 구조를 찾아가는 과정에서 이 글이 그 고민을 해결하는데 조금이나마 도움이 될 수 있기를 바랍니다.
긴 글 끝까지 읽어주셔서 정말 감사합니다. 여러분의 프로젝트에서도 코드가 멘탈모델과 일치해서 자연스럽게 흘러가는 구조를 만나실 수 있기를 응원합니다!

30개의 댓글


좋은 글 감사합니다!
이 주제와 상관없을지도 모르나, 이러한 글들을 보고 poc 후 실적용 해볼라치면 실무에서 자주 벽이되는 고민이 있어 여쭤보고 싶습니다.
일을 하다 보면 analytics 관련 요구사항이 기능 개발이 거의 끝나갈 무렵에 뒤늦게 들어오는 경우가 많습니다. or 빠르게 나왔다고 하더라도 analytics의 스펙이 기능단위로 딱 맞아 나올순 없는것 같습니다!
그러다 보니, 기존에 구조적으로 잘 나눠놓은 코드가 analytics 이벤트/파라미터를 넣으면서 구조가 무너지는 경험을 하게되고 그에 대한 반작용으로 점점 코드를 러프하게 짜게되는 부분을 느낄수 있었는데요.
혹시 이런 상황에서 구조적 일관성을 유지하면서 analytics를 효과적으로 관리하는 방법이나, 적용해본 팁이 있으시다면 공유해주실 수 있을까요?

좋은 관점이에요!
다만 저 같은 경우에는 협업해야한다는 상황에서
업무분장후 소스코드가 서로 겹치지 않게 조율하는 것도
실무에서는 많은 에너지를 줄이는 것 중에 하나라고
생각이 들어요 (아키텍쳐 모델을 따르려 노력 하는 것보다 큰 걸림돌)
해서 마지막에 제안하신 메뉴 구조별로 1차 구분 후 FSD 규칙을
적용하는게 굉장히 인상적이엇습니다
페이지 단위로 한 번더 필터링을 하면 너무 세분화 될까요?
저는 그렇게 한번 구성을 해봐야겟네요 ㅎㅎ

많은 시행착오를 통해 결국 현재 진행 중인 프로젝트에 어떤 폴더 구조를 채택 했는지 알 수 있어서 재밌게 읽고 갑니다!
좋은 글 남겨주셔서 감사합니다.





좋은 글 너무 감사합니다! 저도 요즘 프론트에서의 관심사의 분리와 아키텍처 구조에 대해 관심이 있었는데, 어떤 발전 방향을 거쳤는지는 알지 못했거든요. 명료하게 설명해주셔서 이해하기 수월했습니다!
그리고 이번 글의 내용을 좀 더 깊이 공부해보고 싶어졌습니다. 테오님께서 이번 글을 쓰시면서 도움을 받은 서적이나 추천해주실만한 책이 있으실까요??

좋은 글 감사합니다.
3년차 개발자로 최근 팀에 FSD를 도입하게 되어 구조 관련 정리를 하던 중, 이 글을 발견하고 큰 도움이 되었어요!
특히 구조와 현재 서비스의 조합을 고민하고, 그에 따라 결정을 내리는 과정이 인상 깊었어요. 저도 FSD를 적용하면서 “이게 맞나?” 싶은 순간들이 많았고, 그때마다 팀원들과 논의했지만 명확한 해답보다는 찝찝한 결론으로 끝나는 경우가 많았습니다. 그런데 돌이켜보니, 프로젝트의 특성과 구조의 목적을 깊이 이해하지 못한 채 적용하고 있었다는 걸 깨닫게 되었어요. FSD 공식 문서만 다시 읽어봐도 구조가 지향하는 방향과 적합한 맥락을 충분히 유추할 수 있었는데... 반성이 됐습니다. 😅
한 가지 궁금한 점이 있는데요 — /1-intro, /2-product 등 메뉴 간 구조가 완전히 분리된 상태에서, 각 메뉴간에 공통 UI나 유틸이 필요한 경우에는 shared 같은 별도 레이어를 두고 관리하셨을까요?

개인적인 해석으로는 FSD는 어플리케이션 성격의 프로젝트에 조금 더 잘 어울린다고 생각합니다. 페이지가 많이 않고 사용자들은 여러 기능을 오가며 사용하고, 도메인 엔티티들이 전체 앱에서 공통으로 활용되는 경우에는 FSD의 계층 구조가 잘 맞더라구요.
ㅡㅡㅡ
여기 오타있어요!
"페이지가 많이 않고"
"많지 않고" 를 의도하신거같아요!
이와 별개로 정말 훌륭한 글이었습니다.
앞으로도 이런 글 많이 부탁드리겠습니다.
자주 놀러올게요! 감사합니다.

저는 프론트엔드를 공부하기 시작하면서 폴더구조에 대해 고민을 많이하고있는데 정말 많은 참고가되고 어떻게 변해왔는지 알 수 있는 글이라 선생님께 강의를 받은 기분이 들어요!
다만 제가 글을 읽으면서 이해가 잘 가지 않은 부분이 있는데요,
entities와 features의 경계가 생각보다 애매했고, 팀원들과 이 구조에 대해 논의하는 것도 쉽지 않았습니다.
라고 작성해주신 부분을 보면서 저는 기능과 엔티티보다는 기능과 위젯이 헷갈려서요 ㅠㅠ
1. 엔티티는 예시에 작성해주신 아래쪽에 포스트카드도 포함하시는걸까요? 저는 api요청 후 받은 응답을 dto로 바꾸고 이 dto를 우리가 사용할 데이터타입으로 바꾸어둔것만 엔티티라고 생각을 했거든요.
2. 기능쪽 예시를 보면 저는 이게 위젯과 다른점이 뭔지 직관적으로 와닿지가 않습니다..ㅠㅠ 검색 결과에 따라 관련도 점수를 작성하는부분이 로직과 관련된 부분이라 이쪽 부분만 기능이라고 하시는걸까요? 예시코드를 언뜻 보기엔 그냥 여러 컴포넌트로 만든 위젯의 일부분처럼 느껴지는데 제가 무엇을 잘못 이해한건지 아직 잘 모르겠네요…
프론트엔드 폴더 구조의 진화는 결국 개발자의 머릿속 멘탈 모델과 실제 코드 구조를 일치시켜 인지적 부담을 줄이려는 여정이군요!
좋은 글 잘 읽고 갑니다.