Introduction
Detector는 굉장히 빠르게 발전하고 있지만, 아직도 다른 task에 대해서는 또다른 pre-possessing / training pipeline이 필요하게 되고 이런 작업은 굉장히 cost가 높다.
그렇기 때문에 이 논문에서는 inference time에 영향이 없는 범용적이고도 효과적인 접근법들을 소개하려고 한다.
이 논문은 다음과 같은 내용에 기여한다
- 다양한 heuristic 기법에 대해 비교해본다.
- coherent mixup method가 실험적으로 모델 일반화 성능에 긍정적인 영향을 미침을 보인다.
- 모델 일반화 성능을 높이고 over-fitting을 방지할 수 있는 data augmentation의 정도에 대해 연구한다.
- network architecture의 변화 없이 약 5%의 성능 상승을 얻어냈다.
general pipeline구축이 어려운 이유
one stage 와 two stage 방식의 차이
-> ex) one stage 방식은 saptial variation 정보가 부족하기 때문에 spatial data augment방식이 굉장히 중요하다.
Mixup
mixup은 복잡한 공간 변화를 적용함으로써 현실에서 있을법 한 작은 공간적 신호의 변화를 일으킨다.
Mixup은 beta distribution에서(classification에서는 alpha=0.2=beta) 값을 샘플링 하는 방식을 선택하는데, 이 논문에서는 이 alpha,beta값을 증가 시켜가며 언제 최고의 성능을 내는지 테스트해본다.
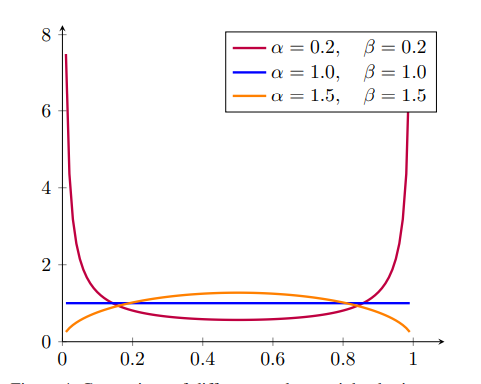
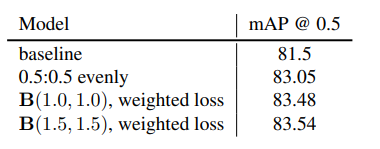
이 논문에 저자는 alpha값을 증가시킴으로써 더욱 생동적이고 현실적인 이미지를 그려낼 수 있다고 생각하였고, 실험적으로 1.5의 값에서 최고의 성능을 얻어냈다.
(최소 1의 값을 권장하고 있다)
-> 이런 현상에 대해 object detection이 classifiaction에 비해서 mutual object occlusion의 성향의 강하기 때문이라 말한다.(crowded path에 대한 구분이 중요하다)
결과적으로 mixup은
- 더욱 robust한 모델을 만드는데 도움을 준다.
- crowded object에 대한 성능을 올려준다.
- 등장한적 없는 객체에 대한 성능을 올려준다.
Label Smoothing
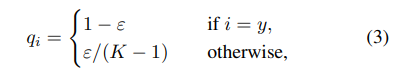
보통 class를 구분하는 과정은 classification과 똑같이 출력된 output feature vector에 대한 softmax를 구하기 때문에 classification과 같이 label smoothing을 적용해 성능 향상을 기대할 수 있다.
Data preprocessing
classification -> geometric transform에 대하여 굉장히 tolerant하기 때문에 확률적으로 공간 정보를 변형시키는 방법이 권장된다. (ex flip rotate crop)
object detection -> 이런 변화들에 대해 굉장히 민감하게 반응할거라 예상된다.
이런 이유로 이 논문은 다음과 같은 방식들을 실험해본다.
1.random geometry transformation (random cropping /expansion/flip/resize등)
2.random color jittering(brightness/hue/saturation/contrast)
여기서 random cropping은 region proposal이 제공되는 two-stage detection의 경우에는 필요가없다.
training schedule revampling
faster-rcnn/yolo같은 논문에서는 step scheduler를 사용하였는데 그 이후 cosine이나 warmup같은 방식이 많이 나와있음으로 이런 방식을 사용함으로써 성능 향상을 얻을 수 있겠다.
부가적인 방법론
synchrosized batch normalization -> multi gpu를 활용
yolo -> image random reshape
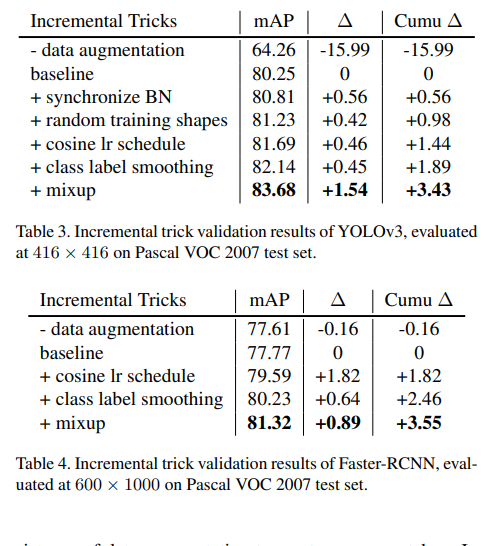
주목할점은 2-stage detection에서 data augmentation의 성능인데,
region proposal 방식이 어느정도 geometric transformation의 기능을 대체하고 있음을 알 수 있다.
