Roberta(2019)
논문 ; RoBERTa: A Robustly Optimized BERT Pretraining Approach
- bert문제 제기
- 2019 bert가 상당히 undertrained된 것을 발견 → model 성능을 높이기 위한 parameter tuning.
parameter tuning
- 더 큰 batch와 data를 사용하여 training 진행.
- large batches는 optimizer speed up
- NSP loss 제거.
- 더 긴 입력 sequence를 넣어줌.
- dynamic masking 사용.
- bert ; static mask - mask를 한번만 하고 고정.
- roberta ; dynamic masking - 매 epoch마다 다 다른 mask를 씌움.
- training data를 10배로 복사.
- 40epoch ==똑같은 것을 4번만 본다
bert vs roberta
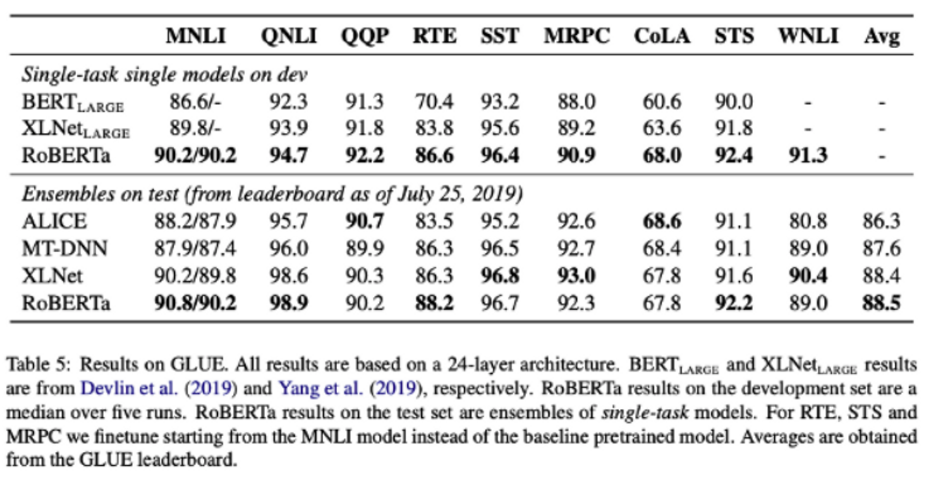
참고 ; https://lsjsj92.tistory.com/626
albert (2020)
논문 ; ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
- 기존 bert의 문제점
; bert와 같은 pre-trained language model은 모델의 크기가 커지면 성능이 향상되나, memory limitation, training time, memory degradation의 문제 발생
-
memory limitation ; 모델의 크기가 메모리에 비해 큰 경우 학습시 out of memory 발생
-
training time ; 학습하는데 오랜 시간이 소요됨
-
memory degradation ; layer의 수/ hidden size가 너무 커지면 모델 성능 감소
-
bert의 다음 사항을 개선하여 모델의 크기 줄이고 더 높은 성능을 얻음
- factoriazed embedding parameterization ; input layer의 parameter수를 줄임 → 모델 크기 줄임
- cross-layer parameter sharing ; transformer의 각 layer간 parameters를 공유하여 사용 → 모델 크기 줄임
- sentence order prediction - bert에서의 NSP 대신 두 문장 간 순서를 맞추는 방식으로 학습 → 성능 향상
일반적으로 Laguage representation 모델의 layer, hidden size가 클 때 더 높은 성능을 보임. but 무작정 늘리는게 좋을까?
- 모델의 크기가 클 때 발생하는 문제
-
메모리 부족
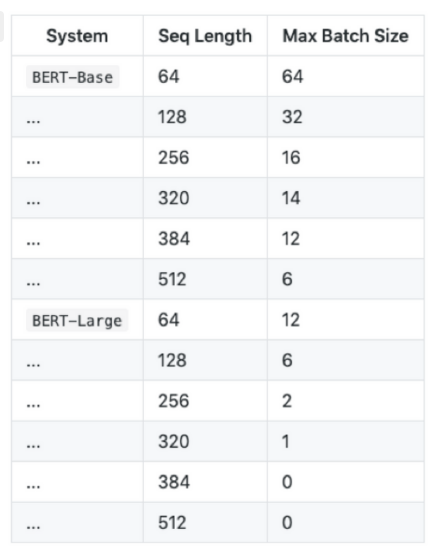
input sequence length가 384이상이면, 한 문장에 대한 훈련, inference 불가.
-
out of memory가 발생하지 않을 때, input length에 따른 maximum batch size
-
- 학습시간 오래걸림 Google은 학습 시간을 줄이기 위해 여러장의 TPU를 활용하여 학습하였습니다. BERT base의 경우 16개의 TPU로 4일 정도 걸렸고, BERT large의 경우 64개의 TPU로 4일 정도 걸렸습니다.
- lm도 너무 커지면 성능이 떨어지는 것이 증명됨.
- solution
-
factorized embedding parameterization
bert에서는 input token embedding size==hidden size==input/output embedding size
-

albert에서는 input token embedding size<<hidden size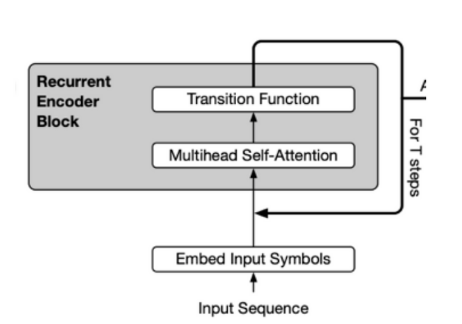
이렇게 설정한 이유 ;
input token embedding - 각 token의 정보를 담고 있는 vector생성.
output - 해당 token과 주변 token과의 관계를 반영한 contextualized representation.
→담고 있는 정보량 자체가 다르기 때문에 input token의 크기가 더 작아도 된다고 생각??????
- **cross layer parameter sharing** - layer간 parameter 공유

forward prop에서 성능이 약간 떨어지나, 크게 떨어지지 않음. 파라미터를 공유하게 되면 전체 파라미터의 수는 줄어들고 이는 곧 모델 크기가 줄어듦.
- **sentence order prediction(sop)**
- NSP와의 차이
NSP는 두 번째 문장이 첫 문장의 다음 문장인지를 맞추는 학습 데이터 구성시, 두번째 문장은 실제 문장 혹은 임의의 문장. 임의의 문장은 완전히 다른 topic 문장일 확률이 높으므로 문장 간 연관 관계 학습이 아니라 첫/두번째 **문장이 같은 topic에 대해 말하는지를 판단**함.
sop는 실제 연속인 두 문장과 두 문장의 순서를 앞뒤로 바꾼 것으로 구성되고 **문장의 순서가 옳고 그른지 판단.**
roberta, bert-large와 비교해도 albert의 성능이 더 좋다는 것!
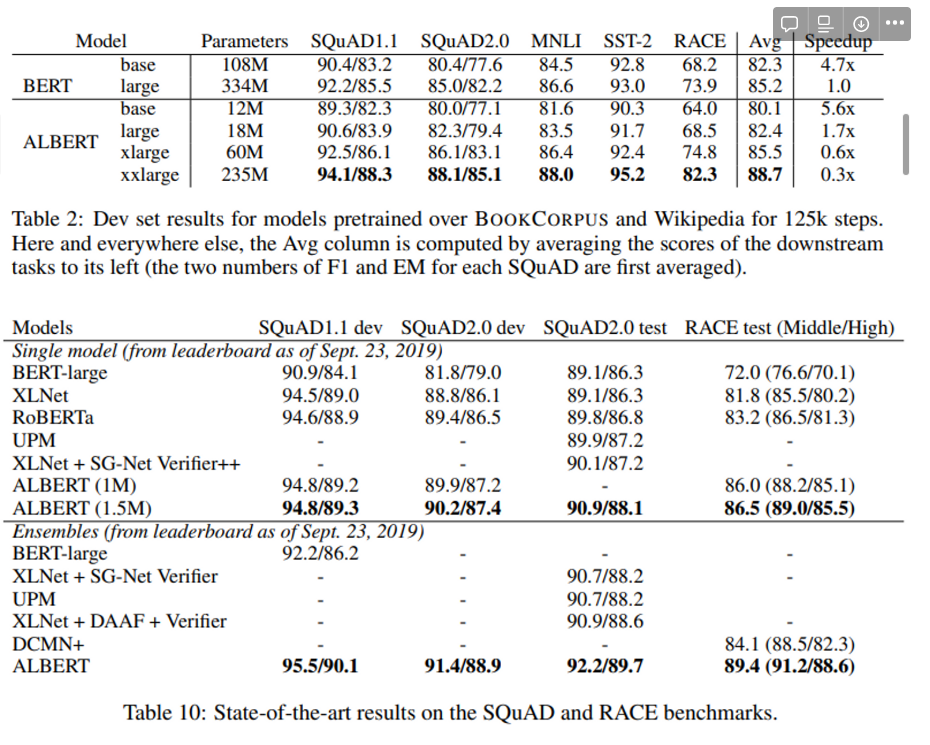
참고 ; https://y-rok.github.io/nlp/2019/10/23/albert.html
ELECTRA(2020)
논문 ; ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATOR
- gan과 비슷한 구조로 pre-trained에 focus를 맞춤
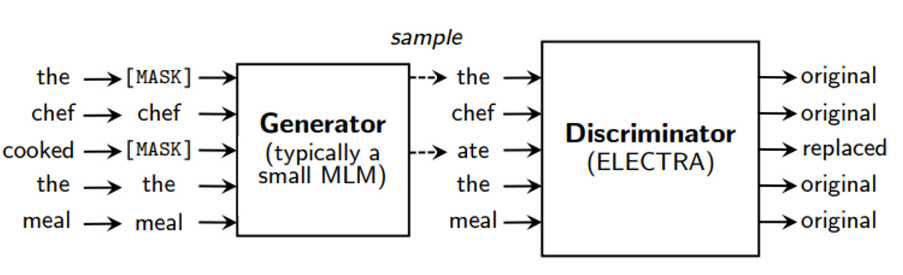
- generator ; MLM에서 나온 단어를 학습시킴
- discriminator ; 모든 단어를 보면서 원본인지 아닌지 식별
- generator size < discriminator size
- 둘이 같은 사이즈인 경우, 2배의 compute
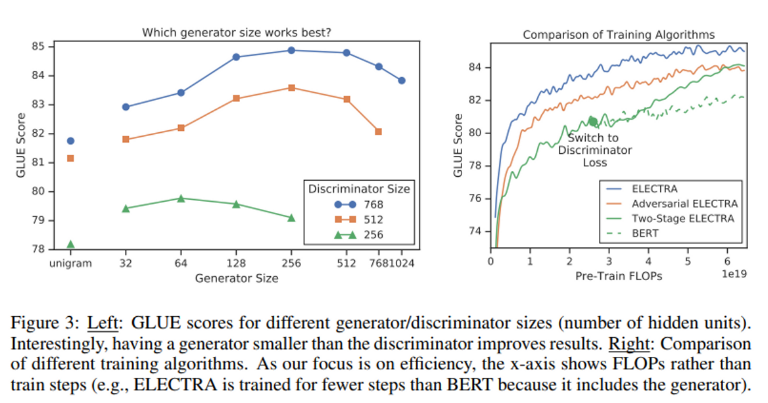
- generator가 너무 강하면 discriminator가 토큰의 진위여부를 가르는 task를 어려워 효과적인 학습을 방해한다고 추측.- weight sharing ; embedding layer만 공유 (∵ 모든 layer을 공유하려면 generator size== discriminator size여야함)
- pre training의 efficiency를 증가시키기 위함.
- 컴퓨팅이 적고 성능이 좋게나옴.
- discriminator가 mask되었다가 generator을 통해 나온 단어를 감지
- generator가 replaced token detection 수행. mask가 씌워진 토큰을 다른 토큰으로 생성.(MLM 수행)
- 모든 토큰을 학습하기 때문에 computational 효율 획득.
small/large model에서 bert vs electra
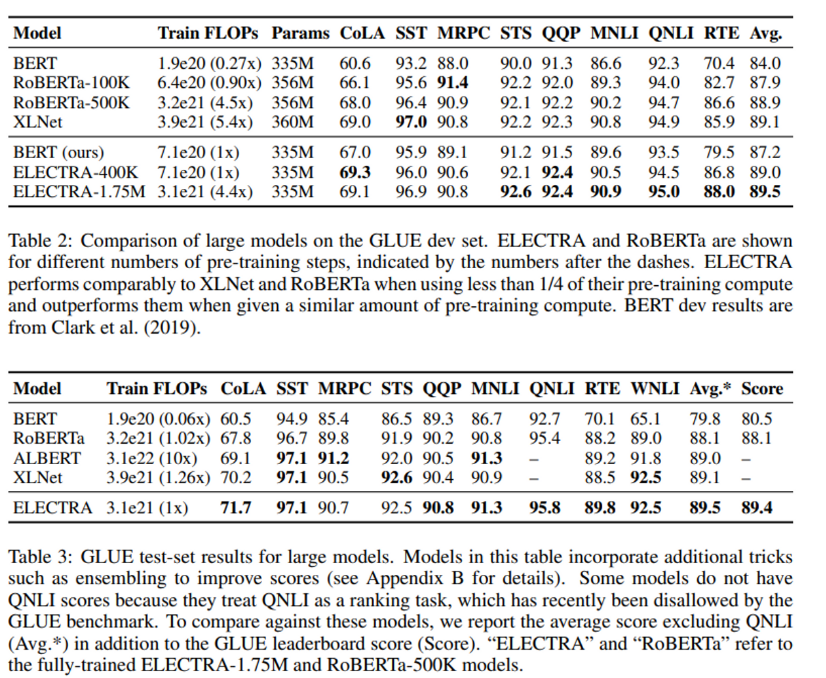
electra의 모델이 작을 수록 성능이 높아지고 bert와의 성능차이가 커짐.
모델이 작아도 bert에 비해 빠르게 수렴.
electra가 fully trained됐을떄, bert보다 더 높은 정확도 달성
