[코드로 배우는 스프링부트 웹 프로젝트] - Spring Data JPA
ORM(Object Relational Mapping)
프로그래밍에서 객체지향의 개념과 관계DB가 유사한 특징을 가지고 있음을 기반으로, 객체지향을 자동으로 관계형 데이터베이스에 맞게 처리해주는 기법에 대한 아이디어가 논의
JPA(Java Persistence API)
ORM을 JAVA에 맞게 사용하는 스펙, 스프링부트는 Hibernate라는 프레임워크를 이용
Spring Data JPA Dependency가 Hibernate 사용을 돕고, 이를 통해 JDBC -> DB로 데이터가 이동합니다.
- JPA를 통해 관리하는 객체를 위한 엔티티 클래스 생성
프로젝트 패키지 아래에 entity 패키지 생성 -> Memo 클래스 생성
package org.zerock.ex2.entity;
import jakarta.persistence.*;
import lombok.ToString;
@Entity
@Table(name="tbl_memo")
@ToString
public class Memo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long mno;
}@Entity : 엔티티 클래스임을 보여줌
@Table : 변수로 테이블명과 인덱스 지정 가능
@Id : Primary Key를 의미함
@GeneratedValue : 자동 생성
- AUTO: JPA 구현체(Hibernate)가 생성방식을 결정
- IDENTITY: 데이터베이스가 생성방식을 결정
- SEQUENCE: 데이터베이스의 sequence를 이용하여 키를 생성(@SequenceGenerator와 사용)
- TABLE: 키 생성 전용 테이블을 생성하여 키 생성(@TableGenerator와 사용)
@Column: 추가적인 필드에 대해 속성 지정해주는데 사용
@Builder: 객체 생성하는데 사용, @AllArgsConstructor와 @NoArgsConstructor를 함께사용
@Transient: 데이터베이스 테이블엔 생성되지 않는 필드 지정, 비밀번호 확인과 같은 칼럼에 사용함
application.properties에 아래 항목을 추가하면 데이터베이스에 어떤 테이블이 생성되는지 확인가능합니다.
spring.jpa.hibernate.ddl-auto=update //Update시 테이블이 존재하면 ALTER를 이용하고, 없으면 CREATE이용
spring.jpa.properties.hibernate.format_sql=true //Hibernate가 동작하면서 발생하는 SQL을 포맷팅하여 출력
spring.jpa.show-sql=true //JPA 처리 시 SQL을 보여줄지 결정여기서 DDL(Data Definition Language)은 데이터베이스에서 쓰이는 용어로 CREATE, ALTER, DROP등의 데이터 정의어를 의미합니다.
이제 실행하면 MariaDB에 테이블이 생성되고, 스프링부트의 log에 CREATE SQL이 보여집니다.
- 엔티티 객체를 처리하는 기능을 가진 레포지토리(JpaRepository)
package org.zerock.ex2.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.zerock.ex2.entity.Memo;
public interface MemoRepository extends JpaRepository<Memo, Long> {
}JpaRepository를 상속받을 때 엔티티의 타입과 @Id의 타입을 넣어주면 스프링 빈으로 레포지토리가 등록됩니다.
이 MemoRepository의 클래스명을 살펴보면 jdk.proxy3.$Proxy111로 출력되었습니다. 스프링이 자동으로 클래스를 생성하는데, 이 객체는 자바에서 생성한 Dynamic Proxy입니다.
Dynamic Proxy에 관한 간략한 설명은 해당 블로그에서 참고하시길 바랍니다.
이제 MemoRepository를 이용하여 데이터베이스의 CRUD 작업을 진행할 수 있습니다.
아래 코드들은 test 패키지에서 생성된 테스트 코드입니다.
- CREATE(삽입)
@Test
public void testInsertDummies() {
IntStream.rangeClosed(1,100).forEach(i -> {
Memo memo = Memo.builder().memoText("Sample..." + i).build();
memoRepository.save(memo);
});
}- READ(조회)
findById()를 이용한 조회
@Test
public void testSelect() {
Long mno = 100L;
Optional<Memo> result = memoRepository.findById(mno);
System.out.println("=================");
if(result.isPresent()) {
Memo memo = result.get();
System.out.println(memo);
}
}getReferenceById()을 이용한 조회, @Transactional을 이용하여 메서드가 하나의 트랜잭션임을 명시해야합니다.
@Test
@Transactional
public void testSelect2() {
Long mno = 100L;
Memo memo = memoRepository.getReferenceById(mno);
System.out.println("=================");
System.out.println(memo);
}둘은 코드상에서 거의 차이가 없지만, 결과를 보면 동작이 다름을 알 수 있습니다.
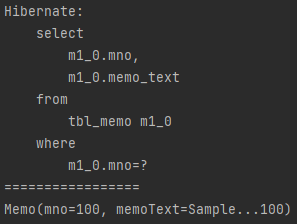
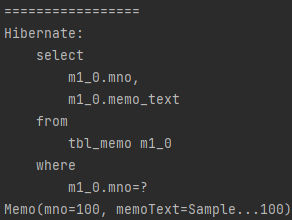
findById()는 메서드가 호출된 즉시 SQL문이 실행되었는데, 이는 바로 데이터베이스에 접근했다는 것을 의미합니다.
그에 비해 getReferenceById()는 실제로 SQL의 결과문이 필요해진 상황에서 SQL문을 실행시켰는데, 처음 함수가 호출되었을 때는 프록시 개체만 기억하고 있다가 실제로 필요해지면, 해당 프록시 객체를 이용하여 데이터베이스에 접근하는 방식입니다.
- UPDATE(수정)
Update는 Insert와 동일하게 save를 사용하는데, 내부적으로는 Id가 존재하는지 Select문을 통해 확인 후, 존재한다면 Update 쿼리문을 사용합니다.
@Test
public void testUpdate() {
Memo memo = Memo.builder().mno(100L).memoText("Update text").build();
System.out.println(memoRepository.save(memo));
}- DELETE(삭제)
마찬가지로 Select를 통해 Id 존재여부 확인 후 Delete 쿼리문을 사용합니다.
@Test
public void testDelete() {
Long mno = 100L;
memoRepository.deleteById(mno);
}페이지 처리
JPA는 Dialect를 이용하여 DB에 맞는 쿼리를 자동으로 작성해줍니다. 따라서 페이징 처리 역시 JPA 인터페이스가 상속받고 있는 Pageable 인터페이스, 그 중에서 Pageable 인터페이스를 구현한 PageRequest 클래스를 사용하여 페이지 처리를 할 수 있습니다.
PageRequest 클래스는 protected 생성자를 이용하기 때문에 new 생성자를 사용할 수 없고 static 메서드인 of를 이용하여 처리합니다.
//0이상의 페이지 번호(page)와 개수(size)
of(int page, int size)
//정렬방향(direction), 정렬기준 필드(properties)
of(int page, int size, Sort.Direction direction, String... properties)
//정렬 관련 정보(sort)
of(int page, int size, Sort Sort)페이지처리를 할 때 Page<T>가 리턴값이라면 반드시 Pageable인자가 들어가야합니다.
아래는 1페이지의 데이터 10개를 가져오는 테스트 코드입니다. mno는 내림차순, 같다면 memoText는 오름차순으로 정렬하여 출력합니다.
@Test
public void testPageDefault() {
Sort sort1 = Sort.by("mno").descending();
Sort sort2 = Sort.by("memoText").ascending();
Sort sortAll = sort1.and(sort2);
Pageable pageable = PageRequest.of(0,10, sort1);
Page<Memo> result = memoRepository.findAll(pageable);
System.out.println(result);
System.out.println("===============================");
System.out.println("Total pages: " + result.getTotalPages()); //총 페이지
System.out.println("Total count: " + result.getTotalElements()); //총 개수
System.out.println("Page Number: " + result.getNumber()); //현재 페이지
System.out.println("Page Size: " + result.getSize()); //페이지의 크기(element 개수x)
System.out.println("has next page? " + result.hasNext()); //다음 페이지 여부
System.out.println("first page? : " + result.isFirst()); //첫번째 페이지 여부
for(Memo memo : result.getContent()) {
System.out.println(memo);
}
}페이지 처리와 관련하여 Hibernate가 처리한 쿼리문을 보면 의문인 점이 보입니다.
아래에는 전혀 필요없을 것처럼 생긴 count 쿼리를 실행한다는 점입니다. 하지만 count 쿼리가 있어야 전체 페이지를 구할 수 있기 때문에 이 쿼리문은 필수적입니다.
아래에 @Query로 JPQL을 value로 주는 방법에 대해 설명을 써놓았는데, 이때 Page<T>가 리턴값이라면 value에도 count 쿼리문이 존재해야 합니다.
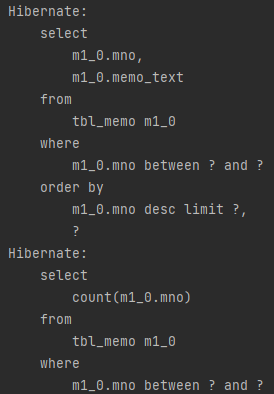
쿼리 메서드
쿼리메서드는 메서드 이름 자체가 쿼리의 구문으로 처리되는 기능입니다. 다양한 쿼리메서드는 JPA Reference Documentation에서 확인가능합니다.
공식 문서를 보면 여러 Keyword로 묶인 메서드가 보이는데, 사용하고 싶은 쿼리문 자체를 직접 메서드로 만들어서(예를 들어 findByLastnameAndFirstname은 LastName과 Firstname을 이용해 find하라는 쿼리문을 만들어줌) 사용하면 됩니다. 그리고 그 메서드의 인자로 요구되는 것은 JPQL snippet의 물음표의 개수에 따라 달라집니다.
사용방법은 간단합니다. 먼저 사용하고자하는 메서드를 인터페이스에 정의합니다.
public interface MemoRepository extends JpaRepository<Memo, Long> {
List<Memo> findByMnoBetweenOrderByMnoDesc(Long from, Long to);
}그리고 테스트에서 이 메서드를 사용하면 됩니다.
@Test
public void testQueryMethods() {
List<Memo> list = memoRepository.findByMnoBetweenOrderByMnoDesc(70L, 80L);
for(Memo memo : list) {
System.out.println(memo);
}
}정렬과 관련한 부분은 Pageable을 인자로 넣어주면서 좀 더 간단하게 할 수 있습니다.
public interface MemoRepository extends JpaRepository<Memo, Long> {
List<Memo> findByMnoBetween(Long from, Long to, Pageable pageable);
}@Test
public void testQueryMethodWithPageable() {
Pageable pageable = PageRequest.of(0, 10, Sort.by("mno").descending());
List<Memo> result = memoRepository.findByMnoBetween(10L, 50L, pageable);
for(Memo memo : result) {
System.out.println(memo);
}
}책에서는 Pageable이 인자로 들어가면 리턴값이 무조건 Page<T> 형태어야 한다고 하지만, Reference를 찾아본 결과로는 List나 Slice 형태도 허용한다고 적혀있습니다.
Select 쿼리 외에도 여러 가능(set, delete) 등을 지원합니다.
@Test
@Commit
@Transactional
public void testDeleteQueryMethods() {
memoRepository.deleteMemoByMnoLessThan(10L);
}하지만 이 방식은 Delete를 1개씩 하기 때문에 잘 사용되지는 않습니다. 대신에 @Query 어노테이션을 활용하여 개발합니다.
@Query
@Query 어노테이션에 주는 JPQL(Java Persistence Query Language) value를 통해 원하는 쿼리문을 실행시킬 수 있습니다. DB의 SQL문과 형태가 거의 유사한데, 테이블(릴레이션) 대신 엔티티 클래스로 정의할 수 있고, 테이블의 칼럼(애트리뷰트) 대신에 필드를 이용하여 작성할 수 있기 때문에 SQL만 제대로 알고 있다면 쉽게 사용할 수 있습니다.
@Query("select m from Memo m order by m.mno desc")
List<Memo> getListDesc();단, Insert, Update, Delete와 같은 기능은 @Modifying, @Transactional과 함께 사용해야합니다.
쿼리 value에 인자를 통해 전달할 값을 넣을 수 있습니다.
?1,?2와 같이 인자 1번, 2번을 사용한다고 알려주는 방법
@Query("select m from Memo m where m.mno = ?1")
Memo findMemoById(Long num);:인자명으로 파라미터 이름을 명시해주는 방법
@Transactional
@Modifying
@Query("update Memo m set m.memoText=:memoText where m.mno=:mno")
int updateMemoText(@Param("memoText") String text, @Param("mno") Long num);#{#~}과 같이 자바 빈 스타일을 이용하는 방법(객체를 사용)
@Transactional
@Modifying
@Query("update Memo m set m.memoText=:#{#param.memoText} where m.mno=:#{#param.mno}")
int updateMemoText(@Param("param") Memo memo);@Query(value = "select m from Memo m where m.mno > :mno", countQuery = "select count(m) from Memo m where m.mno > :mno") Page<Memo> getListWithQuery(Long mno, Pageable pageable);위에서 언급했던 것처럼, Page<T>가 리턴값이라면 countQuery와 Pageable 인자는 필수적입니다.
@Query의 또다른 장점은 리턴 타입을 Object[] 형태로 선언할 수 있다는 점입니다. Join이나 Group By를 사용하면 결과로 적당한 엔티티 타입이 존재하지 않을 수 있는데, 이때 Object[]를 리턴값으로 지정할 수 있습니다.
@Query(value = "select m.mno, m.memoText, CURRENT_DATE
from Memo m where m.mno > :mno",
countQuery = "select count(m)
from Memo m where m.mno > :mno")
Page<Object[]> getListWithQueryObject(Long mno, Pageable pageable);Native SQL(DB에 의존적)으로 처리할 수 있지만 JPA의 장점과 거리가 먼 방식이기 때문에 생략하겠습니다.
