
루씬은 효율적으로 색인 작업을 하기 위해 내부에 일정 크기의 버퍼를 가지고 있습니다.
이를 인메모리 버퍼(In-memory buffer)라고 하는데요.
만약 인메모리 버퍼가 없다면, 색인 요청이 올때마다 (데이터 유실을 막기 위해) 매번 동기적으로 세그먼트를 생성해야 할 것입니다.
세그먼트(Segment)란?
색인 및 쿼리 요청시에 루씬 인덱스가 데이터를 쓰고, 읽는 최소 단위
모든 요청마다 세그먼트를 생성하게 되면 세그먼트 수가 굉장히 많아지게 되고 조회시 지연이 발생하여 비효율적 입니다.
Flush
그렇기 때문에 루씬은 색인 작업이 요청되면 데이터를 일단 인메모리 버퍼에 순서대로 쌓습니다.
그리고 정책에 따라 내부 버퍼에 일정 크기 또는 일정 시간 이상이 되면 버퍼에 쌓인 데이터를 한꺼번에 처리합니다. (일종의 큐처럼 활용)
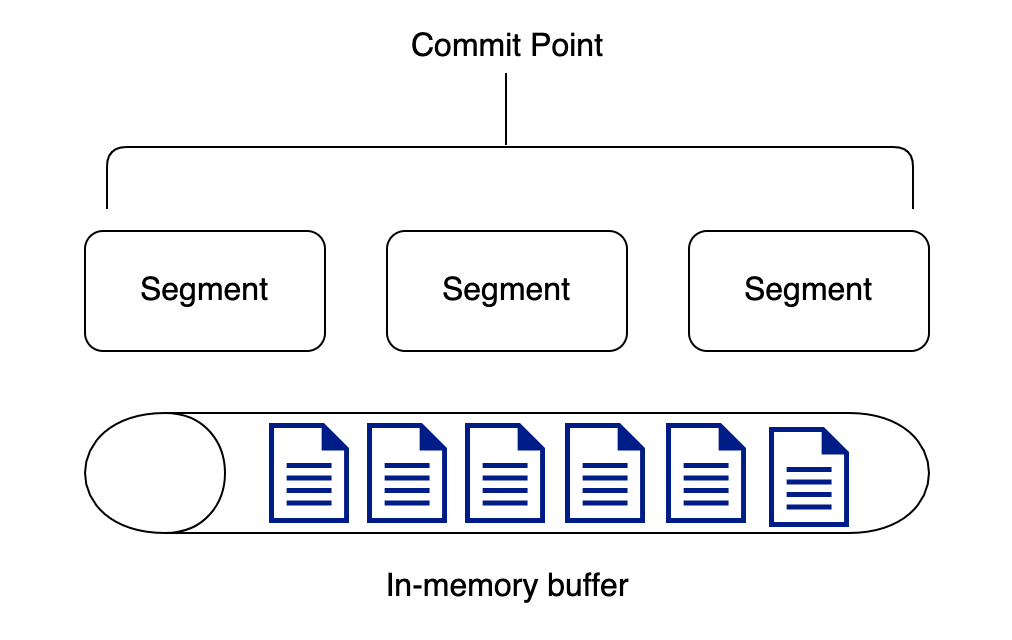
버퍼에 모여 한번에 처리된 데이터는 세그먼트 형태로 생성되고 즉시 디스크로 동기화 됩니다.
(검색이 되는 시점은 세그먼트가 생성되는 순간이 아닌, 디스크에 동기화 되는 순간입니다.)
하지만 물리 디스크에 동기화 하는 과정은 OS 입장에서 매우 비용이 크기 때문에, 만약 세그먼트가 생성될 때 마다 물리적인 동기화를 할 경우 성능이 급격히 나빠질 수 있습니다.
루씬은 이러한 문제점을 해결하기 위해 무거운 fsync 방식이 아닌 write 방식을 이용해 쓰기 과정을 수행합니다.
이러한 방식으로 쓰기 성능을 높이고 이후 일정한 주기에 따라 물리적인 디스크 동기화 작업을 하게 됩니다.
write()? fsync()?
write 함수는 OS 내부 커널 시스템 캐시에 기록하고 리턴되는 쓰기 함수로 실제 물리적 디스크 쓰기는 즉시 수행하지 않기 때문에(특정 주기 마다 수행) 빠른 처리가 가능한 반면 최악의 경우 데이터 유실이 발생할 수 있으며, fsync 함수는 시스템 캐시와 물리적인 디스크의 데이터를 동기화하기 위한 목적으로 사용되는 함수로 실제 물리적인 디스크로 쓰는 작업으로 인해 상대적으로 많은 리소스를 사용함
이러한 인메모리 버퍼 기반의 처리 과정을 루씬에서는 Flush라고 부릅니다.
일단 Flush 처리에 의해 세그먼트가 생성되면 루씬의 ReOpen() 함수를 이용해 IndexSearcher에서도 읽을 수 있는 상태가 됩니다.
이러한 원리에 의해 루씬에서는 상대적으로 저렴한 비용으로 실시간에 가까운 검색이 가능해지는 것 입니다.
여기서 주의해야 할 점은, write 함수를 사용하기 때문에 물리 디스크에 100% 저장됨을 보장받지 못한다는 것인데요. (결국 언젠가는 fsync 함수가 한번 호출되어야 물리 디스크에 동기화 됩니다)
이렇게 커널에게 쓰기 작업을 위임하고 나몰라라 하는게 Elasticsearch 뿐만은 아닌걸로 알고 있습니다.
(카프카의 디스크 영속화도...)
Commit
루씬에서 물리적으로 디스크에 기록을 수행하는 fsync 함수를 호출하는 작업을 Commit 이라고 합니다.
Flush라는 단계가 존재하기 때문에 매번 Commit을 수행할 필요는 없지만 일정 주기마다 한번씩은 Commit을 해줘야 합니다.
세그먼트는 불변성(immutability)을 기반으로 설계되어 다양한 이점이 있지만, 동작 방식은 복잡질 수 밖에 없는 구조가 되었습니다.
루씬에서는 불변성을 유지하기 위해 세그먼트 단위 검색(Per-Segment Search)을 제공하지만 시간이 흐를수록 세그먼트들의 개수가 늘어날 수밖에 없고 이를 지원하기 위해 제공되는 커밋 포인트의 부하도 덩달아 증가하게 됩니다.
Merge
그래서 늘어난 다수의 세그먼트를 하나로 합치는 작업이 필요한데, 이를 Merge 라고 합니다.
Merge작업을 하면 다음과 같은 장점이 있는데요.
첫째, 검색 성능이 좋아진다. (세그먼트 개수가 줄어들어서 검색 횟수도 줄어듬)
둘째, 세그먼트가 차지하는 디스크 용량이 줄어든다. (삭제된 문서가 Merge 작업때 실제 물리디스크에서 삭제됨)
하지만 Merge 작업은 Commit 작업을 반드시 동반해야 하는데 앞서 설명한 바와 같이 Commit 작업이 high-cost 연산이므로 정책적으로 적절한 주기로 설정하는 것이 매우 중요합니다.
(사실 작업 주기는 최적의 성능을 낼 수 있도록 자동으로 설정되며 백그라운드로 수행된다고 합니다)
정리하면,
루씬의 Flush 작업은
- 세그먼트가 생성된 후 검색이 가능해지도록 수행하는 작업이며
- write 함수로 동기화가 수행됐기 때문에 커널 시스템 캐시에만 데이터가 생성되며
- 이를 통해 유저 모드에서 파일을 열어서 사용하는 것이 가능해지며
- 물리적으로 디스크에 쓰여진 상태는 아닙니다.
Commit 작업은
- 커널 시스템 캐시의 내용을 물리적인 디스크로 쓰는 작업이며
- 실제 물리적인 디스크에 데이터가 기록되기 때문에 많은 리소스가 필요한 작업입니다.
Merge 작업은
- 다수의 세그먼트를 하나로 통합하는 작업이며
- Merge 과정을 통해 삭제 처리된 데이터가 실제 물리적으로 삭제 처리되며,
- 검색할 세그먼트의 개수가 줄어들기 때문에 검색 성능이 덩달아 좋아지게 됩니다.
참고자료
엘라스틱서치 실무 가이드 [권택환, 김동우, 김흥래, 박진현, 최용호, 황희정 지음]