<왕> minus <남자> plus <여자>= ?
단어 간의 관계를 학습해 vector에 저장하는 word embedding 이라는 중요한 모델 소개
Distributional Hypothesis (분포가설)
단어는 주변 단어들에 의해 정의된다.
unsupervised learning (비지도학습) -> 따로 시간, 돈 들여 데이터 가공할 필요 없이 그냥 책, 인터넷에 있는 텍스트 그대로만 가지고도 학습 가능
Word Embedding (word vector)란?
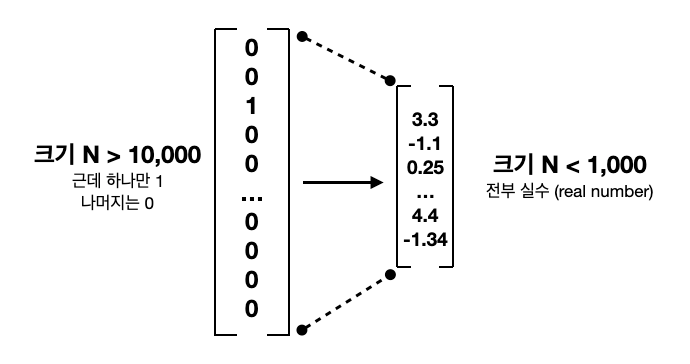
one-hot vectors는 단어를 Nx1 column vector로 표현
다만 데이터 크면 단어 갯수 몇만으로 커질 수 있고
단어 표기하는 1개의 row말고는 0으로 채워져 있기 때문에 아주 비효율적이다.
word2vec과 GloVe는 둘다 하나의 단어를 몇천, 몇만 -> 몇십, 몇백 차원으로 낮추려는 것이 목표다.
embed : 단단하게 박다
더 적은 숫자들로 하나의 단어에 대한 정보를 담으려는 word vector 들은 = embedding 라고도 표현
간단한 counting을 이용한 GloVe
GloVe는 아주 직관적인 방식 택한다.
같은 문장에 한 단어가 어떤 근처 단어들과 몇 번 같이 나오는지 센다.
= co-occurrence matrix
3개의 문장을 가진 corpus
"I enjoy flying"
"I like NLP."
"I like deep learning"
참고) NLP에서 텍스트 데이터 -> corpus (말뭉치) 라고 부른다.
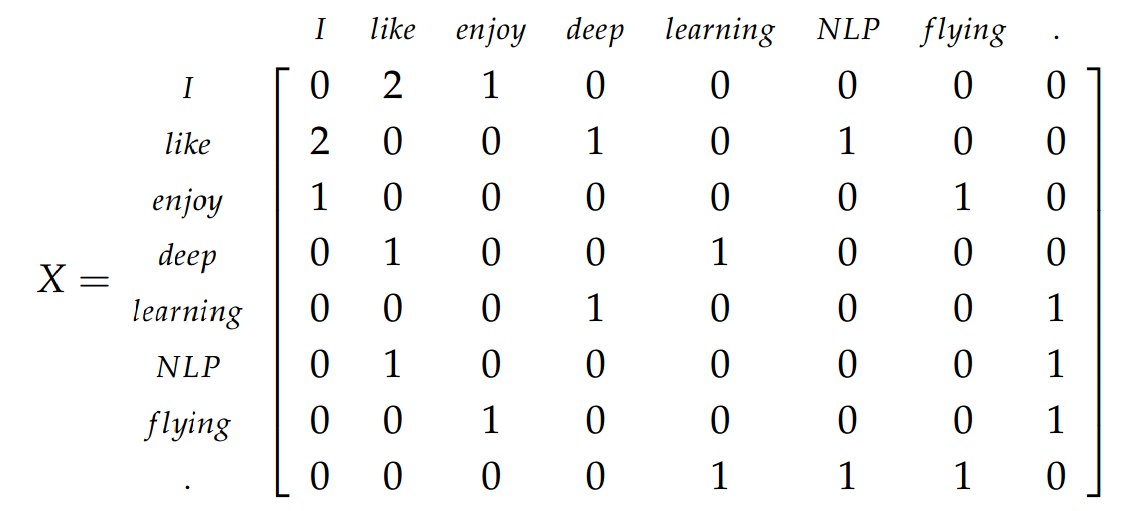
전체 corpus에서 40,000개의 단어가 있다고 가정하고
40,000 x 40,000 매트릭스 만들고 전부 0으로 초기화 시킨다.
위의 방식 대로 빈도수 통계를 하지만
40,000 x 40,000 매트릭스 너무나 크다.
한 번도 나오지 않는 단어 많을 것이기에 0이 꽤나 많은 sparse matrix기도 하다.
비효율 해결하기 위해
dimensionality reduction 기술
차원 줄여주는 알고리즘
예를 들면 40,000 x 40,000 -> 300 x 40,000 압축시킨다.
GloVe는 Singular Value Decomposition (SVD) 알고리즘 사용
자매품으로는 Principle Component Analysis (PCA)가 있다.
이런 Dimensionality reduction 알고리즘들은 NLP 뿐만 아니라 추천 시스템 등
machine learning에서 엄청나게 중요하고 유용하게 쓰이는 기술 중 기술이다.
이렇게 300 x 40,000 압축 되면 각 열이 하나의 단어를 대표한다.
각 단어 dense한 vector로 압축되, 예를 들면 crawling이라는 단어 300개의 숫자로 표현할 수 있게 되는 것이다.
neural network를 이용한 word2vec
word2vec은 continuous bag-of-words (CBOW) 또는 skipgram 알고리즘 통해 학습시킬 수 있다.
(1)CBOW - 주변 단어들 모두 합쳐서 본 후 타깃 단어 맞추기
(2)skipgram - 타깃 단어를 보고 주변 단어 맞추기
CBOW 좀더 직관적이지만 실제로 skipgram으로 학습된 embedding이 실험결과 상 더 효과가 좋다.
예측 위한 classification model은 neural network로 구현이 되고, stochastic gradient desent (SGD)로 학습이 된다.
input은 Nx1 word embedding으로 들어간다. 처음에는 무작위 숫자로 embedding이 초기화되지만, 학습 점점 될수록 word embedding은 주변 단어들과의 관계에 대한 정보가 encoding된다.
Glove와 궁극적으로 같은 word embedding을 다른 방식으로 학습시키는 것이라고
이해하면 된다.
<마드리드> - <스페인> + <프랑스> = <파리>!
word2vec 또는 glove로 학습된 word embedding들은 단어를 N차원에 사는 vector로 바꾸어준 것이다.
그렇기 때문에 서로 더하고 뺄 수 있다. 그리고 이것을 통해 단어들의 의미적 관계와 문법적 관계를 알아낼 수 있다.
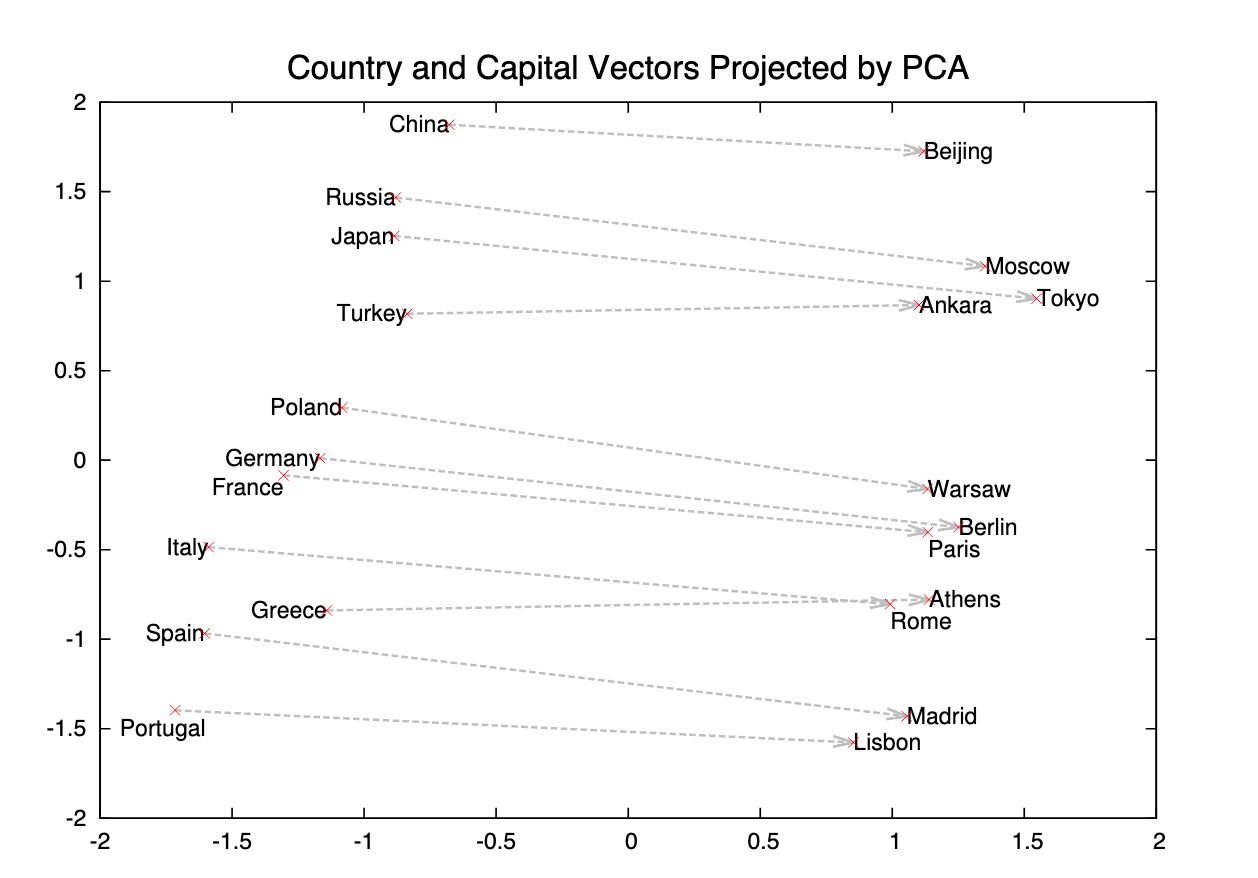
이러한 word embedding들을 다른 NLP task의 input으로 사용할 때,
엄청난 성능 증가 기대할 수 있다.
왜냐면 word embedding은 엄청난 양의 corpus로 학습되어 각 단어에 대한 정보 꽤나 정확하고 싶게 담아낼 수 있다.
