Week 2 - 단어를 가방에 때려 넣으면 문장이 된다
문장을 이해하는데 단어의 순서는 중요하다.
하지만 문장이 어떤 주제를 가지는지만 알고 싶다면 순서는 크게 상관없다.
NLP에서는 해결하고자 하는 문제에 따라 문장을 표현하는 방법이 달라질 수 있다.
Bag-of-words (BoW)
one-hot vector는 단어를 한개의 column vector로 표현한다.
여러 개의 단어의 vector를 단순히 합해서 문장을 표현하는 것
= BoW vector
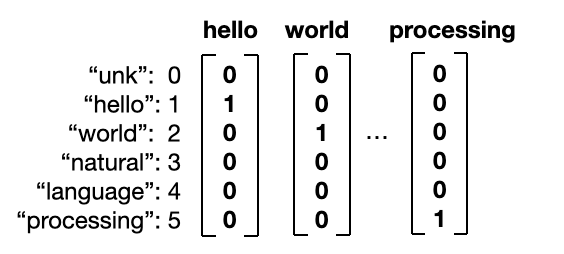
one-hot vectors
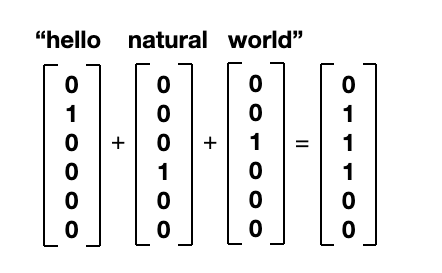
one-hot vector 합쳐 만들어진 BoW vector
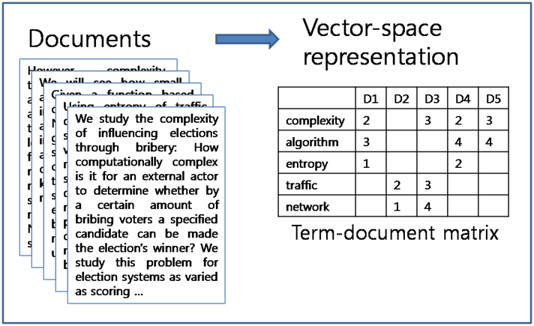
BoW vector는 Nx1 매트릭스에 문장 안에 포함되어 있는 단어가 몇 번 들어가 있는지
빈도수를 표시하는 것이다.
Bow vector는 단어의 순서를 고려하지 않는다.
하나의 vector로 뭉개어서 표현하기 때문이다.
N-gram : 순서 신경써야 하지 않을까?
n-gram은 연속된 n개의 단어 뭉치를 뜻한다.
"I love studying machine learning" bi-gram (n=2)
[I love, love studying, studying machine, machine learning]
총 4개
n=2 n-gram 이용해 BoW 만든다면 학습 데이터 나오는 모든 bi-gram을 vocabulary에 넣어야 한다.
단어수가 많으면 vocabulary도 커지기 때문에 보통 n이 너무 크지 않은 2~3정도만 쓴다.
매우 중요한 개념이다.
Tf-idf vector
term frequency - inverse document frequency (tf-idf)는
단어 간 빈도 수에 따라 중요도를 계산해 고려하는 방법이다.
학습데이터가 크면 자주 쓰이는 단어의 숫자는 커진다.
영어에서 관사, 대명사 자주 나오니만 문장의 주제 파악하는 데 있어서
중요하지 않을 수 있다. (이를 stopword 라고 한다)
반대로 AI, NLP 같은 단어들은 문서의 주제를 유추하는데 아주 중요한 역할을 한다.
term frequency (tf) : 현재 문서서의 단어의 빈도수
document frequency (df) : 이 단어가 나오는 문서 총 개수
관사, 대명사는 tf, df 둘다 높을 것
AI, NLP 단어는 tf는 높을 수 있지만, df가 상대적으로 낮다
tf-idf score는 다음과 같이 정의된다.
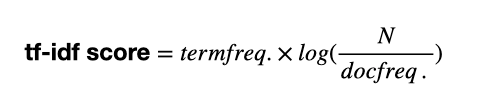
N은 전체 document 개수
기존 BoW에서 문서 내 단어 빈도수를 고려하되,
다른 문서에도 너무 자주 나오는건 중요도를 낮추어 점수를 계산한다.
df는 분모에 등장하기 때문에 inverse document frequency라고 한다.
tf-idf vector는 Nx1 vector 모양의 BoW vector에서 tf 점수를 idf로 normalize 한 것으로 이해하면 된다.
BoW, Tf-idf vector의 단점은 무엇일까?
1) 순서가 중요한 문제에는 쓰기 힘들다
BoW, tf-idf는 간단하지만 topic classification이나 document retrieval 같은 task에는 좋은 성능을 보여준다.
순서가 중요하지 않은 문제에서 강점을 보인다. 그렇기 때문에 순서가 중요한 문제에서는
이러한 정보 생략하기 때문에 성능이 좋지 않다.
예를 들어 machine translation 같이 다른 언어로 문장을 생산해야 하는 문제는 힘들다
2) vocabulary 커지면 커질수록 쓰기 힘들다.
vocabulary size 늘어날수록 커지는 vector의 사이즈는
단어 표현 방식인 one-hot vector로 시작된 고질적 문제
Nx1 column vector로 단어 또는 문장을 표현하기 때문에 vocabulary 크기인 N이 커지면
전체 vector가 엄청나게 커진다.
실상은 대부분의 vector안에 숫자가 0으로 채워져 있음에도 불구하고
(이런 matrix를 sparse matrix 라고 한다.)
3) 단어 간의 관계를 표현하지 못한다.
책상 - 테이블, 의자 - 좌석 같은 동의어들
one-hot vector는 각 단어를 각각의 index로 구별하기에 서로 연관성을 표현할 수 없다.
(one-hot vector 는 서로 orthogonal 하다)
중요
이 단점들을 잘 이해하는게 중요하다
단점들을 극복하기 위해 여러가지가 많이 나온다.
BoW, tf-idf 간단한 모델 사용
