상황
Lovebird 애플리케이션의 다이어리 타임라인 화면에서 조회 시 페이지네이션을 할 필요성을 느꼈다. 작성 날짜(memory_date)를 기준으로 이전 또는 이후의 데이터를 pageSize만큼 조회한다는 요구사항에 따라 커서 페이지네이션을 활용하여 빠르게 개발하였다. 아래는 처음에 개발한 코드이다.
. . .
fun findBeforeNowUsingCursor(param: DiaryListRequestParam): List<DiaryResponseParam> {
return queryFactory
.from(diary)
.innerJoin(user)
.on(eqUserId(user.id))
.innerJoin(diaryImage)
.on(eqDiary(diaryImage.diary))
.where(eqCouple(param.userId, param.partnerId), loeMemoryDate(param.memoryDate))
.orderBy(descMemoryDate(), descCreatedAt())
.limit(param.pageSize)
.transform(
groupBy(diary.id)
.list(
Projections.constructor(
DiaryResponseParam::class.java,
diary.id,
user.id,
diary.title,
diary.memoryDate,
diary.place,
diary.content,
list(
Projections.constructor(
String::class.java,
diaryImage.imageUrl
)
)
)
)
)
}
. . . 팀원과 Pull Request를 통해 코드 리뷰를 진행하다가 index나 scan에 대해서 의구심이 들어서 문제를 제시했다. 따라서, 이를 기반으로 문제 상황과 고려했던 방안에 대해 살펴보자
문제
일반적으로 query 성능을 개선하기 위해 인덱스를 활용하고 있고, Lovebird팀의 다이어리 페이지 조회 또한 인덱스를 생성 및 활용하려 한다. 문제는 타임라인 특성상 memory_date를 기준으로 조회를 해야하는데, 하루에 일기를 여러 개 작성할 수 있으므로, memory 컬럼의 카디널리티는 하루에 작성하는 일기 갯수와 반비례하여 낮아진다. 일반적으로 카디널리티가 낮은 컬럼에 대해서는 인덱스 효율이 떨어지기 때문에 테스트 이전에 두 가지 방안을 세워보았다.
- memory_date에 Index를 건다. (지장이 갈 정도로 하루에 많은 일기를 작성하진 않을 것이라 가정)
- diary_id와 memory_date를 묶어 Multiple Column Index를 건다.
행동1: memory_date에 Index를 건다.
CREATE INDEX idx_memory_date
ON diary (memory_date);위와 같이 인덱스를 생성해 봤지만, 전혀 인덱스를 타지 않는 쿼리가 계속 발생했다. 그 이유는 postgreSQL에서는 table의 데이터 존재 유무도 함께 고려해서 실행 계획을 만들기 때문이었다. 따라서 Dummy Data를 생성해보았다.
-- users
INSERT INTO users(user_id, device_token, provider, provider_id, role)
VALUES (1, 'sdfsdf', 'NAVER', 1, 'ROLE_USER');
-- diary
INSERT INTO diary
(diary_id, content, title, place, user_id, memory_date)
SELECT n, 'content ' || n as content, 'title ' || n as title, 'place ' || n as place, 1, '2023-12-15'
FROM generate_series(1, 1000000) as n;
-- diary_image
INSERT INTO diary_image
(diary_image_id, diary_id, image_url)
SELECT n, n, 'imageUrl ' || n as image_url
FROM generate_series(1, 1000000) as n;Dummy Data를 삽입한 후의 Query Plan은 다음과 같다.

Execution Time(16226.902 ms)
행동2:인덱스를 부여하지 않고, PK(diary_id)를 활용한다.
SELECT d.diary_id, d.user_id, d.title, d.place, d.content, di.image_url
FROM diary d
INNER JOIN diary_image di
ON d.diary_id = di.diary_id
WHERE (d.memory_date <= '2023.12.15' and d.diary_id <= 10) and (d.user_id = 1 or d.user_id = 2)
ORDER BY d.memory_date desc, d.created_at desc
LIMIT 10;
diary_image에서는 Parallel 하게 Full Scan을 하지만, Diary를 가져올 때는 Index Condition이 걸려서 Index Scan을 하는 것을 확인할 수 있다. 따라서 행동 3을 채택하기로 하였고, 추가적으로 diary_image에 대한 인덱스로 살펴보도록 하겠다.
→ Execution Time (138.383 ms)
행동3:diary_id와 memory_date를 묶어 Multiple Column Index를 건다.
CREATE INDEX multiple_column_index
ON diary (diary_id, memory_date);위와 같이 인덱스를 생성한 후의 Query Plan은 다음과 같다.
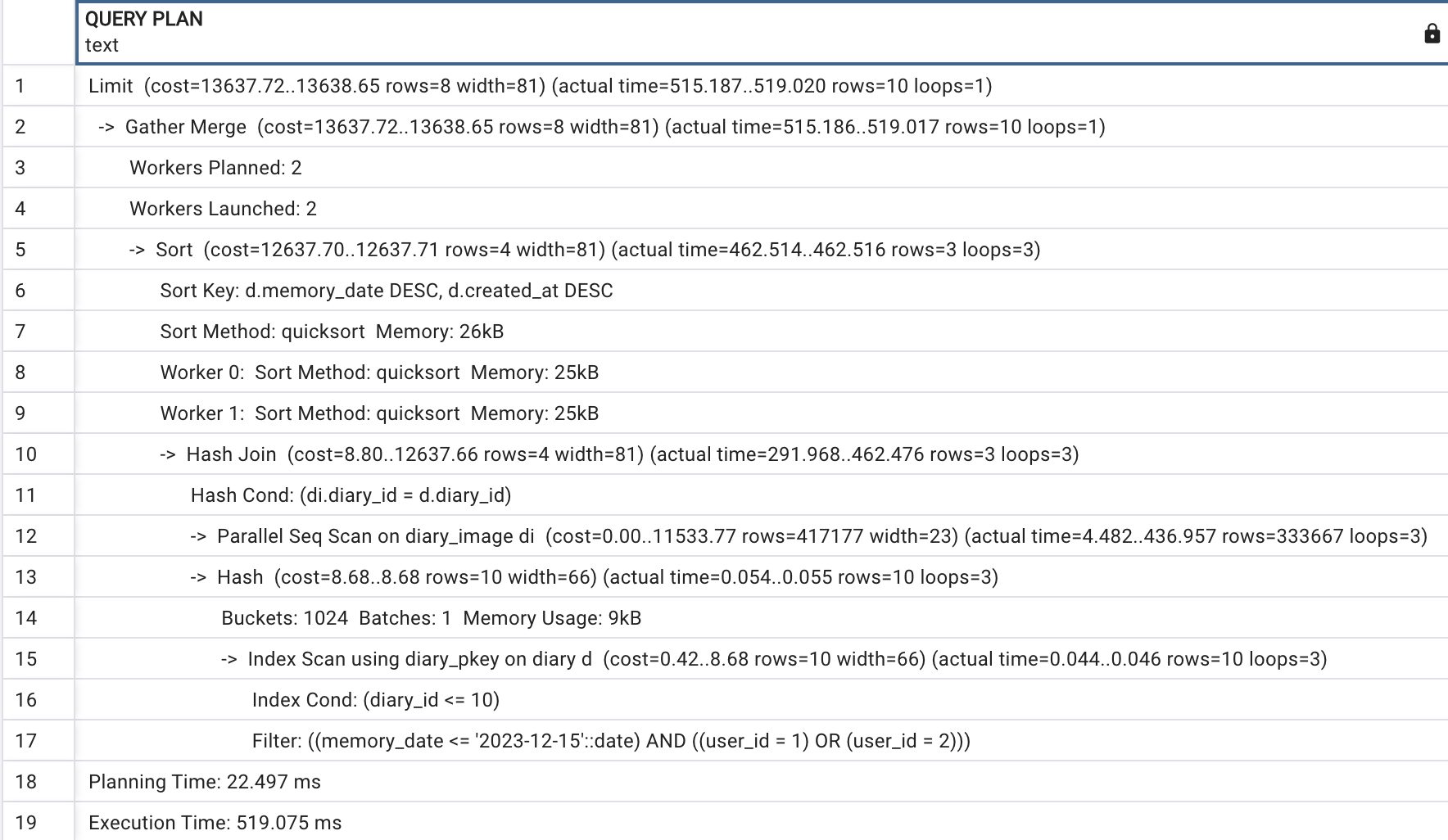
실행 시간은 커졌지만, 이는 memory_date의 다양화를 위해 Query 실행 이전에 데이터를 더 추가했기 때문에 크게 고려할 사항은 아니라고 생각 들었다. 이 Query Plan에서 포인트는 Index Scan에서 diary_id와 memory_date를 이용한 multiple column index를 활용하지 않는다는 점이다.
추가:diary_image에는 왜 Index가 없을까?
사실 diary_image의 Foreign Key인 diary_id에 Index가 있는줄 았았다. 하지만 테스트 과정에서 확인한 결과, 없음을 확인했고, postgreSQL에서는 Foreign Key에 대한 Index를 자동 생성해주지 않는다는 것을 알게 되었다.
CREATE INDEX idx_fk_diary_image_diary_id
ON diary_image(diary_id);위와 같은 인덱스를 생성한 후 실행했을 때의 Query Plan은 다음과 같다.

Execution Time이 대폭 줄어든 것을 확인할 수 있었다. 이를 통해 초기의 Seq Scan Seq Scan에서 Index Scan Index Scan으로 성능을 향상 시킬 수 있었다.
실제 코드
@Entity
@Table(
name = "diary_image",
indexes = [
Index(name = "idx_fk_diary_image_diary_id", columnList = "diary_id")
]
)
class DiaryImage(
diary: Diary,
imageUrl: String
) {
. . .PK를 활용한 쿼리 구현
. . .
fun findAfterNowUsingCursor(param: DiaryListRequestParam): List<DiaryResponseParam> {
return queryFactory
.from(diary)
.innerJoin(user)
.on(eqUserId(user.id))
.where(
eqCouple(param.userId, param.partnerId),
eqMemoryDateAndGtDiaryId(param.memoryDate, param.diaryId),
gtMemoryDate(param.memoryDate)
)
.orderBy(ascMemoryDate(), ascDiaryId())
.limit(param.pageSize)
.transform(
groupBy(diary.id)
.list(
Projections.constructor(
DiaryResponseParam::class.java,
diary.id,
user.id,
diary.title,
diary.memoryDate,
diary.place,
diary.content,
list(
Projections.constructor(
String::class.java,
diaryImage.imageUrl
)
)
)
)
)
}
private fun eqCouple(userId: Long, partnerId: Long?): BooleanExpression {
val expression: BooleanExpression = eqUserId(userId)
return if (partnerId != null) {
expression.or(eqUserId(partnerId))
} else {
expression
}
}
private fun eqMemoryDateAndGtDiaryId(memoryDate: LocalDate, diaryId: Long): BooleanExpression {
return gtDiaryId(diaryId).and(eqMemoryDate(memoryDate))
}
private fun eqMemoryDate(memoryDate: LocalDate): BooleanExpression = diary.memoryDate.eq(memoryDate)
private fun gtDiaryId(diaryId: Long): BooleanExpression = diary.id.gt(diaryId)
private fun gtMemoryDate(memoryDate: LocalDate): BooleanExpression = diary.memoryDate.gt(memoryDate)
. . .다음과 같은 로직으로 PK와 memory_date를 활용한 쿼리를 작성했다.
- 처음 조회 시 (=오늘 날짜 조회)
- 요청
diaryId : 0 or -1
memoryDate : 오늘 날짜
- 요청
- 조회 데이터
- 요청 받은 날짜와 동일하고, 요청 받은 아이디보다 큰 아이디를 가진 데이터(eqMemoryDateAndGtDiaryId)
- 요청 받은 날짜 이후, 혹은 이전의 데이터 (ltMemoryDate or gtMemoryDate)- 데이터 갯수 : pageSize
- 처음 이후의 조회 시
요청
- diaryId : 이전 조회에서 응답으로 받은 diaryId
- memoryDate : 이전 조회에서 응답으로 받은 memoryDate
조회 데이터
- 요청 받은 날짜와 동일하고, 요청 받은 아이디보다 큰 아이디를 가진 데이터 (eqMemoryDateAndGtDiaryId)
- 요청 받은 날짜 이후, 혹은 이전의 데이터 (ltMemoryDate or gtMemoryDate)
- 데이터 갯수 : pageSize
