
Database
Data?
데이터는 우리가 흔히 접하는 이미지나 날씨처럼 수, 단어, 이미지, 영상 등의 형태를 가진 단위이다.
Database?
- 데이터베이스(이하 DB)란, 컴퓨터의 시스템에 저장된 모든 정보나 데이터를 모아 놓은 집합이다.
- 쉽게 말해, 말 그대로 데이터의 베이스(근거지, 기지)이다.
Client & Server & Database 간 소통 관계
Client에서 요청을 하면 Server도 Database에 요청을 하고,
다시 Sever에 응답 이후 Client에 응답하는 구조이다.
(상세 정보 요청) → (필요 정보 요청) → |
(필요 정보 응답) ← (필요 정보 응답) ← |
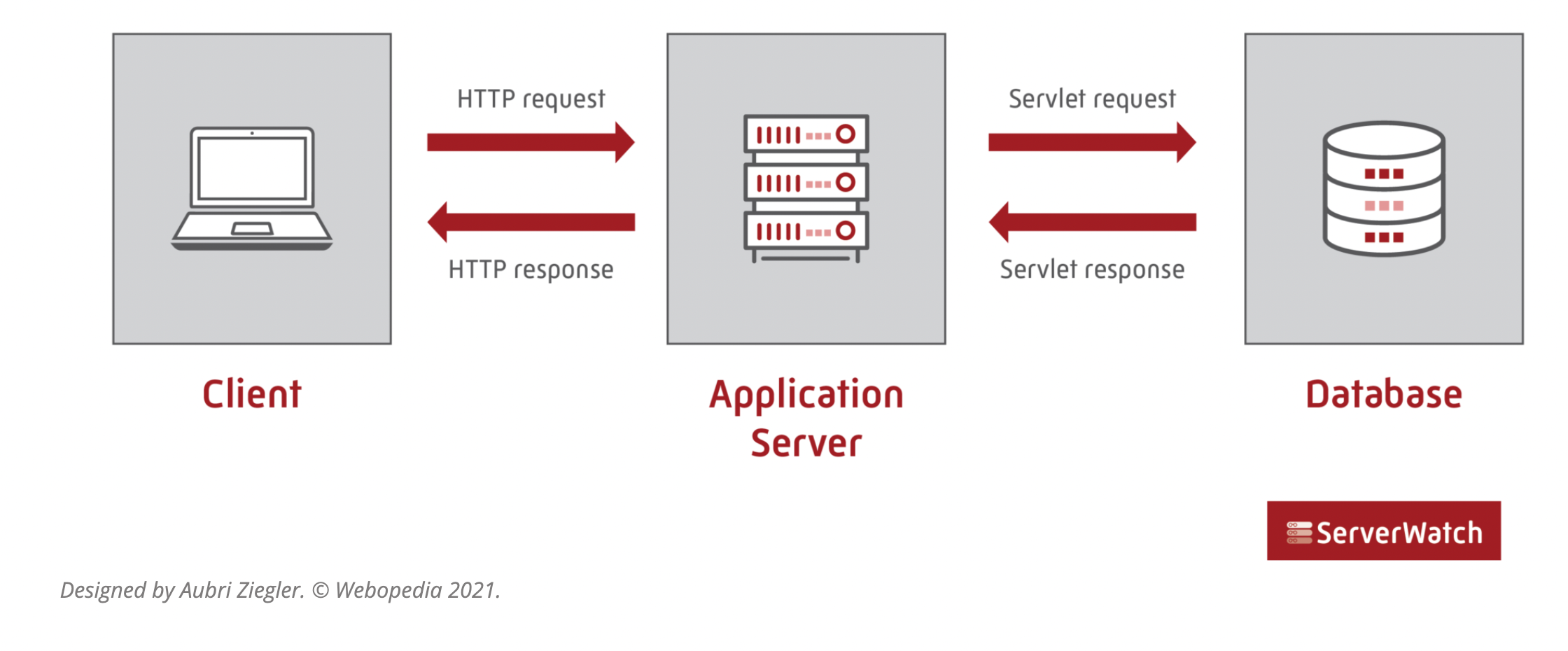 (출처: ServerWatch)
(출처: ServerWatch)
DB를 사용하는 이유?
- 데이터를 제대로 저장하고 보존하기 위해
- ⭐️(더 큰 이유) 고증된 데이터를 체계적으로 관리하기 위해(체계전 보존 및 관리)
관계형 데이터베이스(RDBMS)
그렇다면 데이터를 단순히 저장하면 의미가 있을까?
데이터 간에 관계를 가져야 의미가 있을 것이다.
관계형 데이터베이스 (RDBMS, Relational DataBase Management System, 이하 RDBMS)는 이름 그대로 데이터 사이의 관계에 기초를 둔 데이터베이스 시스템을 말한다. 여기서 관계란, 아래와 같은 표들 사이의 관계를 뜻한다
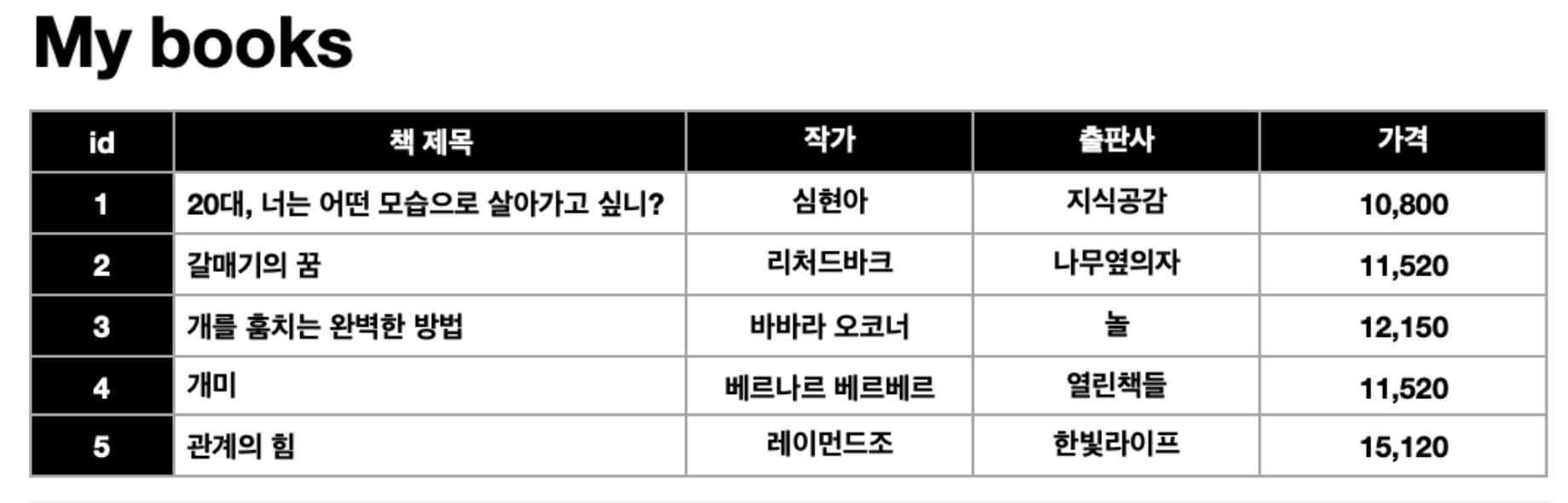 (테이블 예시)
(테이블 예시)
테이블(table)?
모든 데이터는 2차원 테이블로 표현할 수 있다. 위의 그림을 다시 보면,
- column(열): 테이블의 각 항목(
id,책 제목,작가,출판사,가격) - row(행): 각 항목의 실제 값(
개미,베르나르 베르베르,열린책들,11,520)
고유 키(Primary Key)
각 row가 가진 고유한 번호.
테이블 관계의 종류
RDBMS 내부에 테이블 A와 테이블 B가 있다고 가정해 보자,
두 테이블은 아래의 3가지 관계 중 하나에 해당한다.
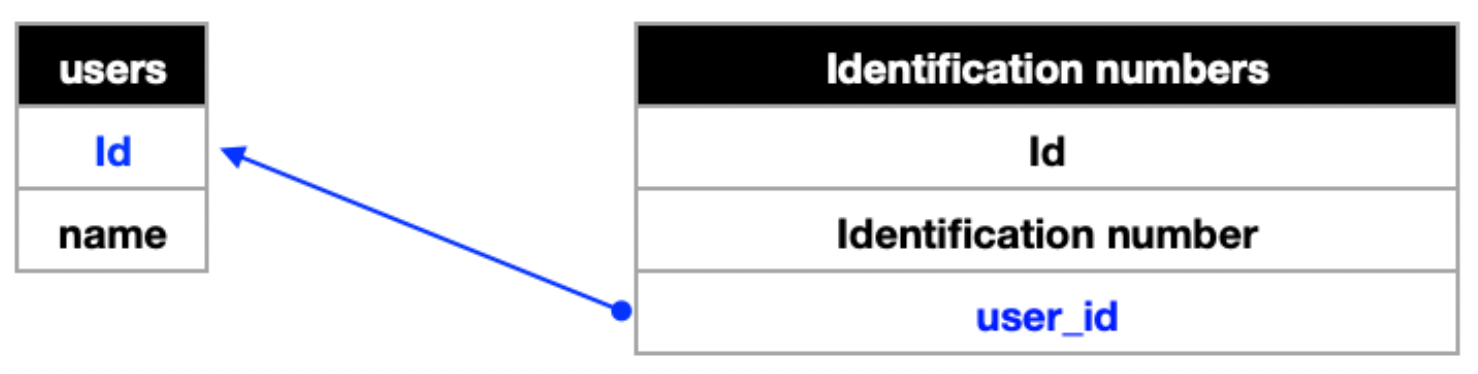
a. 일대일(one to one)

단일의 A 데이터는 단일의 B 데이터와 연결되고, 반대도 마찬가지이다.
ex) 국민 - 주민번호
+ 참조 (reference)와 외부키(foreign key)
일대일 관계인 테이블끼리 아래와 같이 합쳐도 문제가 없을 것이다.
하지만, 불필요하게 같은 이름을 중복해서 여러 번 저장하여 낭비하게 된다. 따라서 users에 직접 저장하지 않고, user_id를 저장해 실제 users의 id를 가리키도록 만들어 효율적으로 관리하게 된다. 이를 참조한다고 하며, user_id는 Identification number의 외부키이다.
b. 일대다(one to many)
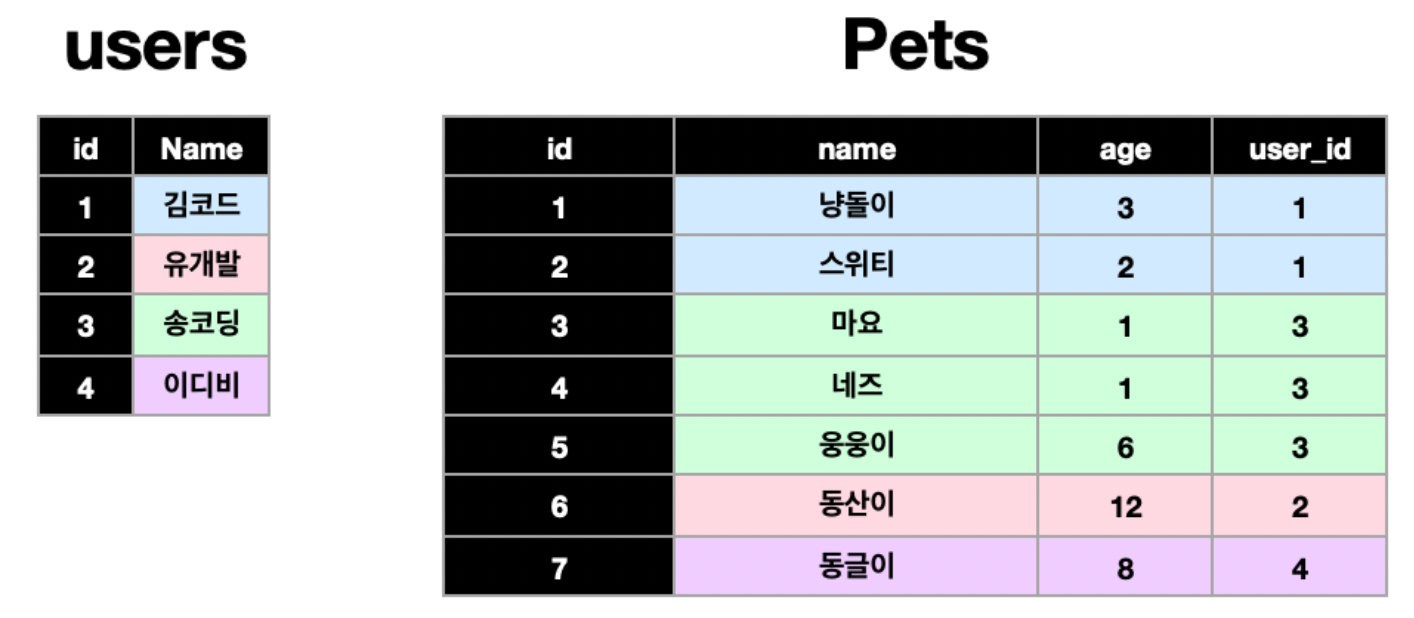 단일의 A 데이터는 여러 데이터 B를 가질 수 있지만, 반대는 성립하지 못한다.
단일의 A 데이터는 여러 데이터 B를 가질 수 있지만, 반대는 성립하지 못한다.
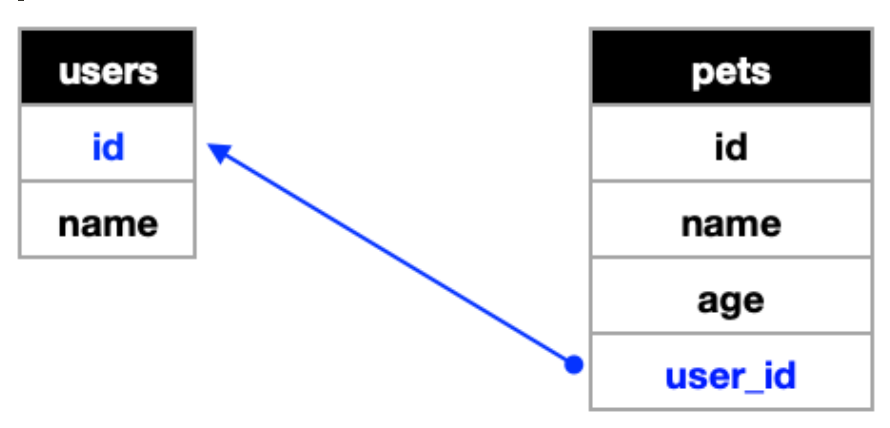
pets의 테이블은 user의 id를 참조하여 일대다의 관계를 맺고 있다.
ex) 주인 - 반려동물
c. 다대다(many to many)
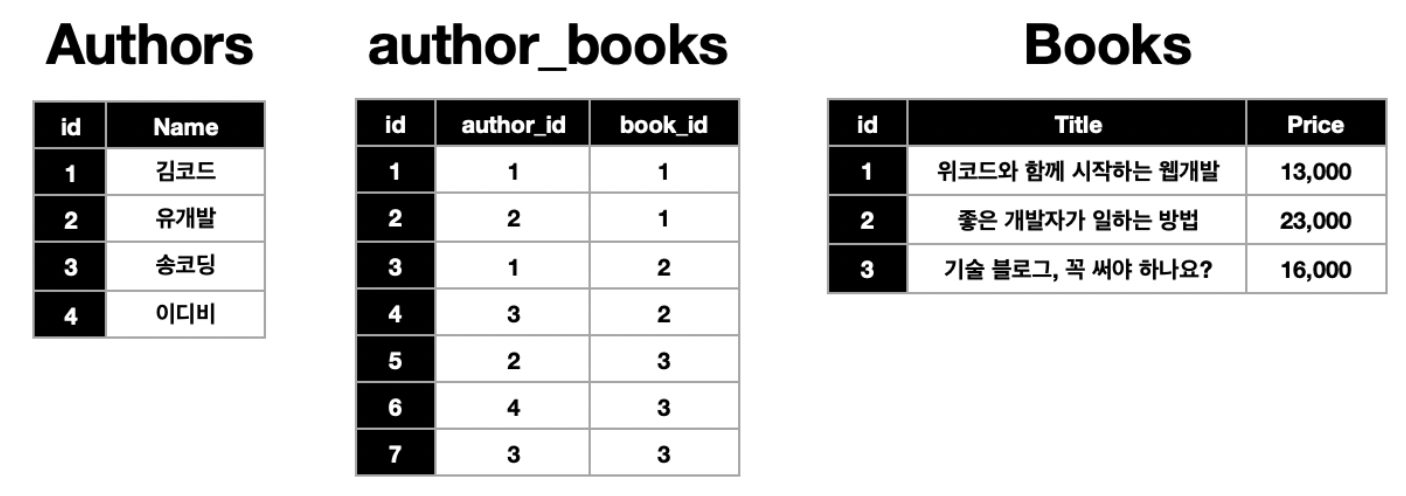 여러 데이터 A는 여러 데이터 B를 가질 수도 있고, 반대도 성립한다.
여러 데이터 A는 여러 데이터 B를 가질 수도 있고, 반대도 성립한다.
 위와 같이
위와 같이 중간 테이블을 통하여 여러 데이터가 상호 연결 된다. 중간 테이블이 두 테이블을 참조하기에 다대다 관계를 맺을 수 있다.
ex) 작가 - 책 or 영화 - 영화 배우
테이블을 연결하는 원리?
외부키(foreign key)라는 개념을 이용해 연결한다
테이블을 연결하는 이유? 그리고 정규화
- 하나의 테이블에 모든 데이터를 다 넣으면 불필요하게 내용이 중복되어 저장된다.
- 더 많은 용량을 필요로 하고, 데이터가 의도치 않게 잘못 저장될 수 있다.
- 부분적으로만 내용이 다른 데이터가 생기는 문제가 없어진다.
- 이러한 과정을
정규화라고 부른다.
과제
스타벅스 서비스 모델링
한국 스타벅스 사이트를 기준으로 아래와 같은 필수 구현 사항을 모델링 할 것
- 필수 구현 사항 :
음료,카테고리,영양 정보,알러지,음료 이미지,음료 설명,신상 여부 - 구현 제외 사항 :
프로모션,음료 사이즈
나를 포함 팀원들 모두 데이터베이스라는 개념 자체를 처음 접하는 거라 애를 많이 먹었다.
서로 설명하고 멘토님한테 지속적인 질문과 피드백으로 과제를 수정 및 보완하였다.
접근 방식
- 필수 구현 사항을 영문으로 변경
음료,카테고리,영양 정보,알러지,음료 이미지,음료 설명,신상 여부drinks,categoryingredients,allergies,drinks_img,drinks_contents,new
- 결국
drinks가 가장 중심적인 관계를 갖고 있어서 이것을 기준으로 잡았다. drinks기준, 다른 구현 사항들이 일대일/일대다/다대다 관계를 맺는지 판별- 일대일:
categoryingredients,drinks_img,drinks_contents,new - 다대다:
allergies
- 일대일:
⭐️ 헷갈린 점: 왜 'allergies'는 다대다(many to many)인가?
예를 들어 알러지를 '우유', '대두'로 들어 보자.
우유/대두가 음료에 들어갈 수도 있고, 음료 또한 우유/대두가 들어간 음료, 아닌 음료로 구분할 수 있다.
따라서 다대다의 관계가 성립한다.
완료 팀 과제
drinks를 기준으로 하여 모델링을 만들어 보았다.

but 수정 사항
내용 보완
다른 동기 분들한테 위의 모델링 그림을 설명을 해 보니 어색한 부분이 몇몇 있었다.
1. underline이 들어가는 단어 대폭 수정
(이유) 중간 테이블과 혼동을 줄 수 있다.
(결론)drinks_로 시작하는 단어를 drinks_allergies만 두고 앞 글자를 삭제하였다.
new의drinks를 참조할 수 있도록 변경ingredients의data는 필요가 없어서 삭제
시각적인 보완
한눈에 알아보기 쉽도록 배치도 변경하였다.
drinks를 기준으로,
- 좌측 상단은
drinks가 참조하는 대상(category) - 우측 하단은
drinks를 참조하고 일대일인 대상(contents,img,new,ingredients) - 우측 상단은
drinks를 참조하되, 다대다인 대상(allergies)
내가 수정한 데이터 모델링

참고 자료
(ServerWatch) Web Server vs. Application Server
(생활코딩) 참조(reference)
(아무튼 워라밸) 정규화(Normalization) 쉽게 이해하기
스타벅스 메뉴 홈페이지
