예외 처리(Exception Handling)
- 에러에 대응할 수 있는 코드를 사전에 작성하여 프로그램의 비정상적 종료를 방지하고, 정상적인 실행 상태를 유지할 수 있다
- 에러가 발생하는 이유는?
- 사용자의 입력 오류
- 네트워크 연결 끊김
- 디스크 메모리 공간 부족 등의 물리적 한계
- 개발자의 코드 에러
- 존재하지(유효하지) 않는 파일 불러오기
- 위 원인들을 크게 내부적인 요인 / 외부적인 요인으로 구분할 수 있다
- 대표적 외부 요인
- 하드웨어의 문제, 네트워크 연결 끊김, 사용자 조작 오류
- 대표적 내부 요인
프로그래밍 시에 발생하기 쉬운 에러들
- FileNotFoundException
- 실제로 존재하지 않는 파일을 불러오려 시도할 때 발생하는 에러
public class Test {
public static void main(String[] args) {
BufferedReader file = new BufferedReader(new FileReader("파일"));
file.readLine();
file.close();
}
}
- ArrayIndexOutOfBoundsException
- 배열의 범위를 벗어난 값을 불러오고자 시도할 때 발생하는 에러
public class Test {
public static void main(String[] args) {
int[] arr = {1, 2, 3, 4, 5};
System.out.println(arr[10]);
}
}
- 위 두 코드를 작성해보면 FileNotFoundsException은 IDE가 에러가 발생했음을 알려주고 있지만 ArrayIndexOutOfBoundsException은 경고 없이 실행한 시점에 도달해서야 에러가 발생한다
- 자바에서는 발생 시점에 따라 에러를 컴파일 에러(Compile Time Error) / 런타임 에러(Run Time Error)로 구분하고 있다
- 코드에 논리적인 오류가 있을 경우 발생하는 논리적 에러(Logical Error)도 존재
컴파일 에러와 런타임 에러
컴파일 에러
- 컴파일 할 때 발생하는 에러
- 문법적인 문제를 가리키는 신택스 오류로부터 발생하기 때문에 신택스 에러라고 부르기도 한다
- 컴파일 에러는 컴파일러가 오류를 감지하여, 사용자에게 알려주므로 상대적으로 발견하고 수정하기 쉽다
런타임 에러
- 코드를 실행하는 과정, 즉 런타임 시에 발생하는 에러
- Ex. ArithmeticException
- 프로그램이 실행될 때에 JVM에 의해 감지된다
에러와 예외
- 코드 실행 시에 잠재적으로 발생할 수 있는 프로그램 오류를 크게 에러(error)와 예외(exception)로 구분할 수 있다
- 에러
- 한 번 발생하면 복구하기 어려운 수준의 심각한 오류
- Ex. OutOfMemoryError, StackOverflowError
- 예외
- 잘못된 사용 혹은 코딩으로 인한 상대적으로 미약한 수준의 오류
- 코드 수정 등을 통해 수습이 가능
예외 클래스의 상속 계층도
- 예외가 발생하면 예외 클래스로부터 객체를 생성하여 해당 인스턴스를 통해 예외 처리를 진행한다
- 에러와 예외 클래스는 Throwable 클래스로부터 확장되고, 모든 예외의 최고 상위 클래스는 Exception 클래스이다
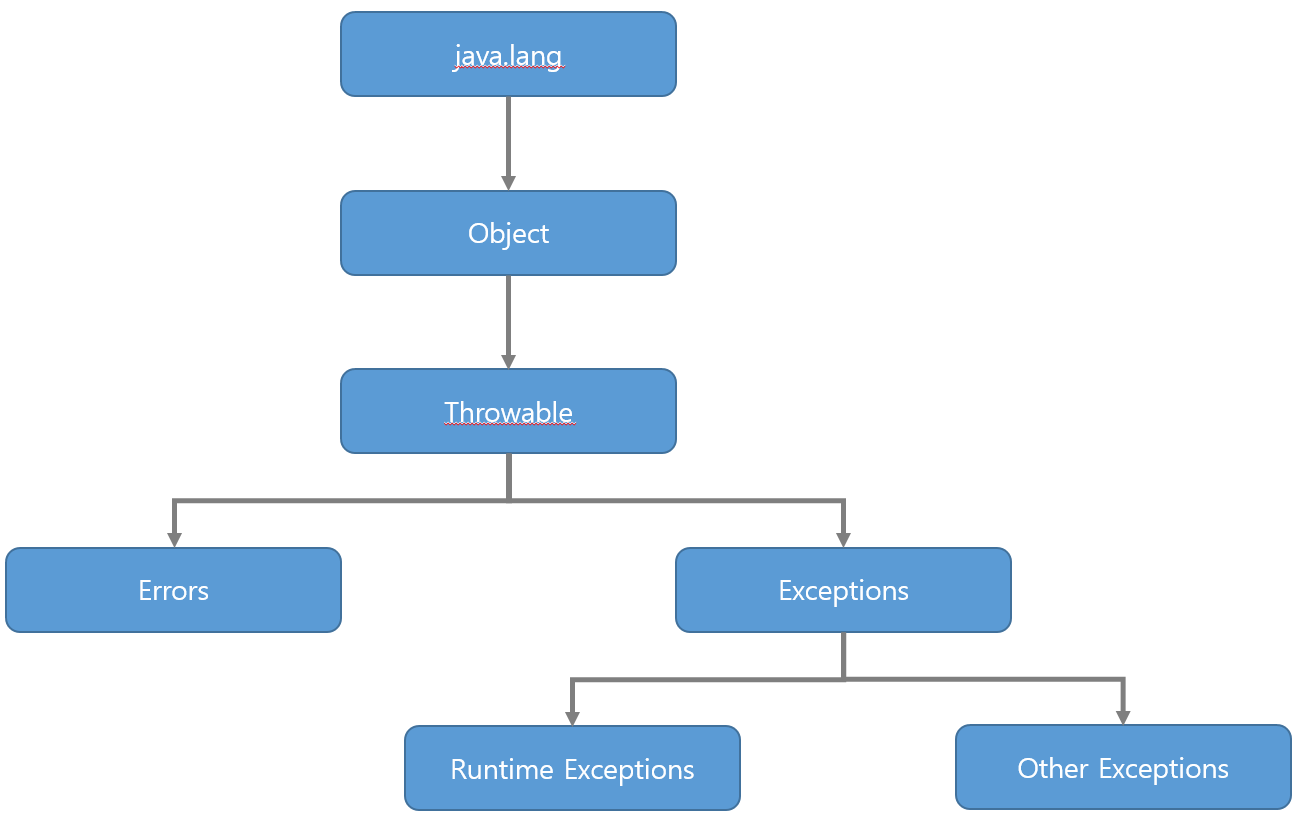
- 모든 예외의 최고 상위 클래스인 Exception 클래스는 일반 예외 클래스 / 실행 예외 클래스로 나눌 수 있다
일반 예외 클래스(Exception)
- 런타임 시에 발생하는 RuntimeException 클래스 및 그 하위 클래스를 제외한 모든 Exception 클래스 및 그 하위 클래스
- 컴파일러가 코드 실행 전에 예외 처리 코드 여부를 검사한다고 하여 checked 예외라고 부르기도 한다
- 주로 사용자 편의 실수로 발생하는 경우가 많다
- Ex. 잘못된 클래스명(ClassNotFoundException), 데이터 형식(DataFormatException)
실행 예외 클래스(Runtime Exception)
- RuntimeException 클래스 및 그 하위 클래스
- 컴파일러가 예외 처리 코드 여부를 검사하지 않는다는 의미에서 unchecked 예외라고 부르기도 한다
- 개발자의 실수에 의해 발생하는 경우가 많다(자바 문법 요소와 관련이 있다)
- Ex. 클래스 간 형변환 오류(ClassCastException), 벗어난 배열 범위 지정(ArrayIndexOutOfBoundsException), 값이 null인 참조변수 사용(NullPointerException)
try-catch문
- 예외 처리
- 잠재적으로 발생할 수 있는 비정상적 종료나 오류에 대비해 정상 실행을 유지할 수 있도록 처리하는 코드 작성 과정
- try-catch 블럭을 통해 구현이 가능하다
try {
}
catch(Exception1 e1) {
}
catch(Exception2 e2) {
}
finally {
}
- try 블럭
- 예외가 발생할 수 있는 코드를 삽입
- 만약 작성한 코드들이 예외 없이 정상적으로 모두 실행된다면 catch 블럭은 실행되지 않고 finally 블럭이 실행된다
- catch 블럭
- 예외가 발생하는 경우에 실행되는 코드
- 여러 종류의 예외에 대해 처리할 수 있다
- 모든 예외를 받을 수 있는 Exception 클래스 하나로 처리도 가능하고 각기 다른 종류의 예외를 하나 이상의 catch 블럭을 이용하여 처리할 수 있다
- 만약 catch 블럭이 여러 개라면, 위에서부터 일치하는 예외를 찾고 해당 catch 블럭만 실행되고 예외처리 코드가 종료되거나 finally 블럭으로 넘어간다
- 일치하는 블럭을 찾지 못했다면 예외는 처리되지 못한다
- catch문에서 예외를 검사할 때, instanceOf 연산자를 통해 생성된 예외 클래스의 인스턴스가 조건과 일치하는지 판단한다
- catch 블럭은 위에서부터 순차적으로 검사가 진행되므로 구체적인 예외 클래스인 하위 클래스를 먼저 위에 배치하여 상위 클래스가 먼저 실행되지 않도록 방지하는 것이 좋다!
- finally 블럭
- 옵션 사항(필수적인 작성이 요구되지 않음)
- 포함하는 경우에는 예외 발생 여부와 상관없이 항상 실행된다
예외 전가
반환타입 메서드명(매개변수) throws 예외클래스1, 예외클래스2, ... {
}
public class Example {
public static void main(String[] args) {
try {
throwException();
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
static void throwException() throws ClassNotFoundException {
Class.forName("java.lang.NoClass");
}
}
- 메서드 선언부 끝에 throws 키워드와 발생할 수 있는 예외들을 나열한다
- 모든 예외 클래스의 상위 클래스인 Exception을 작성하면 모든 예외들을 넘길 수 있다
- main 메서드에서도 throws 키워드를 사용하여 예외를 넘길 수 있는데, 이 때는 JVM이 최종적으로 예외 내용을 콘솔에 출력하여 예외처리를 수행한다
예외를 의도적으로 발생
- throw 키워드를 통해 의도적으로 예외를 발생시킬 수 있다
public class Example {
public static void main(String[] args) {
try {
Exception exception = new Exception("예외를 의도적으로 발생시키기");
throw exception;
} catch(Exception e) {
System.out.println("의도적으로 던진 예외를 처리");
}
}
}
컬렉션 프레임워크(Collection Framework)
- 데이터를 저장하기 위해 널리 알려진 자료 구조를 바탕으로 객체들을 효율적으로 추가, 삭제, 검색할 수 있도록 컬렉션을 생성하고, 관련된 인터페이스와 클래스를 포함시켜 두었는데 이를 총칭하는 용어
- 컬렉션
- 여러 데이터의 집합
- 여러 데이터들을 그룹으로 묶어놓은 것
- 컬렉션 프레임워크
- 컬렉션을 다루는 데 있어 편리한 메서드들을 미리 정의해놓은 것
- 특정 자료 구조에 데이터를 추가/삭제/수정/검색하는 등의 동작을 수행하는 편리한 메서드를 제공한다
컬렉션 프레임워크의 구조
- 컬렉션 프레임워크는 주요 인터페이스로 List, Set, Map을 제공한다
List
- 데이터의 순서가 유지되고, 중복 저장이 가능한 컬렉션을 구현하는 데에 사용한다
- Ex. ArrayList, Vector, Stack, LinkedList
Set
- 데이터의 순서가 유지되지 않고, 중복 저장이 불가한 컬렉션을 구현하는 데에 사용한다
- Ex. HashSet, TreeSet
Map
- 키(key) 및 값(value)의 쌍으로 데이터를 저장하는 컬렉션을 구현하는 데에 사용한다
- 데이터의 순서가 유지되지 않는다
- 키는 값을 식별하기 위해 사용되므로 중복 저장이 불가하다
- 값은 중복 저장이 가능하다
- Ex. HashMap, Hashtable, TreeMap, Properties 등
- List, Set은 공통점이 많으므로 Collection이라는 인터페이스로 묶인다
- List, Set의 공통점이 추출되어 추상화된 것이 Collection 인터페이스
Collection 인터페이스
| 기능 | 리턴 타입 | 메서드 | 설명 |
|---|
| 객체 추가 | boolean | add(Object o) / addAll(Collection c) | 주어진 객체 및 컬렉션의 객체들을 컬렉션에 추가한다 |
| 객체 검색 | boolean | contains(Object o) / containsAll(Collection c) | 주어진 객체 및 컬렉션이 저장되어있는지 여부를 반환한다 |
| iterator | iterator() | 컬렉션의 iterator를 반환한다 |
| boolean | equals(Object o) | 컬렉션이 동일한지 여부를 확인한다 |
| boolean | isEmpty() | 컬렉션이 비어있는지 여부를 확인한다 |
| int | size()) | 저장되어 있는 전체 객체 수를 반환한다 |
| 객체 삭제 | void | clear() | 컬렉션에 저장된 모든 객체를 삭제한다 |
| boolean | remove(Object o) / removeAll(Collection c) | 주어진 객체 및 컬렉션을 삭제하고 성공 여부를 반환한다 |
| boolean | retainAll(Collection c) | 주어진 컬렉션을 제외한 모든 객체를 컬렉션에서 삭제하고, 컬렉션에 변화가 있는지 여부를 반환한다 |
| 객체 반환 | Object[] | toArray() | 컬렉션에 저장된 객체를 객체 배열(Object[])로 반환한다 |
| Object[] | toArray(Object[] a) | 주어진 배열에 컬렉션의 객체를 저장해서 반환한다 |
List
List
-
List 인터페이스는 배열과 같이 객체를 일렬로 늘어놓은 구조
-
객체를 인덱스를 통해 관리하기 떄문에 객체를 저장하면 자동으로 인덱스가 부여되고, 인덱스로 객체를 검색/추가/삭제하는 등의 여러 기능을 제공한다
-
List 인터페이스에서 공통적으로 사용 가능한 메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
|---|
| 객체 추가 | void | add(int index, Object element) | 주어진 인덱스에 객체를 추가한다 |
| boolean | addAll(int index, Collection c) | 주어진 인덱스에 컬렉션을 추가한다 |
| Object | set(int index, Object element) | 주어진 위치에 객체를 저장한다(대체) |
| 객체 검색 | Object | get(int index) | 주어진 인덱스에 저장된 객체를 반환한다 |
| int | indexOf(Object o) / lastIndexOf(Object o) | 순방향 / 역방향으로 탐색하여 주어진 객체의 위치를 반환한다 |
| ListIterator | listIterator() / listIterator(int index) | List의 객체를 탐색할 수 있는 ListIterator를 반환 / 주어진 index로부터 탐색할 수 있는 ListIterator를 반환한다 |
| List | subList(int fromIndex, int toIndex) | fromIndex부터 toIndex에 있는 객체를 반환한다 |
| 객체 삭제 | Object | remove(int index) | 주어진 인덱스에 저장된 객체를 삭제하고 삭제된 객체를 반환한다 |
| boolean | remove(Object o) | 주어진 객체를 삭제한다 |
| 객체 정렬 | void | sort(Comparator c) | 주어진 비교자(comparator)로 List를 정렬한다 |
ArrayList
- List 인터페이스를 구현한 클래스
- ArrayList vs 배열
- 공통점 : 객체가 인덱스로 관리된다
- 차이점
- 배열 : 생성될 때 크기가 고정되고 크기를 변경할 수 없다
- ArraryList : 저장 용량이 초과되면 저장용량이 자동으로 늘어난다
- List 계열 자료구조의 특성을 이어받아 데이터가 연속적으로 존재한다
- ArrayList 생성
- 객체 타입을 타입 매개변수, 즉 제너릭으로 표기하고 기본 생성자를 호출한다
ArrayList<타입 매개변수> 객체명 = new ArrayList<타입 매개변수>(초기 저장 용량);
- 초기 저장 용량을 적어주지 않게 되면 기본적으로 10으로 지정된다
- 특정 인덱스의 객체를 제거하면, 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 하나씩 당겨진다
- 빈번한 객체 삭제 / 삽입이 일어나는 곳에서는 ArrayList보다 LinkedList를 사용하는 것이 좋다!
LinkedList
- 데이터를 효율적으로 추가 / 삭제 / 변경하기 위해 사용한다
- 배열에는 모든 데이터가 연속적으로 존재하지만, LinkedList에는 불연속적으로 존재한다
- LinkedList의 각 요소들은 데이터와 자신과 연결된 이전 요소 및 다음 요소의 주소값으로 구성되어 있다
- 그래서 데이터를 삭제할 때, 삭제하고자 하는 요소 이전 요소가 삭제하고자 하는 요소 다음 요소를 참조하게 함으로써 삭제를 진행한다
- 삭제되는 요소 다음 요소들을 앞으로 하나씩 당겨줄 필요가 없으니 처리 속도가 빠르다!
- 데이터를 추가할 때, 새로운 요소를 추가하고자 하는 위치의 이전 요소와 다음 요소 사이에 연결해줌으로써 추가를 진행한다
- 이전 요소가 새로운 요소를 참조하도록 하고 새로운 요소가 다음 요소를 참조하게 한다
ArrayList vs LinkedList
- ArrayList
- ArrayList에서 데이터를 추가 혹은 삭제를 할 때에는 다른 데이터를 복사해서 이동해야 한다
- ArrayList에서 객체를 순차적으로 저장할 때는 데이터를 이동하지 않아도 되므로 작업 속도가 빠르지만
- 중간에 위치한 객체를 추가 및 삭제할 때에는 데이터 이동이 많이 일어나므로 속도가 저하된다
- 데이터 검색을 할 때에는 인덱스가 n인 요소의 주소값을 얻기 위해 (배열의 주소 + n * 데이터 타입 크기)를 계산만 하면 되므로 데이터에 빠르게 접근이 가능하다!
- ArrayList의 **강점**
1. 데이터를 순차적으로 추가 / 삭제하는 경우
2. 데이터를 읽어들이는 경우
- 인덱스를 통해 바로 데이터에 접근할 수 있으므로 검색이 빠르다
- ArrayList의 **약점**
1. 중간에 데이터를 추가하거나, 중간에 위치하는 데이터를 삭제하는 경우
- 추가 또는 삭제 시, 해당 데이터의 뒤에 위치한 값들을 뒤로 밀거나 앞으로 당겨줘야 한다
- LinkedList
- LinkedList에서 중간에 데이터를 추가하면, 다음 요소의 주소값을 가리키는 Next와 이전 요소의 주소값을 가라키는 Prev에 저장되어 있는 주소값만 변경해주면 된다
- 즉, 데이터들을 뒤로 밀거나 앞으로 당겨줄 필요가 없다
- 즉, ArrayList보다 빠른 속도를 보여준다!
- 데이터 검색을 할 때에는 시작 인덱스에서부터 찾고자 하는 데이터가 나올 때까지 순차적으로 각 요소에 접근해야 하기 때문에 ArrayList보다 상대적으로 속도가 느리다!
- LinkedList의 **강점**
1. 중간에 위치하는 데이터를 추가 / 삭제하는 경우
- 데이터를 중간에 추가할 때에는 Prev와 Next 주소값만 변경하면 되므로 다른 요소들을 이동시킬 필요가 없어 빠른 속도를 보여준다
- LinkedList의 **약점**
1. 데이터 검색
- 데이터를 검색할 때 시작 인덱스부터 찾고자 하는 데이터까지 순차적으로 요소에 접근해야하므로 ArrayList보다 상대적으로 속도가 느리다!
Iterator
- 컬렉션에 저장된 요소들을 순차적으로 읽어오는 역할
- Iterator의 컬렉션 순회 기능은 Iterator 인터페이스에 정의되어 있다
- Collection 인터페이스에는 Iterator 인터페이스를 구현한 클래스의 인스턴스를 반환하는 메서드인 iterator()가 정의되어져 있다
- Collection 인터페이스에 정의된 iterator()를 호출하면, Iterator 타입의 인스턴스가 반환된다
- Collection 인터페이스를 상속받는 List, Set 인터페이스를 구현한 클래스들은 iterator() 메서드를 사용할 수 있다
| 메서드 | 설명 |
|---|
| hasNext() | 읽어올 객체가 남아 있으면 true를 반환하고 없으면 false를 반환한다 |
| next() | 컬렉션에서 하나의 객체를 읽어온다. 이 때, next()를 호출하기 전에 hasNext()를 통해 읽어올 다음 요소가 있는지 먼저 확인을 해야 한다 |
| remove() | next()를 통해 읽어온 객체를 삭제한다. next()를 호출한 다음에 remove()를 호출한다. |
ArrayList<Integer> list = new ArrayList<Integer>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
Iterator<Integer> iter = list.iterator();
while(iter.hasNext()) {
int n = iter.next();
}
for(int n : list) {
...
}
- next() 메서드는 컬렉션의 객체를 읽어오는 메서드일 뿐, 실제 컬렉션에서 객체를 빼내지는 않는다.
- remove() 메서드를 통해 컬렉션에서 실제로 객체를 삭제한다.
ArrayList<Integer> list = new ArrayList<Integer>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
Iterator<Integer> iter = list.iterator();
while(iter.hasNext()) {
int n = iter.next();
if(n == 2) iter.remove();
}
Set
- 요소의 중복을 허용하지 않고 저장 순서를 유지하지 않는 컬렉션
- Set 인터페이스에 정의된 메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
|---|
| 객체 추가 | boolean | add(Object o) | 주어진 객체를 추가하고, 성공하면 true를, 중복 객체면 false를 반환한다 |
| 객체 검색 | boolean | contains(Object o) | 주어진 객체가 Set에 존재하는지 확인한다 |
| boolean | isEmpty() | Set이 비어있는지 확인한다 |
| iterator | iterator() | 저장된 객체를 하나씩 읽어오는 반복자(iterator)를 반환한다 |
| int | size() | 저장되어 있는 전체 객체의 개수를 반환한다 |
| 객체 삭제 | void | clear() | Set에 저장되어져 있는 모든 객체를 삭제한다 |
| boolean | remove(Object o) | 주어진 객체를 삭제한다 |
HashSet
- Set 인터페이스를 구현한 컬렉션 클래스
- Set 인터페이스의 특징을 그대로 물려받아 중복된 값을 허용하지 않고, 저장 순서를 유지하지 않는다
- HashSet에 값을 추가할 때, 해당 값이 중복되는 값인지 판단하는 과정
- add(Object o)를 통해 객체를 저장하고자 한다
- 저장하고자 하는 객체의 해시코드를 hashCode() 메서드를 통해 얻어낸다
- Set이 저장하고 있는 모든 객체들의 해시코드를 hashCode() 메서드를 통해 얻어낸다
- 저장하고자 하는 객체의 해시코드와 Set에 이미 저장되어져 있던 객체들의 해시코드를 비교해서 같은 해시코드가 있는지 검사한다
- 만약 같은 해시코드를 가진 객체가 존재한다면 5번 과정을 진행한다
- 같은 해시코드를 가진 객체가 존재하지 않는다면, Set에 객체가 주가되며 add(Object o) 메서드가 true를 반환
- equals() 메서드를 통해 객체를 비교한다
- true가 반환된다면 중복 객체로 간주하고 Set에 추가하지 않으며, add(Object o)가 false를 반환한다
- false가 반환된다면 Set에 객체가 주가되며, add(Object o) 메서드가 true를 반환한다
TreeSet
- 이진 탐색 트리 형태로 데이터를 저장한다
- Set 인터페이스의 특징을 그대로 물려받아 데이터의 중복 저장을 허용하지 않고 저장 순서를 유지하지 않는다
- 이진 탐색 트리(Binary Search Tree)
- 하나의 부모 노드가 최대 2개의 자식 노드와 연결되는 이진 트리의 일종
- 정렬과 검색에 특화된 자료구조
- 최상위 노드를 '루트'라고 부른다
- 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가진다
Map<K, V>
Map
- 키(key)와 값(value)으로 구성된 객체를 저장하는 구조
- 이 객체를 Entry 객체라고 한다
- Entry 객체는 키와 값을 각각 Key 객체와 Value 객체로 저장한다
- Map을 사용할 때, 키는 중복 저장될 수 없지만 값은 중복 저장이 가능하다
- 키 역할이 값을 식별하는 것이기 때문에 중복되면 안된다!
- 기존에 저장된 키와 동일한 키로 값을 저장하려고 한다면, 기존의 값이 새로운 값으로 대치된다
- Map 인터페이스를 구현한 클래스에서 공통적으로 사용 가능한 메서드들
- List -> 인덱스를 기준으로 관리된다
- Map -> 키로 객체들을 관리한다
| 기능 | 리턴 타입 | 메서드 | 설명 |
|---|
| 객체 추가 | Object | put(Object key, Object value) | 주어진 키로 값을 저장한다. 해당 키가 새로운 키일 경우 null을 반환하지만, 동일한 키가 있을 경우에는 기존의 값을 대체하고 대체되기 이전의 값을 반환한다. |
| 객체 검색 | boolean | containsKey(Object key) | 주어진 키가 있으면 true를, 없으면 false를 반환한다 |
| boolean | containsValue(Object value) | 주어진 값이 있으면 true를, 없으면 false를 반환한다 |
| Set | entrySet() | 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아 반환한다 |
| Object | get(Object key) | 주어진 키에 해당하는 값을 반환한다 |
| boolean | isEmpty() | 컬렉션이 비어있는지 확인한다 |
| Set | keySet() | 모든 키를 Set 객체에 담아서 반환한다 |
| int | size() | 저장된 Entry 객체의 총 개수를 반환한다 |
| Collection | values() | 저장된 모든 값을 Collection에 담아서 반환한다 |
| 객체 삭제 | void | clear() | 모든 Map.Entry를 삭제한다 |
| Object | remove(Object key) | 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 반환한다 |
HashMap
- Map 인터페이스를 구현한 클래스
- 해시 함수를 통해 키와 값이 저장되는 위치를 결정한다
- 사용자는 그 위치를 알 수 없고 삽입되는 순서와 위치 또한 관계가 없다
- HashMap은 해싱(Hashing)을 사용하므로 많은 양의 데이터를 검색하는 데에 있어서 좋은 성능을 보인다
- HashMap의 개별 요소가 되는 Entry 객체는 Map 인터페이스의 내부 인터페이스인 Entry 인터페이스를 구현한다
- Map.Entry 인터페이스에는 다음과 같은 메서드들이 정의되어져 있다
| 리턴 타입 | 메서드 | 설명 |
|---|
| boolean | equals(Object o) | 동일한 Entry 객체인지 비교한다 |
| Object | getKey() | Entry 객체의 Key 객체를 반환한다 |
| Object | getValue() | Entry 객체의 Value 객체를 반환한다 |
| int | hashCode() | Entry 객체의 해시코드를 반환한다 |
| Object | setValue(Object value) | Entry 객체의 Value 객체를 인자로 전달한 value 객체로 변경한다 |
HashMap<Integer, Integer> map = new HashMap<>();
- Map은 키와 값을 쌍으로 저장하기 때문에 iterator()를 직접 호출할 수 없다
- 대신, keySet()이나 entrySet() 메서드를 이용해 Set 형태로 반환된 컬렉션에 iterator()를 호출하여 반복자를 만든 후, 반복자를 통해 순회할 수 있다

