
이전 스터디까지 불연속 메모리 기법으로 단편화를 해결하고자 페이징과 세그멘테이션에 대해 학습하였다.
이번 시간에는 페이지 교체 알고리즘에 대해 알아보고자 한다!
앞서 외부 단편화를 해결하고자 고정크기를 가진 페이지에 대해 알아보았는데, 필요한 페이지가 만일 메모리가 없다면 page-fault가 발생하게 되고 요청된 페이지를 디스크에서 메모리로 읽어와야 하는데 물리적 메모리에 빈 프레임이 존재하지 않을 수도 있다.
이때 빈 프레임도 없다면 victim frame을 골라야 하는 상황에 놓이는데 이때 해당 frame을 고르는 알고리즘이 바로 페이지 교체 알고리즘이다.
✅ Demand Paging
- 프로세스의 주소 공간을 메모리로 적재하는 기법
- 프로그램 실행 시 프로세스를 구성하는 모든 페이지를 한 번에 올리는 것이 아닌 당장 사용할 페이지만 올리는 방식
- 특정 프로세스를 구성하는 페이지에 대해 각 페이지 별 메모리 여부를 구별해야 한다.
- Demand Paging에서는 유효-무효 비트를 사용해 각 페이지가 메모리에 있는지 존재 여부 표시
❗ Page-Fault?
- CPU가 접근하려는 페이지가 현재 메모리가 없는 상황. (유효-무효 비트 모두 0인 상황)
- 페이지 부재가 발생하면 페이지를 디스크 단까지 올라가서 읽어야 하는데 이러면 막대한 오버헤드가 발생한다.
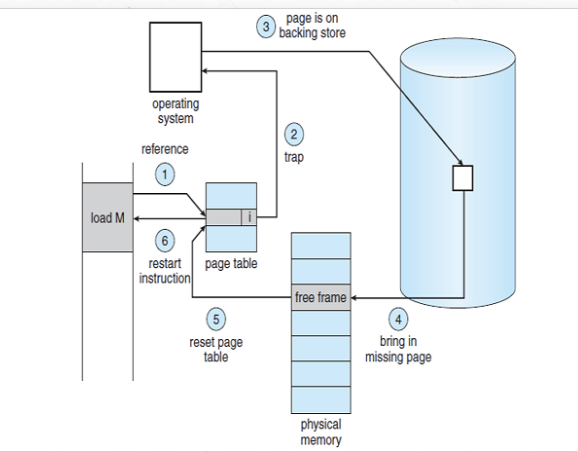
발생 과정은 아래 사진과 같다.
1. 찾으려는 페이지가 TLB(페이지 테이블 캐시)에 없는 경우, 해당 페이지가 메모리에 있는지 비트 확인
2. 유효-무효 비트가 0이면 MMU가 페이지 부재 트랩 발생하고, CPU 제어권이 커널 모드로 전환
3 & 4. 페이지 부재 처리 실행 (OS 접근 문제 확인 후 디스크 단까지 확인)
5. 페이지 테이블에서 해당 페이지 유효-무효 비트를 유효로 설정 후 프로세스를 Ready-Queue로 이동
6. 다시 CPU 할당 받았을 때, PCB에 있던 값 복원하여 중단된 명령 재수행
✅ Page Replacement Algorithm
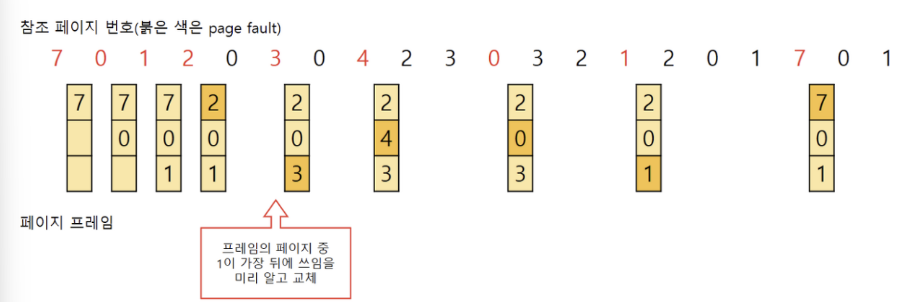
✍️ OPR - (Optimal Page Replacement)
앞으로 가장 오랫동안 사용되지 않을 페이지 교체
- 빌레디의 최적 알고리즘으로 MIN, OPT 등으로 불림
- 가장 이상적이며 프로세스가 앞으로 사용할 페이지를 알아야 하기에 온라인으로 사용 X
- 어떠한 알고리즘보다도 가장 적은 부재율을 보장
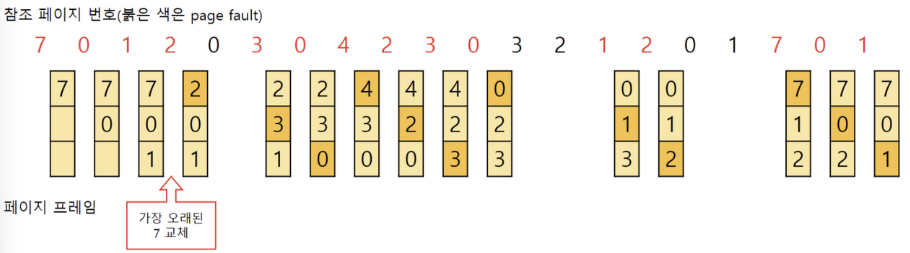
✍️ FIFO
- 먼저 들어온 페이지부터 교체
- 들어온 시간 혹은 올라온 순서대로 큐에 저장해 페이지 부재 발생 시 순서대로 페이지 교체
- 물리적 공간이 늘어났음에도 성능이 나빠질 수 있음
✍️ LRU (Least Recently Used)
- FIFO의 이상 현상 방지
- 메모리 페이지의 참조 성향 중 시간 지역성을 고려한 알고리즘
- 사용된 시간을 알 수 있는 부분을 저장해 오랫동안 참조되지 않은 페이지 교체
- 페이지마다 카운터가 필요(시간 저장위해), 큐로 구현 가능
- '시간'을 저장하기에 막대한 오버헤드 발생 가능

✍️ LFU (Least Frequently Used)
- 물리적 메모리 내 존재하는 페이지 중 과거 참조 횟수 적었던 페이지를 교체
- LRU가 직점 참조한 시점만을 반영한다면 LFU는 참조횟수를 통해 장기적 시간 규모에서의 참조 성향을 고려할 수 있음.
- 가장 최근에 불러온 페이지도 교체할 수 있으며 오버헤드 발생 가능

✍️ MFU (Most Frequently Used)
- 가장 많이 사용된 페이지가 앞으로는 사용되지 않겠지? 라는 가정에 의한 알고리즘
- 가장 많이 사용된 페이지부터 교체 진행
✍️ NUR=NRU (Not Used Recently)
- LRU 근사 알고리즘, 오랫동안 참조되지 않은 페이지 중 하나는 맞지만 가장 오래된 페이지라는 보장이 없음
- 각 페이지마다 참조비트와 변형비트가 사용되며 클래스로 구분지어 낮은 클래스부터 페이지를 랜덤하게 골라 교체 진행
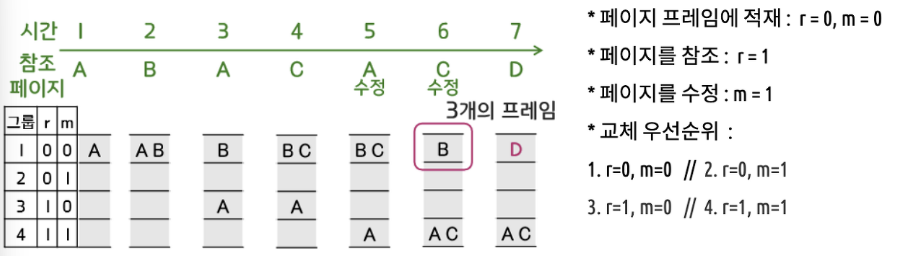
✍️ SCR (Second Chance Replacement)
- 가장 오랫동안 주기억장치(RAM)에 있던 페이지 중 자주 사용되는 페이지의 교체 방지
- FIFO 기법의 이상 현상 발생이라는 단점 보완
- 큐 상단의 참조 비트를 검사해 0이면 교체 대상, 1이면 0으로 바꾸어 큐 뒤에 append
✍️ Clock 알고리즘
- SCR을 원형 큐를 이용해 구현
- LRU, LFU와 달리 하드웨어적인 자원을 통해 동작 (참조 시점, 횟수를 SW적으로 유지 및 비교해야 함)
- 페이지 프레임의 참조 비트를 SCR과 동일하게 검사하여 교체 진행
🎇 참고자료 & 정리
위 자료들을 바탕으로 정리되었습니다.
학습을 진행하며 상당히 많은 양의 페이지 교체 알고리즘에 대해 알게되었고, 자료구조인 큐를 기반의 알고리즘이 많음을 알 수 있었다.
가장 간단하고 직관적인 FIFO, 그러나 이상 현상 발생이라는 문제가 있을 수 있고,
OPR이라 불리는 가장 이상적인 알고리즘도 있으나 모든 프로세스의 메모리 참조 계획을 미리 알아야하고 구현의 어려움이 있다.결론적으로, 주어진 상황에 맞게 알고리즘을 사용자가 선택하여 진행하는 것이 효율적이라고 할 수 있다. (기본적으로 대부분 OS에선 LRU를 사용하지만 이를 변형한 것을 쓰는데 Windows는 Clock을, 리눅스는 Second Chance를, Mac에서는 LRU Approximation을 쓴다고 한다.)
