✅ adf test
이전 전처리 진행한 모든 종목 2000개에 대해 정상성 테스트를 진행하였고 그 결과 11개를 제외한 1989개의 종목에 대해 정상성이 있다고 판단할 수 있는 통계적 검증을 마무리하였다.
따라서 11개의 종목에 한해 한계점으로 두고 모델링을 진행해보아 수익률 예측을 통해 랭킹화, 샤프지수 계산을 진행해보고자 한다.
🎈 Modeling 진행 방안.
- 종목이 2000개인데, 이를 일일이 다 예측을 하기 위해선 각각 모델링을 진행해야 하는가?
- 각 종목 2000개에 대해 주가를 일일이 예측을 하는 방법 강구.
-> LSTM? 모델 2000개를 만들어야 함. 근데 row가 494 뿐. 과연 적용 가능? (use-case 살펴볼 필요 있음)- 통계적 검증을 거친 전처리를 이용, ARIMA 적용? 2000개?
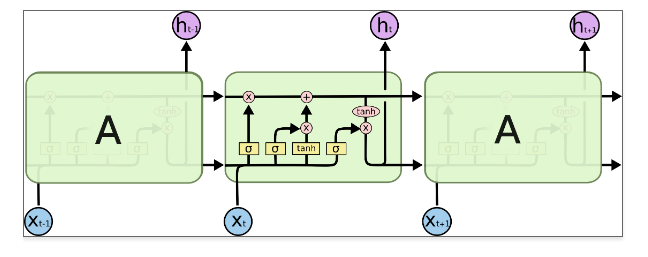
✅ LSTM (Long Short-Term Memory)
기존 RNN의 장기적 정보 손실에 대해 보완한 신경망 구조로 NLP, Time Series data에 사용된다.
기본 구조를 살펴보면 다음과 같다.
RNN과 같은 체인구조로 되어 있으나, 반복 모듈은 단순 한 개의 tanh layer가 아닌 4개의 layer가 서로 정보를 주고 받는 구조로 되어있다. LSTM에서는 ht(단기 상태), ct(장기 상태)로 2개의 벡터로 나뉜다.
✅ ARIMA
시계열 데이터 내 비정상성이 포함된 상황에서 시계열 예측을 하기 위해 적용하는 기법.
ARIMA(p,d,q)로 모델 학습 진행. (d는 차수를 의미, p와 q는 각각 자기회귀 부분 차수, 이동 평균 부분 차수를 의미한다.
-> AR 모델에서 p는 독립변수 개수를 의미, MR모델에서 q는 파라미터 개수를 의미MA, AR, ARMA 모델 중 선택 필요
1. MA : ACF는 lag q 이후 절단되는 패턴 / PACF는 천천히 감소하는 패턴
2. AR : PACF이 lag p 이후 확 떨어지고 ACF가 지수적으로 감소하거나 sin함수 형태로 소멸
3. ARMA : ACF, PACF가 (q-p)시점 이후부터 떨어질 때.🧨 현 상황.
변화량을 가해준 종가 column을 활용해 date, target만을 이용한 ARIMA 모델 학습을 진행하고자 한다.
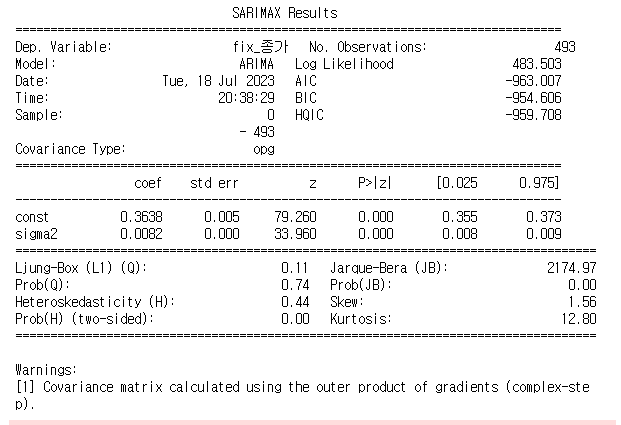
현재 변화량을 1회 가했으므로 차분이 1회 진행되었다고 볼 수 있고 p,d,q를 각각 0, 0, 0으로 두었을 때 결과는 위와 같다.
이를 해석해보면 다음과 같다.
- 일반적으로 AIC, BIC가 모델의 적합도를 의미하는데, 해당 수치가 -950 이하로 매우 낮은 것을 확인할 수 있다. -> 따라서 모델을 예측에 사용가능!
- 모델의 잔차의 분산을 뜻하는 sigma2가 0.0082로 매우 낮은 것을 보아 적절한 변동성을 가진 것을 확인할 수 있다.
-> 이때 나오는 sigma2의 변동성을 가지고 포트폴리오 작성에 사용할 수 있지 않을까??