Compitition with AI Stages(1강)
Pstage?
코드를 많이 쳐볼 수 있는 기회
실습위주의 skills 학습
전체적인 파이프라인(전처리 training, 제출 등) 경험
Compitition이란?
kaggle, dacon…경진대회 많음
주최자가 원하는거: 데이터를 줄테니깐 좋은 방식을 알려줘..(우린 해결못했어)
직접 하면서 얻어가는게 많음
details
compitition은 먼저 방향성(overview;목적, background, 의미, 이유, 대상, 도메인…)을 봐야함
문제를 집요하게 봐야함!!
중간에 의사결정하는 과정이 있는데 방향성을 가지면 원활하게 할 수 있음
숙제!!
- problem definition
problem definition!!!!, 가장 중요
내가 풀어야 할 문제는 무엇인가
이 문제의 input과 output은 무엇인가
이 솔루션는 어디서 어떻게 사용되어지는가
- Data Description(데이터 스펙 요약본)
데이터가 어떻게 구성되어있는지 소개
field의 의미가 어떤지
→ 문제를 이해하는데 도움
- notebook
데이터 분석, 모델 학습, 테스트 셋 추론의 과정을 서버에서 연습 가능
- submission & leaderboard
모델의 성능이 어떤지 확인하고 순위가 어떤지 확인
- discussion
등수를 올리는 것 보다 문제를 해결하고싶은 마음으로 많이 올림
이거를 활발하게 올리는게 좋음
새로운 시야를 제공할수도있음, compitition의 절대적인 가치가 상승할 수 있음
Why Compitition?
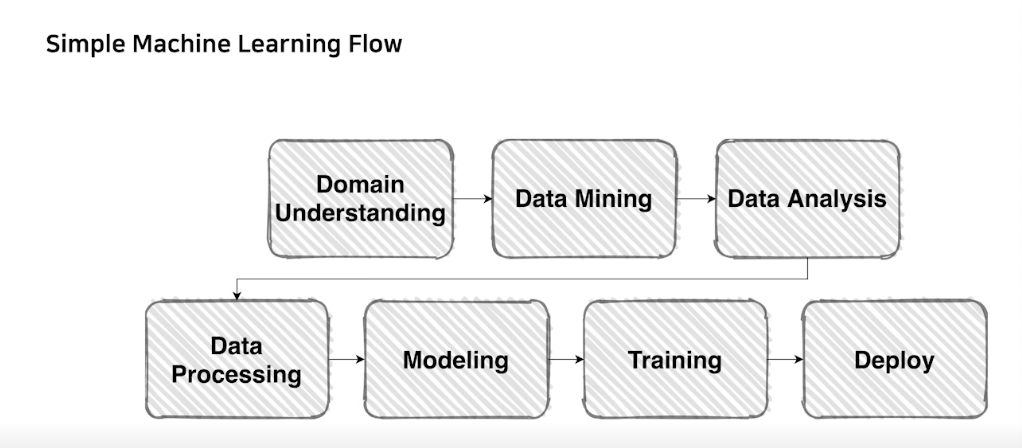
전체적인 파이프라인은 다음과 같음
그중 compitition은 domain understanding, data analysis, data processing, modeling, training을 경험할 수 있음
먼저 해야할 것은 domain understading임, 이에 따라 문제정의를 명확하게 해야함
Image Classification & EDA
EDA(exploratory data analysis)란
탐색적 데이터 분석; 데이터를 이해하기 위한 노력
우리는 데이터로 존재할 때 바로 알 수가 없음
image classification에서는 사실 이미지와 그에대한 메타데이터밖에 없기 때문에 할게 별로 없음
EDA란 데이터를 이해하기 위한 여러가지 방법 중 우리가 궁금한걸 알아보는 과정!!
목적: 실제로 데이터가 어떻게 생겨먹었나, 궁금한 것?, 주제와 연관성? 알고 싶은 것? 주어진 데이터 타입의 특성? 메타데이터의 분포? 탐색이 중요함!! 어떤 호기심을 가지고 있는지 명제를 제시하고 검색을 통해 코드 구현
도구: 손, python, excel, etc.. 도구는 그냥 도구일 뿐!
EDA는 무한반복임!!!
Image Classification
image: 시각적 인식을 표현한 인공물(Artifact), (width, height, channel)로 표현
classification이란 input + model 로 output을 만드는 것
우리는 output이 원하는 category로 나오는 것임
- Baseline
데이터셋, 데이터 제너레이션, 모델 만들고 업데이트 하는 방법 학습과 추론 … 코드는 제공받지만 강의를 듣고 스스로 해보기, 해봤던것과 예시코드 비교
Dataset
바닐라한 데이터를 그대로 쓰기는 쉽지 않다.
우리 모델을 위한 데이터셋이 필요하다.
)
EDA는 무한반복임, Data Processing을 통해 계속 탐구할 것이다.
주어진 바닐라 데이터를 모델이 좋아하는 형태로 dataset으로
(batch, channel, height, width)
데이터를 뽑아낼 수 있는 기능구현을 하면 어떤게 들어와도 모델학습하는데는 무리가 없음
Pre-processing(전처리)
datascience의 80%가 전처리다.
좋은데이터를 넣어주는게 모델에 좋음→전처리과정이 좋은데이터를 만드는 것임
*보통 경진대회용 데이터는 그 품질이 양호하다
- bounding box
가끔 필요 이상으로 많은 정보를 가지고 있기도 한다. 원하는 object를 명확하게 표시해줄 수 있으면 모델에 좋을수도 있다.(bounding box이외에는 noise)

- Resize
계산의 효율을 위해 적당한 크기로 사이즈 변경, 너무 큰사이즈는 계산량이 많아서 모델학습이 어려움
resizing은 작업의 효율화이다. 너무 크게되면 모델이 너무 복잡해짐
- 전처리는 도메인, 데이터 형식에 따라 정말 다양한 case가 존재한다.
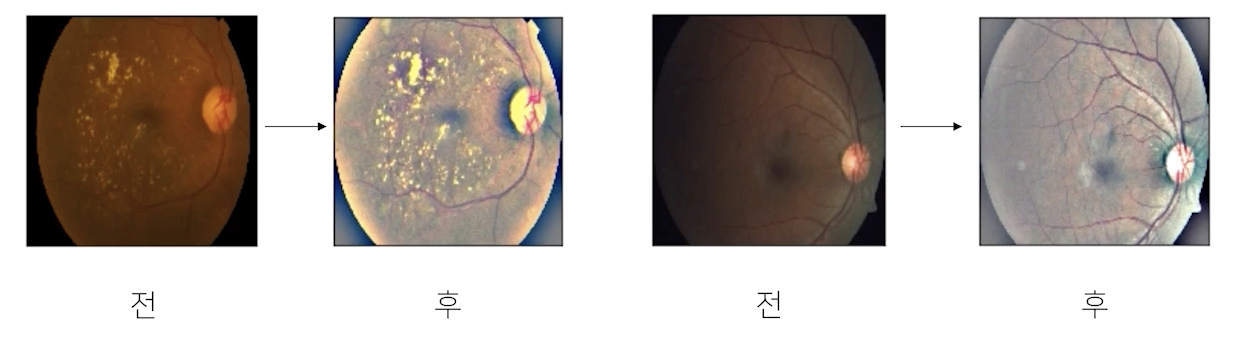
전처리를 잘하면 목적에 맞는 좋은 데이터를 수집할 수 있음
Generalization
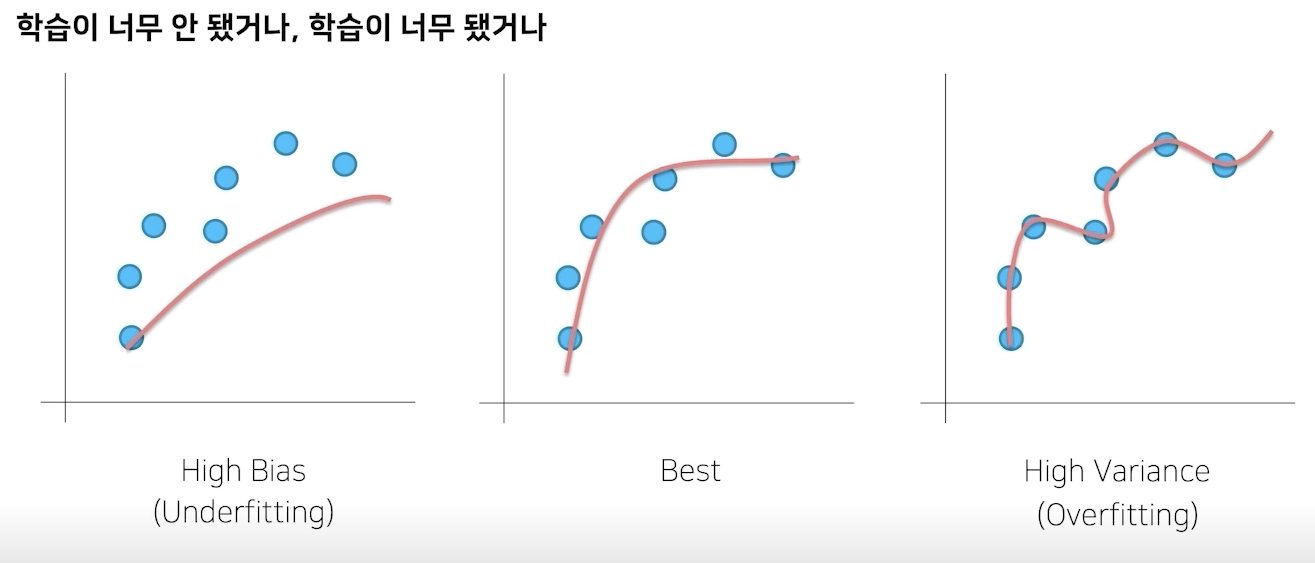
variance가 높은 모델은 noise까지 다 학습해버림
bias가 큰 것은 데이터를 충분히 학습하지 못해 편향된 결과를 가져오게 된다.
Data Augmentation

주어진 데이터가 가질 수 있는 case(경우), state(상태)의 다양성
야외에서 생길 수 있는 여러가지 noise는 많음.
- image에 적용할 수 있는 다양한 함수들
torchvision.transforms
Original, RandomCrop, Flip
우리가 사진 찍을 때 뒤집혀서 찍을일이 있을까? crop된 사진이 찍힐일이 있을까?
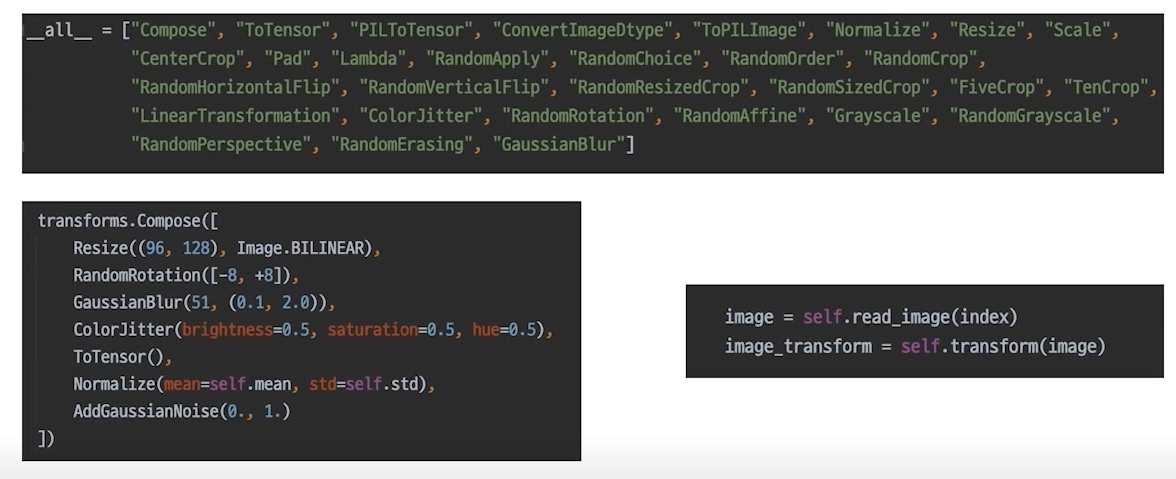
compose: 여러개 적용
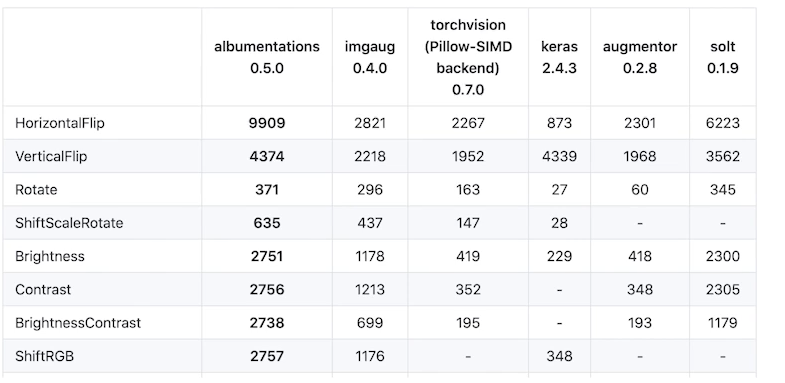
- Albumentations: 더 빠르고 다양하다.
##주의##
무조건이라는 단어 조심!
항상 좋은 결과를 가져다 주지 않느다. 앞서 정의한 problem(주제)을 깊이 관찰해서 어떤 기법을 적용하면 이러이러한 다양성을 가질 수 있겠다 가정하고 실험으로 증명해야 한다.
실험했을 때 scoring이 떨어질수도 있음, 실험으로 증명해야지 당위성을 증명할 수 있다.
Data Generation

데이터를 잘 구성해도 잘 출력해야지만 실속이 있다.
- 데이터를 잘 만들어 준다는 것이란?
Data Feeding
generation이 데이터를 모델에 잘 먹여준다라는 뜻으로 해석할 수 있음
feeding: 대상의 상태를 고려해서 적정한 양을 줘야한다.
모델자체가 처리할 수 있는 양이 있음, 따라서 이 모델이 어느정도 처리할 수 있는지 알아야함
→ 모델의 처리량만큼 우리가 데이터를 generating할 수 있는지 알아야함(GPU를 최대한 쓰기 위해서)
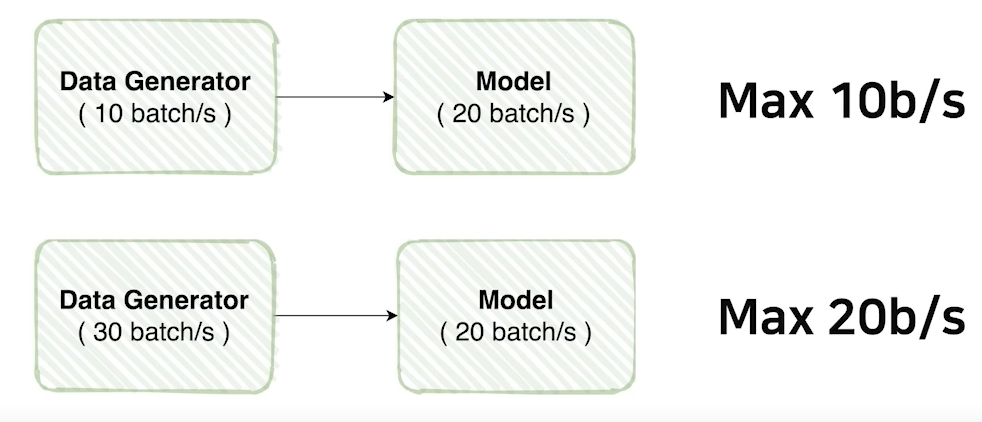
모델이 처리할 수 있는만큼의 데이터를 뽑아낼 수 있는가를 확인하고 튜닝해야한다.
resize하고 rotation하는게 시간 더오래걸림
데이터셋을 만드는 것도 튜닝이 필요하다(시간고려)
→ 데이터가 만들어지는 속도도 중요하고 튜닝도 중요하다
torch.utils.data
데이터셋을 클래스로 구현하는 방식
파이토치 스러운 dataset과 dataloader
utils.data에 정리되어 있음
Dataset
vanilla data를 dataset으로 변환 (batch, channel, heigth, width)
여러가지형태로 존재하는 데이터를 모델이 원하는 형태로 변환, 치환해서 뿌려줄 수 있게끔 구성
원하는 augmentation, 전처리 과정
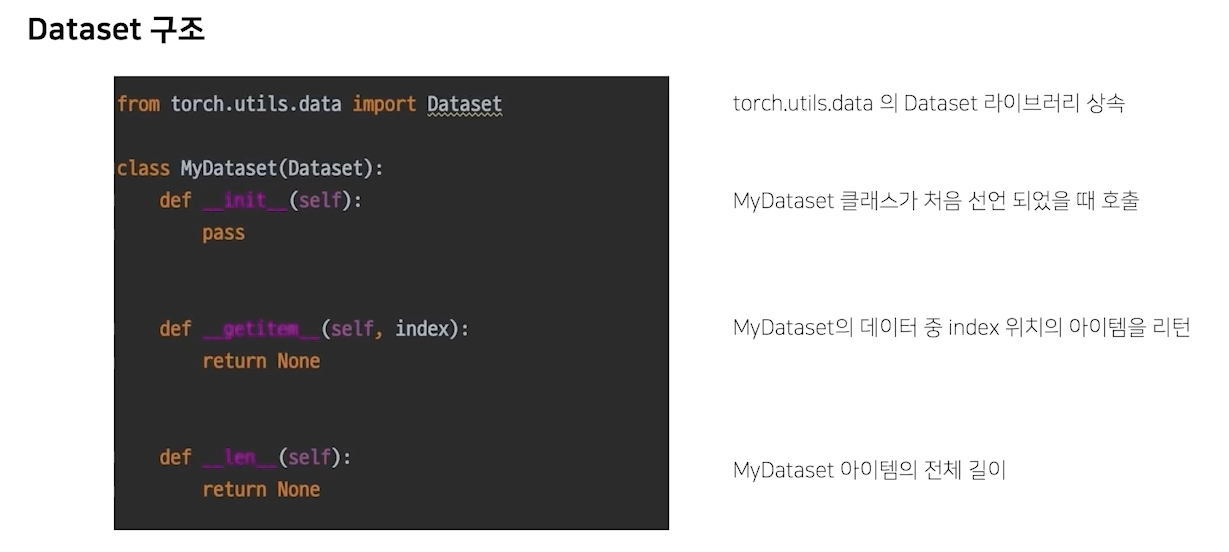
데이터셋이라면 가지고있어야할 기능들임!!(init, getitem, len)
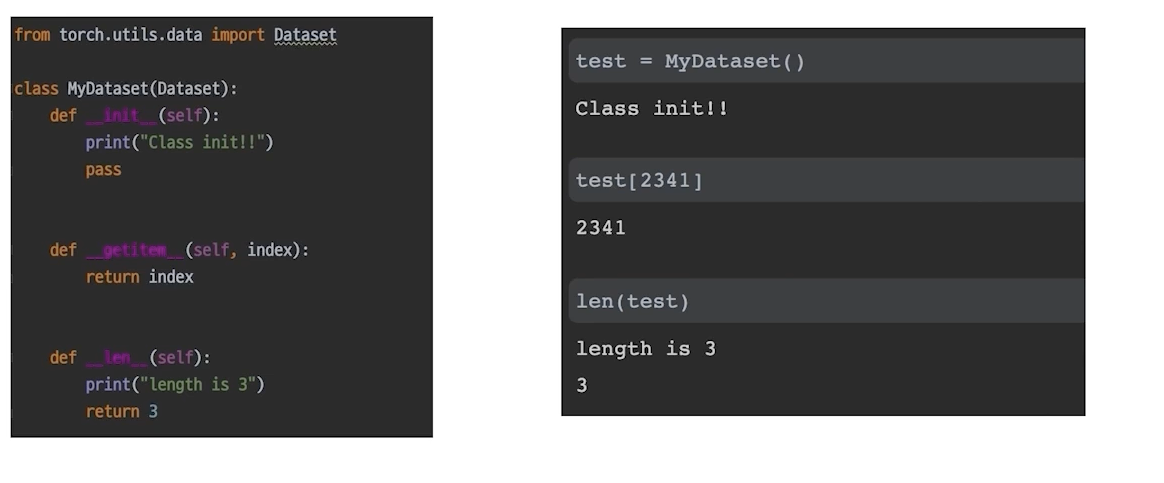
DataLoader
내가 만든 dataset을 효율적으로 사용할 수 있도록 관련 기능 추가
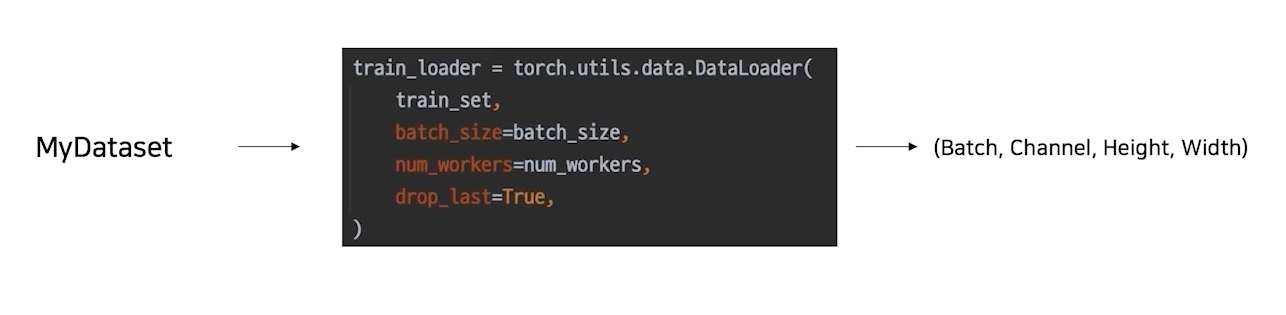
데이터셋을 원하는대로 뽑아낼 수 있지만 함수를 써서 효율적으로 만들면 좋지 않을까? 해서 만들어진게 dataloader
데이터셋을 효율적으로 잘 쓰기 위한 utils
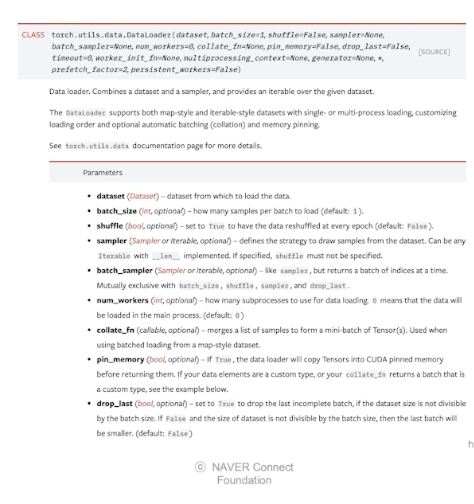
- dataset과 dataloader는 분리되는 것이 좋다.
dataset과 dataloader는 엄연히 하는 일이 다르다.
재사용성이 중요하므로 분리시켜주는 것이 효율적이다.
참고: boostcamp aitech4기 6주차 김태진 마스터님 강의
