< 스프링 DB 1편 - 데이터 접근 핵심 원리> 강의를 보고 이해한 내용을 바탕으로 합니다.
커넥션 풀
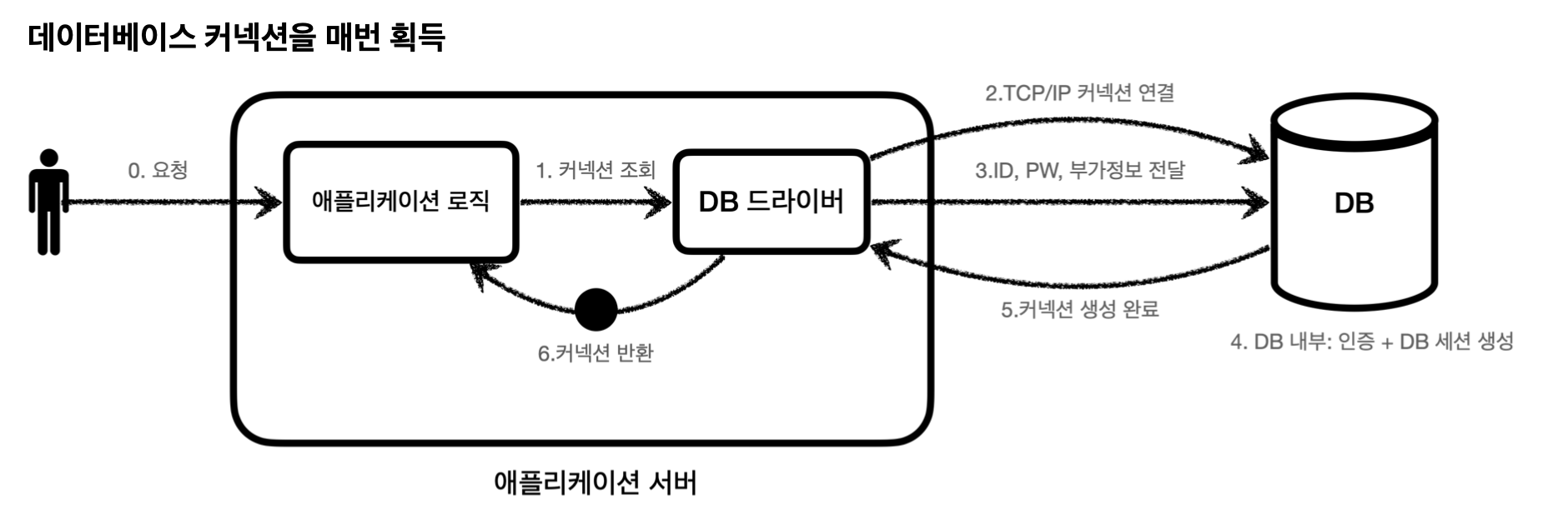
데이터베이스 커넥션을 획득하는 과정은 복잡하다.
DB 드라이버를 통해 커넥션을 조회한다.DB 드라이버는DB와TCP/IP커넥션을 연결한다.
(이 과정에서 3 way handshake같은TCP/IP연결을 위한 네트워크 동작이 발생한다.)- 이후
DB 드라이버는 ID, PW와 기타 부가정보를DB에 전달한다. DB는 내부 인증을 완료하고 내부에 DB세션을 생성한다.DB는 커넥션 생성 완료 응답을 보낸다.DB 드라이버- 커넥션 객체 생성하여 클라이언트에 반환한다.
애플리케이션 서버에서도 TCP/IP 커넥션을 새로 생성하기 위한 리소스를 매번 사용해야 한다. 가장 큰 문제는 SQL을 실행하는 시간 + 커넥션을 새로 만드는 시간 => 고객이 애플리케이션을 사용할 때 응답 속도에 영향을 준다.
(참고로 데이터베이스마다 커넥션을 생성하는 시간은 다르다.)
=> 커넥션을 미리 생성해두고 사용하자! : 커넥션 풀
커넥션 풀은 이름 그대로 커넥션을 관리하는 풀(like 수영장 풀 🏊🏻♀️)이다.
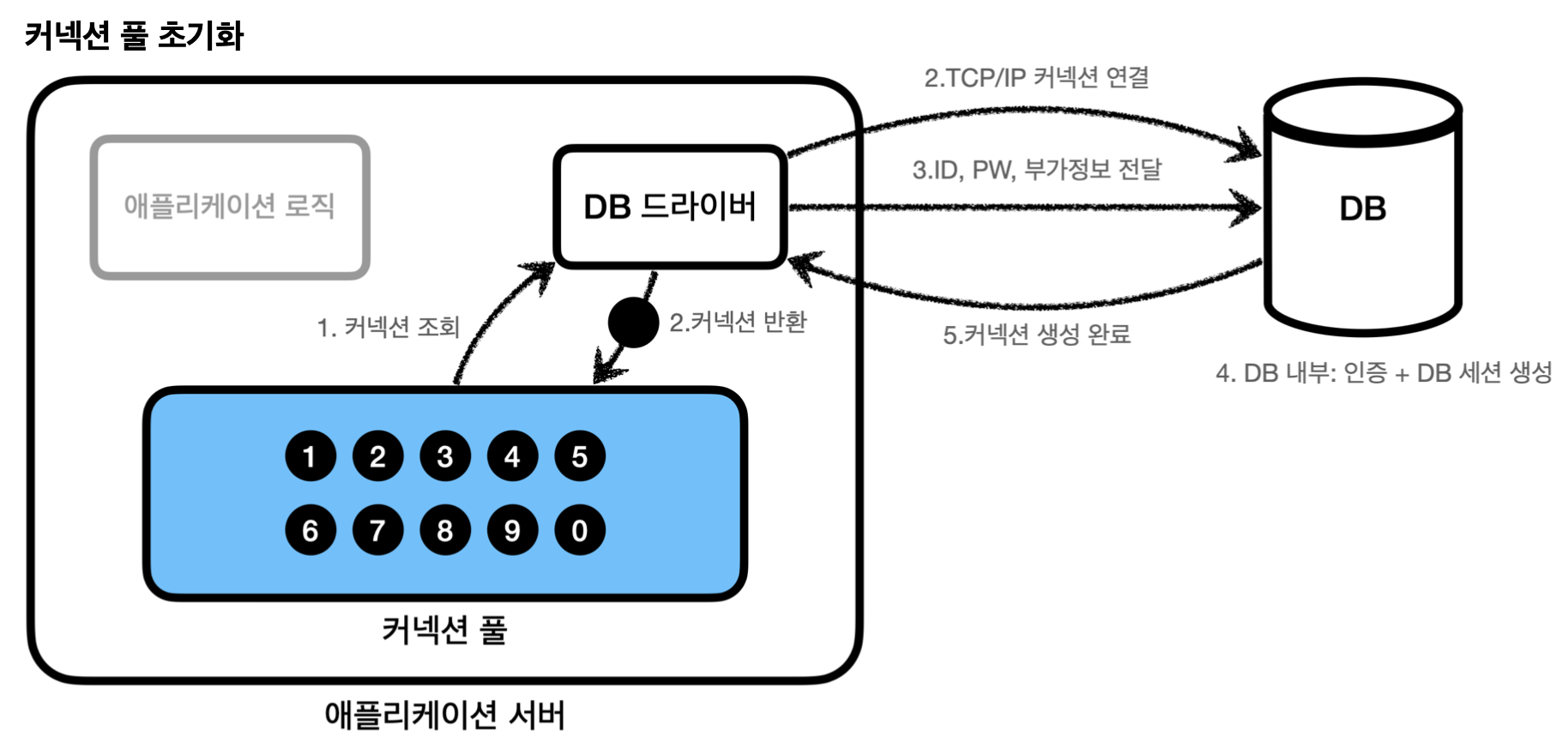
애플리케이션을 시작하는 시점에 필요한 만큼 커넥션을 미리 확보해서 풀에 보관한다. (기본값은 보통 10개)
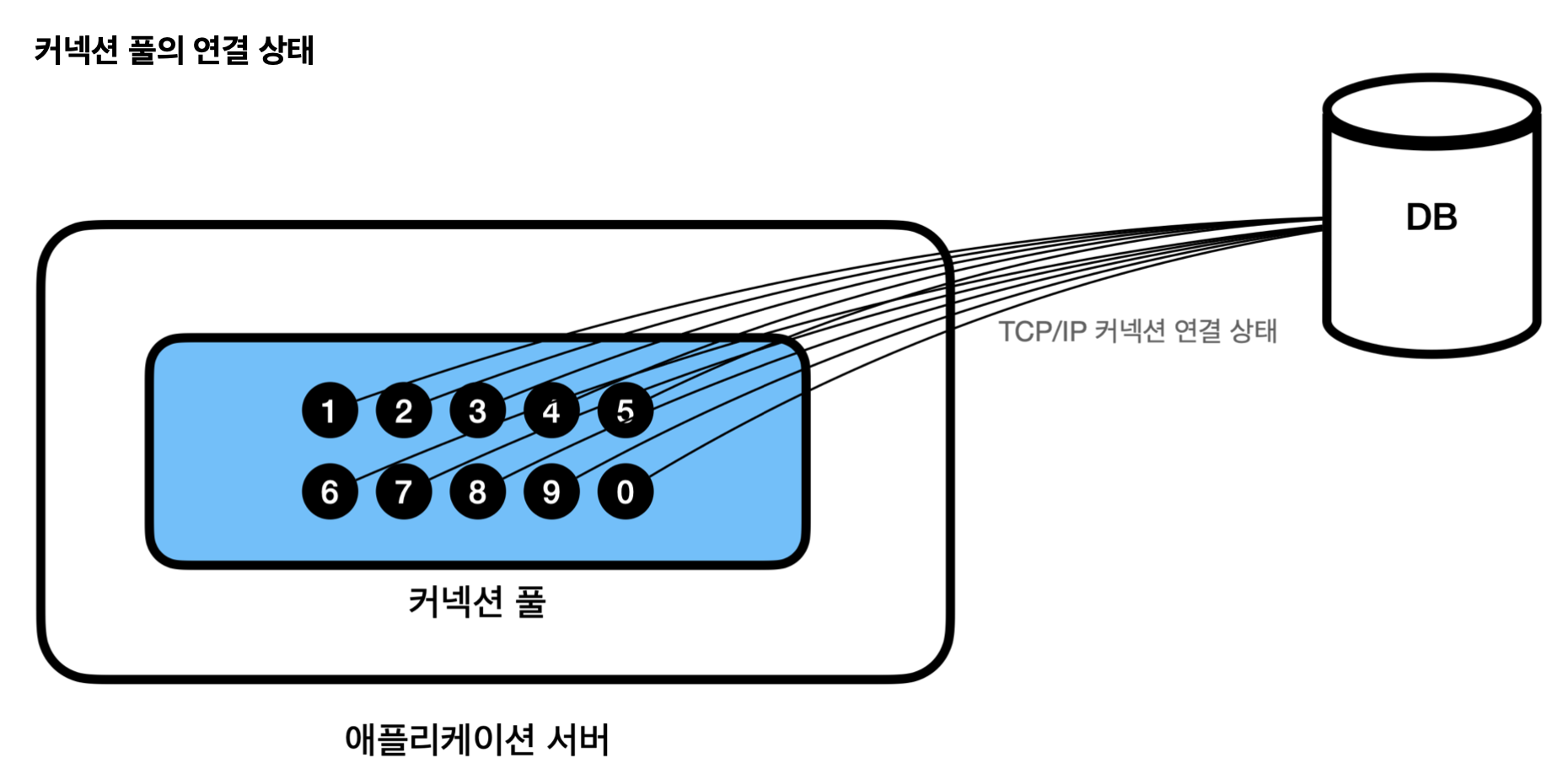
커넥션 풀의 커넥션은 TCP/IP로 DB와 커넥션이 연결되어 있는 상태이므로 즉시 SQL을 DB에 전달할 수 있다.
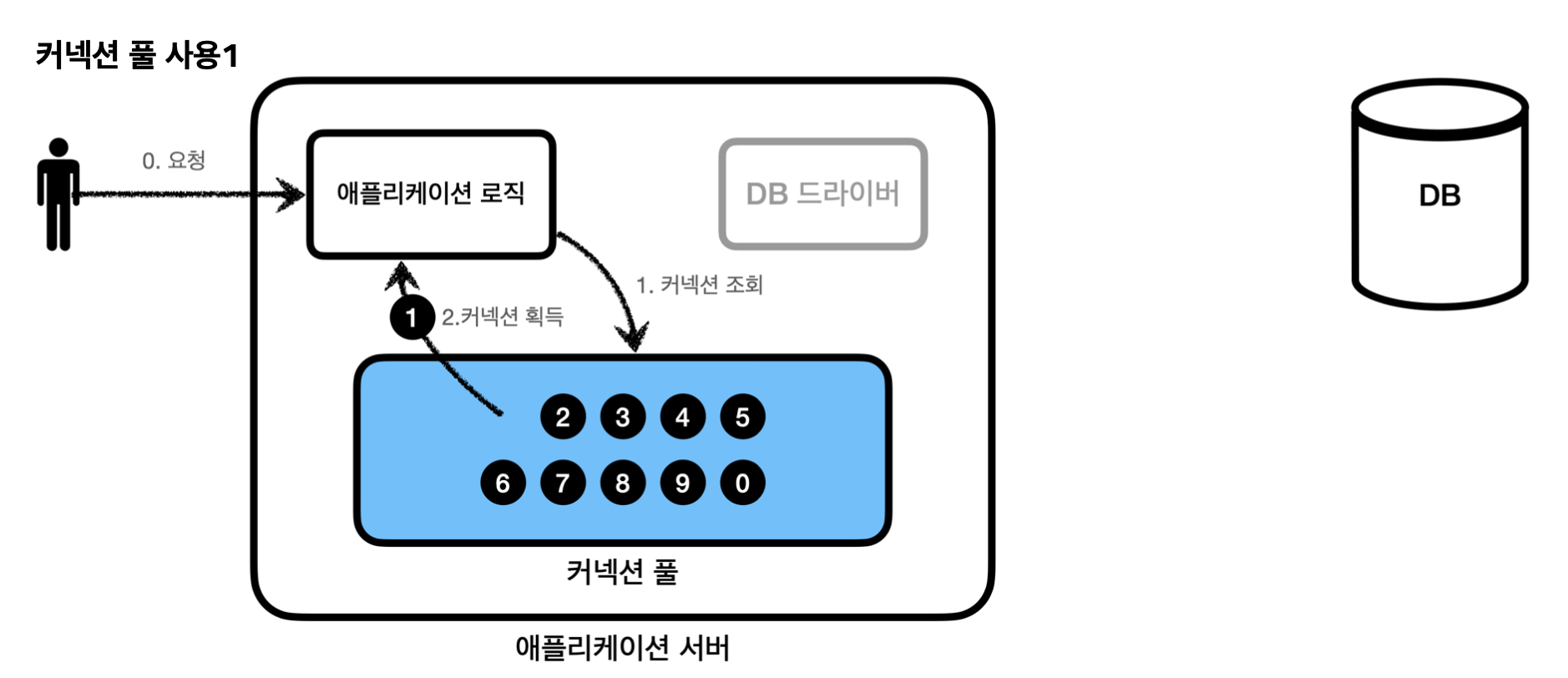
애플리케이션 로직에서 DB 드라이버를 통해 새로운 커넥션을 획득하는 것이 아니라, 커넥션 풀을 통해 이미 생성되어 있는 커넥션을 객체 참조로 그냥 가져다 쓰면 된다. 커넥션 풀에 커넥션을 요청하면 커넥션 풀은 자신이 가지고 있는 커넥션 중에 하나를 반환한다.
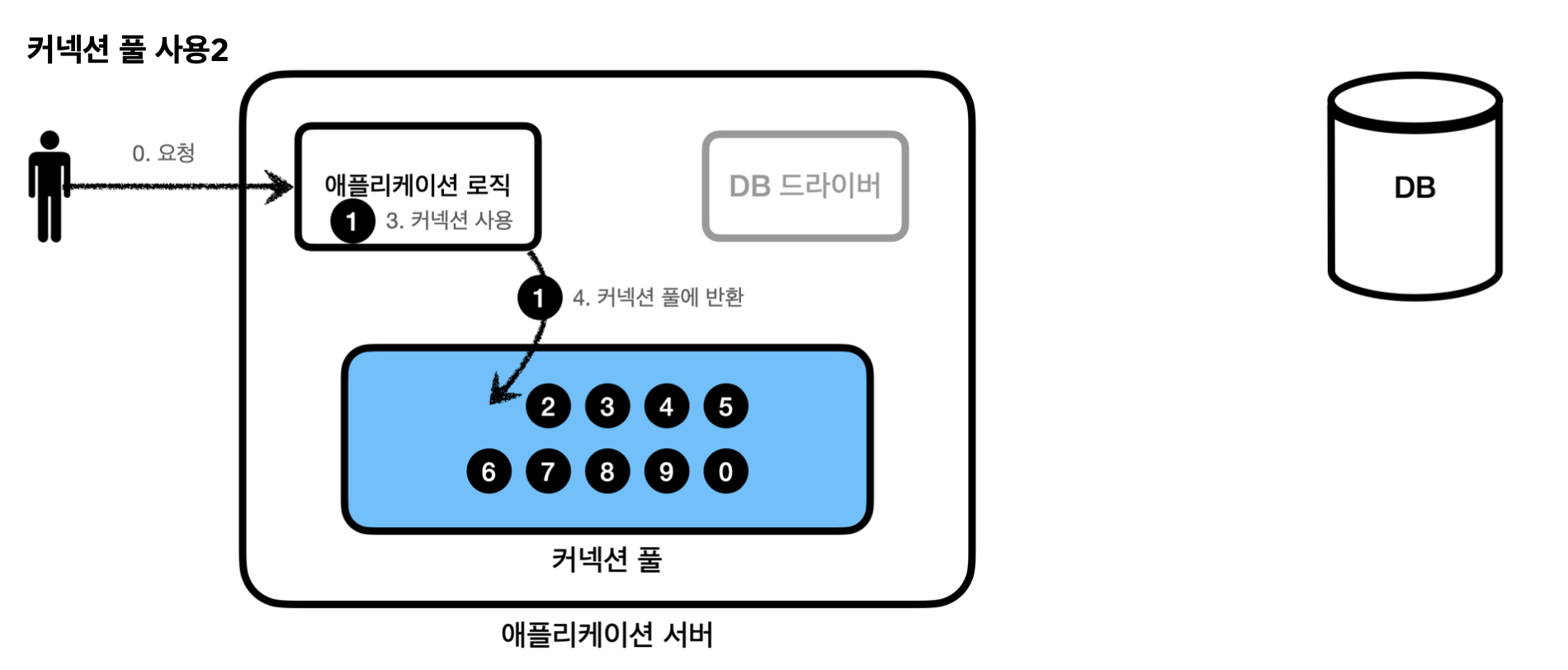
애플리케이션 로직은 커넥션 풀에서 받은 커넥션을 사용해서 SQL을 데이터베이스에 전달하고 그 결과를 받아서 처리한다. 커넥션을 모두 사용하고 나면 커넥션을 종료하는 것이 아니라 커넥션이 살아있는 상태로 커넥션 풀에 반환한다.
- 적절한 커넥션 풀 숫자는 서비스의 특징과 애플리케이션 서버 스펙, DB 서버 스펙에 따라 다르기 때문에 성능 테스트를 통해서 정해야 한다.
- 커넥션 풀은 서버당 최대 커넥션 수를 제한할 수 있다. 따라서 DB에 무한정 연결이 생성되는 것을 막아주어서 DB를 보호하는 효과도 있다.
- 실무에서는 항상 기본으로 사용한다.
- 커넥션 풀은 개념적으로 단순해서 직접 구현할 수도 있지만 사용도 편리하고 성능도 뛰어난 오픈소스 커넥션 풀이 많기 때문에 오픈소스를 사용하는 것이 좋다.
- 대표적인 커넥션 풀 오픈소스는
commons-dbcp2,tomcat-jdbc pool,HikariCP등이 있다.- 성능과 사용의 편리함 측면에서 최근에는
HikariCP를 주로 사용한다. 스프링부트 2.0부터는 기본 커넥션 풀로HikariCP를 제공한다. 성능, 사용의 편리함, 안전성 측면에서 이미 검증이 되었기 때문에 커넥션 풀을 사용할 때는 고민하지말고HikariCP를 사용하면 된다.(실무에서도 대부분HikariCP를 사용한다.)
DataSource
커넥션을 얻는 방법
- JDBC
DriverManager직접 사용 - 커넥션 풀
DriverManager 를 통해서 커넥션을 획득하다가, 커넥션 풀을 사용하는 방법으로 변경하려면?
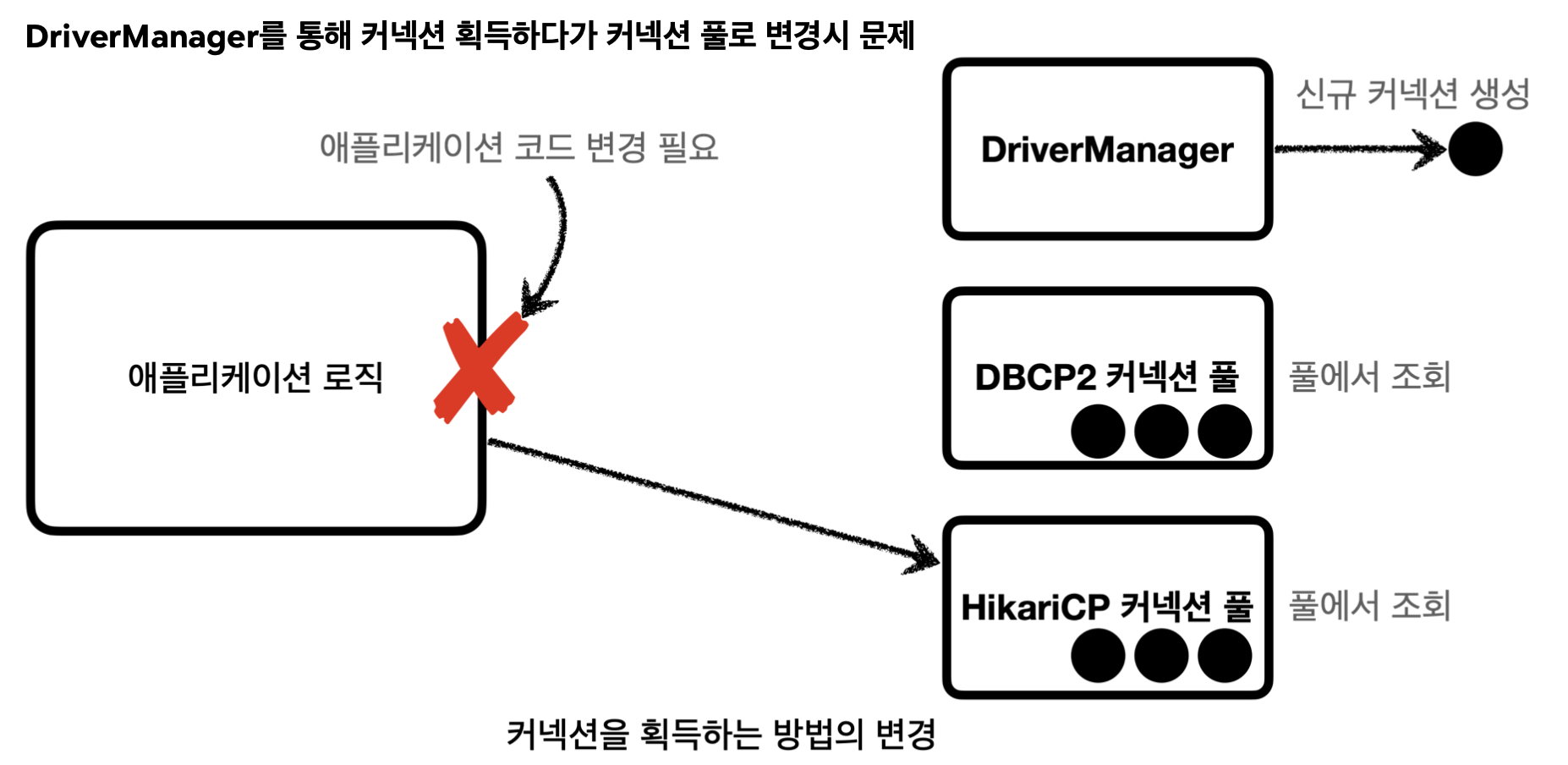
예를 들어서 애플리케이션 로직에서 DriverManager 를 사용해서 커넥션을 획득하다가 HikariCP 같은 커넥션 풀을 사용하도록 변경하면 커넥션을 획득하는 애플리케이션 코드도 함께 변경해야 한다. 의존관계가 DriverManager 에서 HikariCP 로 변경되기 때문이다. (둘의 사용법도 조금씩 다를 것이다.)
⭐️커넥션을 획득하는 방법을 추상화⭐️

- 자바에서는
javax.sql.DataSource라는 인터페이스를 제공한다. DataSource: 커넥션을 획득하는 방법을 추상화하는 인터페이스이다.- 이 인터페이스의 핵심 기능은 커넥션 조회 하나이다.
public interface DataSource {
Connection getConnection() throws SQLException;
}
- 대부분의 커넥션 풀은
DataSource인터페이스를 이미 구현해두었다.
따라서 개발자는DBCP2 커넥션 풀,HikariCP 커넥션 풀의 코드를 직접 의존하는 것이 아니라DataSource인터페이스에만 의존하도록 애플리케이션 로직을 작성하면 된다.- 커넥션 풀 구현 기술을 변경하고 싶으면 해당 구현체로 갈아끼우기만 하면 된다.
DriverManager는DataSource인터페이스를 사용하지 않는다. 따라서DriverManager는 직접 사용해야한다. 따라서DriverManager를 사용하다가DataSource기반의 커넥션 풀을 사용하도록 변경하면 관련 코드를 다 고쳐야 한다. 이런 문제를 해결하기 위해 스프링은DriverManager도DataSource를 통해서 사용할 수 있도록DriverManagerDataSource라는DataSource를 구현한 클래스를 제공한다.- 자바는
DataSource를 통해 커넥션을 획득하는 방법을 추상화했다. 이제 애플리케이션 로직은DataSource인터페이스에만 의존하면 된다. 덕분에DriverManagerDataSource를 통해서DriverManager를 사용하다가 커넥션 풀을 사용하도록 코드를 변경해도 애플리케이션 로직은 변경하지 않아도 된다.
DataSource - DriverManager 코드로 이해하기
기존 DriverManager
@Test
void driverManager() throws SQLException {
Connection conn1 = DriverManager.getConnection(URL, USERNAME, PASSWORD);
Connection conn2 = DriverManager.getConnection(URL, USERNAME, PASSWORD);
log.info("connection={}, class={}", conn1, conn1.getClass());
log.info("connection={}, class={}", conn2, conn2.getClass());
}DriverManagerDataSource
@Test
void dataSourceDriverManager() throws SQLException {
//DriverManagerDataSource - 항상 새로운 커넥션 획득
DriverManagerDataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
useDataSource(dataSource);
}
private void useDataSource(DataSource dataSource) throws SQLException{
Connection conn1 = dataSource.getConnection();
Connection conn2 = dataSource.getConnection();
log.info("connection={}, class={}", conn1, conn1.getClass());
log.info("connection={}, class={}", conn2, conn2.getClass());
}기존 코드와 비슷하지만 DriverManagerDataSource는 DataSource를 통해서 커넥션을 획득할 수 있다. (DriverManagerDataSource는 스프링이 제공하는 코드)
기존 DriverManager를 통해서 커넥션을 획득하는 방법과 DataSource를 통해서 커넥션을 획득하는 방법에는 큰 차이가 있다.
DriverManager는 커넥션을 획득할 때마다 URL, USERNAME, PASSWORD같은 파라미터를 계속 전달해야한다. 반면에 DataSource를 사용하는 방식은 처음 객체를 생성할 때만 필요한 파라미터를 넘겨두고, 커넥션을 획득할 때는 단순히 dataSource.getConnection()만 호출하면 된다.
설정과 사용의 분리
- 설정 :
DataSource를 만들고 필요한 속성들을 사용해서 URL, USERNAME, PASSWORD같은 부분을 입력하는 것을 말한다. 이렇게 설정과 관련된 속성들은 한 곳에 있는 것이 향후 변경에 더 유연하게 대처할 수 있다. - 사용 : 설정은 신경쓰지 않고,
DataSource의getConnection()만 호출해서 사용하면 된다.
필요한 데이터를 DataSource 가 만들어지는 시점에 미리 다 넣어두게 되면, DataSource 를 사용하는 곳에서는 dataSource.getConnection() 만 호출하면 되므로, URL , USERNAME , PASSWORD 같은 속성들에 의존하지 않아도 된다. 그냥 DataSource 만 주입받아서 getConnection() 만 호출하면 된다.
즉, 리포지토리(Repository)는 DataSource 만 의존하고, 이런 속성을 몰라도 된다. 애플리케이션을 개발해보면 보통 설정은 한 곳에서 하지만, 사용은 수 많은 곳에서 하게 된다. 덕분에 객체를 설정하는 부분과, 사용하는 부분을 좀 더 명확하게 분리할 수 있다.
DataSource - 커넥션 풀 코드로 이해하기
@Test
void dataSourceConnectionPool() throws SQLException, InterruptedException {
//커넥션 풀링
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
dataSource.setMaximumPoolSize(10);
dataSource.setPoolName("MyPool");
useDataSource(dataSource);
Thread.sleep(1000);
}HikariCP커넥션 풀을 사용한다.HikariDataSource는DataSource인터페이스를 구현하고 있다.- 커넥션 풀 사이즈를 10, 풀의 이름을 MyPool이라고 지정했다.
- 커넥션 풀에서 커넥션을 생성하는 작업이 애플리케이션 실행 속도에 영향을 주지 않기 위해 별도의 쓰레드에서 작동시킨다. 별도의 쓰레드에서 동작하기 때문에 테스트가 먼저 종료되어 버린다. 따라서
Thread.sleep을 통해 대기 시간을 주어야 쓰레드 풀에 커넥션이 생성되는 로그를 확인할 수 있다.
//실행 결과
#커넥션 풀 초기화 정보 출력
HikariConfig - MyPool - configuration:
HikariConfig - maximumPoolSize................................10 HikariConfig - poolName................................"MyPool"
#커넥션 풀 전용 쓰레드가 커넥션 풀에 커넥션을 10개 채움
[MyPool connection adder] MyPool - Added connection conn0: url=jdbc:h2:.. user=SA
[MyPool connection adder] MyPool - Added connection conn1: url=jdbc:h2:.. user=SA
[MyPool connection adder] MyPool - Added connection conn2: url=jdbc:h2:.. user=SA
[MyPool connection adder] MyPool - Added connection conn3: url=jdbc:h2:.. user=SA
[MyPool connection adder] MyPool - Added connection conn4: url=jdbc:h2:.. user=SA
...
[MyPool connection adder] MyPool - Added connection conn9: url=jdbc:h2:.. user=SA
#커넥션 풀에서 커넥션 획득1
ConnectionTest - connection=HikariProxyConnection@446445803 wrapping conn0: url=jdbc:h2:tcp://localhost/~/test user=SA, class=class com.zaxxer.hikari.pool.HikariProxyConnection
#커넥션 풀에서 커넥션 획득2
ConnectionTest - connection=HikariProxyConnection@832292933 wrapping conn1: url=jdbc:h2:tcp://localhost/~/test user=SA, class=class com.zaxxer.hikari.pool.HikariProxyConnection
MyPool - After adding stats (total=10, active=2, idle=8, waiting=0)HikariConfig
HikariCP 관련 설정을 확인할 수 있다. 풀의 이름( MyPool )과 최대 풀 수( 10 )을 확인할 수 있다.
MyPool connection adder
별도의 쓰레드를 사용해서 커넥션 풀에 커넥션을 채우고 있는 것을 확인할 수 있다. 이 쓰레드는 커넥션 풀에 커넥션을 최대 풀 수( 10 )까지 채운다.
왜 별도의 쓰레드를 사용해서 커넥션 풀에 커넥션을 채우는 것일까?
=> 애플리케이션 실행 시간에 영향을 주지 않기 위해.
커넥션 풀에 커넥션을 채우는 것은 상대적으로 오래 걸리는 일이다. 애플리케이션을 실행할 때 커넥션 풀을 채울 때까지 마냥 대기하고 있다면 애플리케이션 실행 시간이 늦어진다. 따라서 별도의 쓰레드를 사용해서 커넥션 풀을 채워야 애플리케이션 실행 시간에 영향을 주지 않는다.
커넥션 풀에서 커넥션 획득
커넥션 풀에서 커넥션을 획득하고 그 결과를 출력했다. 여기서는 커넥션 풀에서 커넥션을 2개 획득하고 반환하지는 않았다. 따라서 풀에 있는 10개의 커넥션 중에 2개를 가지고 있는 상태이다. 그래서 마지막 로그를 보면 사용중인 커넥션 active=2 , 풀에서 대기 상태인 커넥션 idle=8 을 확인할 수 있다. MyPool - After adding stats (total=10, active=2, idle=8, waiting=0)
/**
* JDBC - DataSource 사용, JdbcUtils 사용 */
@Slf4j
public class MemberRepositoryV1 {
private final DataSource dataSource;
public MemberRepositoryV1(DataSource dataSource) {
this.dataSource = dataSource;
}
//save()...
//findById()...
//update()....
//delete()....
private void close(Connection con, Statement stmt, ResultSet rs) {
JdbcUtils.closeResultSet(rs);
JdbcUtils.closeStatement(stmt);
JdbcUtils.closeConnection(con);
}
private Connection getConnection() throws SQLException {
Connection con = dataSource.getConnection();
log.info("get connection={}, class={}", con, con.getClass());
return con;
}
}DataSource의존관계 주입- 외부에서
DataSource를 주입 받아서 사용한다. 이제 직접 만든 DBConnectionUtil을 사용하지 않아도 된다. DataSource는 표준 인터페이스이기 때문에DriverManagerDataSource에서HikariDataSource로 변경되어도 해당 코드를 변경하지 않아도 된다.(DataSource를 구현하고 있기 때문.)
- 외부에서
JdbcUtils편의 메서드- 스프링은 JDBC를 편리하게 다룰 수 있는
JdbcUtils라는 편의 메서드를 제공한다. JdbcUtils을 사용하면 커넥션을 좀 더 편리하게 닫을 수 있다.
- 스프링은 JDBC를 편리하게 다룰 수 있는
@Slf4j
class MemberRepositoryV1Test {
MemberRepositoryV1 repository;
@BeforeEach //각 테스트가 호출되기 직전에 실행됨
void beforeEach() {
//기본 DriverManager - 항상 새로운 커넥션을 획득
// DriverManagerDataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
//커넥션 풀링
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
repository = new MemberRepositoryV1(dataSource);
}
@Test
void crud() throws SQLException {
//save
Member memberV0 = new Member("memberV100", 10000);
repository.save(memberV0);
//findById
Member findMember = repository.findById(memberV0.getMemberId());
log.info("findMember={}", findMember);
Assertions.assertThat(findMember).isEqualTo(memberV0);
//update : money 10000 -> 20000
repository.update(memberV0.getMemberId(), 20000);
Member updatedMember = repository.findById(memberV0.getMemberId());
Assertions.assertThat(updatedMember.getMoney()).isEqualTo(20000);
//delete
repository.delete(memberV0.getMemberId());
Assertions.assertThatThrownBy(() -> repository.findById(memberV0.getMemberId()))
.isInstanceOf(NoSuchElementException.class);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}MemberRepositoryV1은DataSource의존관계 주입이 필요하다.
DriverManagerDataSource 사용
// 실행 결과
get connection=conn0: url=jdbc:h2:.. user=SA class=class
org.h2.jdbc.JdbcConnection
get connection=conn1: url=jdbc:h2:.. user=SA class=class
org.h2.jdbc.JdbcConnection
get connection=conn2: url=jdbc:h2:.. user=SA class=class
org.h2.jdbc.JdbcConnection
get connection=conn3: url=jdbc:h2:.. user=SA class=class
org.h2.jdbc.JdbcConnection
get connection=conn4: url=jdbc:h2:.. user=SA class=class
org.h2.jdbc.JdbcConnection
get connection=conn5: url=jdbc:h2:.. user=SA class=class
org.h2.jdbc.JdbcConnectionDriverManagerDataSource 를 사용하면 conn0~5 번호를 통해서 항상 새로운 커넥션이 생성되어서 사용 되는 것을 확인할 수 있다.
HikariDataSource 사용
get connection=HikariProxyConnection@xxxxxxxx1 wrapping conn0: url=jdbc:h2:...
user=SA
get connection=HikariProxyConnection@xxxxxxxx2 wrapping conn0: url=jdbc:h2:...
user=SA
get connection=HikariProxyConnection@xxxxxxxx3 wrapping conn0: url=jdbc:h2:...
user=SA
get connection=HikariProxyConnection@xxxxxxxx4 wrapping conn0: url=jdbc:h2:...
user=SA
get connection=HikariProxyConnection@xxxxxxxx5 wrapping conn0: url=jdbc:h2:...
user=SA
get connection=HikariProxyConnection@xxxxxxxx6 wrapping conn0: url=jdbc:h2:...
user=SA- 커넥션 풀 사용시
conn0커넥션이 재사용 된 것을 확인할 수 있다. - 테스트는 순서대로 실행되기 때문에 커넥션을 사용하고 다시 돌려주는 것을 반복한다. 따라서
conn0만 사용된다. - 웹 애플리케이션에 동시에 여러 요청이 들어오면 여러 쓰레드에서 커넥션 풀의 커넥션을 다양하게 가져가는 상황을 확인할 수 있다.
DI
DriverManagerDataSource를 HikariDataSource 로 변경해도 MemberRepositoryV1 의 코드는 전혀 변경하지 않아도 된다. MemberRepositoryV1 는 DataSource 인터페이스에만 의존하기 때문이다. 이것이 DataSource 를 사용하는 장점이다.(DI + OCP)
