개요
회사내에서 크롬 기반 자동화 에이전트에 대한 개발 소요가 발생하였고 이에 headless chrome인 puppeteer와 AWS의 ECS(정확히는 ECS TASK), ECR을 사용하여 event driven 기반의 나름 효율적인 에이전트를 개발하게 되어 개발 사항을 정리하고자 해당 글을 작성하게 되었다
아키텍처에 대한 고민
사실 개발소요가 생긴 후 처음에 생각 하였던 아키텍처는 master slave 구조 였고, master와 slave 모두 EC2를 통해 24시간 띄워져 있는 형태로 가닥을 잡고 개발을 진행하려 하였다(master는 작업을 전반적으로 조율하고, slave는 비지니스 로직만을 처리). 하지만 전반적인 기능 요구사항에 대해서 파악해본 결과 해당 구조는 생각보다 비효율적인 방식이였다
- 첫째: 작업이 발생하는 빈도는 높지 않다
- 즉, 유휴 상태인 경우가 많으며 이는 곧 리소스 낭비로 이어진다(비용 또한 발생한다)
- 둘째: 마스터 서버가 뻗어 버릴 경우 최악의 경우 다수의 작업들에 영향을 미친다
따라서 해당 방식보다는 event driven 구조로 작업이 필요로 할때 뜨며 작업 별로 독립성을 가지는 아키텍처를 고민하기 시작 하였고 ECR, ECS를 선택하여 아키텍처를 설계하게 되었다.
아키텍처
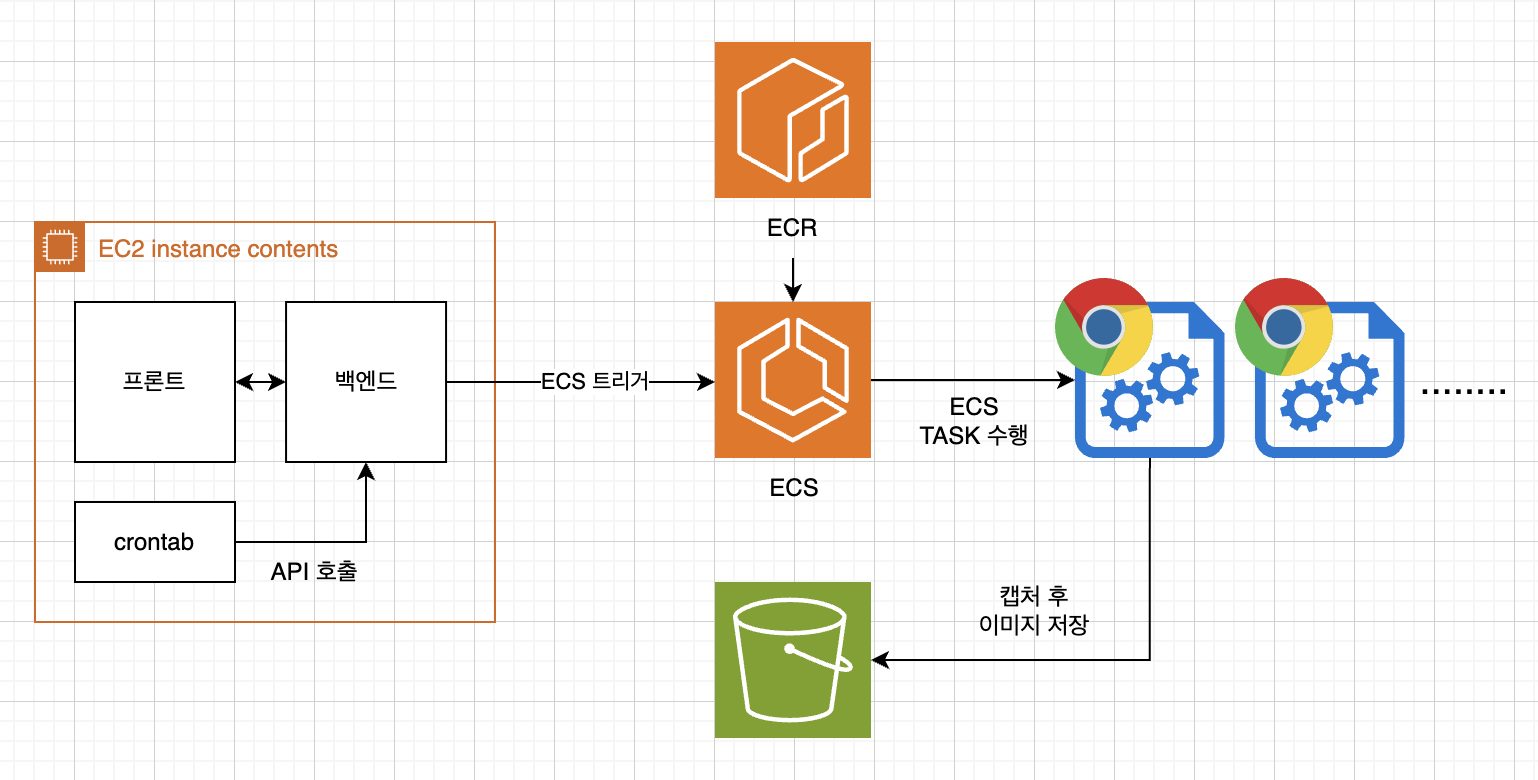
시스템의 개략적인 아키텍처는 위의 사진과 같다
- crontab에서 주기적으로 API를 호출한다
- crontab은 배치 처리를 위해서 도입, 즉 한개의 작업을 하나의 ECS TASK로 가져가기 보다 하나의 ECS TASK가 여러개의 작업을 긁어가서 실행 시키는 구조이다
- API가 호출되면 백엔드(strapi로 구성)에서 AWS SDK를 통해 ECS TASK를 실행 시킨다(ECS RUNTASK)
- 권한문제는 EC2에 IAM role을 부여하여 해결 하였다
- 작업이 완료되면 결과물인 캡처 이미지(사진)를 S3에 저장한다(SDK를 사용하여)
에이전트(puppeteer)
puppeteer와 선택 이유
puppeteer는 테스트 자동화, spa 크롤링등 브라우저를 제어할 수 있으며 headless 기능 또한 제공하는 node.js 라이브러리이다. 물론 headless tool에는 selenium등 여러가지가 존재하지만 내가 puppeteer를 선택한 이유는 다음과 같다
- google에서 지속적으로 관리하는 라이브러이다(이러한 안정성이 선택에 가장 큰 이유중 하나이다)
- 오픈소스이고, 다양한 기능을 제공하며 사용하기 어렵지 않다
- github star도 85.1k이며 관련 레퍼런스가 많다
간단한 사용 방법
비지니스로직의 경우 노출하기 힘드므로 간단한 사용 방법에 대해서 정리하고자 한다.
const browser = await pptr.launch({
headless: false, // false일 경우 headful 모드로 실행 된다
});
먼저 다음과 같이 puppeteer를 실행 시킬 수 있다. 이때 launch 함수는 browser를 return 하게 되는데 browser를 통해 page에 접근해야 한다
const [page] = await browser.pages(); // 기본으로 browser가 생성될때 페이지 하나를 생성한다
const newPage = await browser.newPage(); // 새로운 페이지를 만드려면 newPage 메서드를 활용하면 된다이렇게 page에 접근하게되면 페이지 별로 user agent 및 viewport등을 설정 할 수 있다
await page.setViewport({ width: 1920, height: 1080 }); // 뷰포트 설정
// user agent 설정
await page.setUserAgent("Mozilla/5.0 (iPhone; CPU iPhone OS 16_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/114.0.5735.99 Mobile/15E148 Safari/604.1";)이후 page를 통해서 이동 및 캡처등등 여러가지 작업을 진행할 수 있으며, 이 중 몇가지 작업들만 정리하고자 한다
페이지 이동
어떤 링크 버튼등 클릭을 통해서 페이지를 navigation 할때 클릭 작업 후 페이지 이동간 다음 코드에서 에러가 발생할 수 있다(예를 들어 페이지 이동중 특정 element에 접근하려고 한다고 가정 해보자). 즉 네비게이션이 끝나고 다음 코드가 실행이 되어야 이러한 문제를 해결 할 수 있으며 따라서 다음과 같이 코드를 작성해야 한다
await Promise.all([
page.waitForNavigation(),
page.click('a.my-link'),
]);그 다음으로 페이지 이동시 wait에 관한 옵션이다
- load: load 이벤트 발생까지 대기한다
- domcontentloaded: DOMContentLoaded 이벤트 발생때까지 대기한다
- networkidle0: 최소 500ms간 네트워크 호출이 0이 될때 까지 대기한다
- networkidel2: 최소 500ms간 네트워크 호출이 2보다 크지 않을때 까지 대기한다
여기서 대기는 페이지 전환이나 이동이 대기한다는 의미는 아니며 promise가 해당 옵션의 조건을 만족하기 전까지 resolve 되지 않는 다는 것을 의미한다. (다만 puppeteer가 해당 조건을 만족할때 까지 무한정 대기하는 것은 아니다, timeout시간(기본 30초) 까지 대기하다 이후에도 충족되지 않으면 timeout 에러를 발생 시킨다)
따라서 예시로 짠다면 다음과 같은 코드로 짤수 있을 것이다
try {
await page.goto("https://my-destination.com", { waitUntil: "networkidel2" });
} catch(e) {
// timeout에러, 즉 navigation 실패시 수행할 로직
}DOM에 접근하기
DOM에 접근하는 방법에 대해서는 2가지 정도에 대해서 정리하고자 한다
첫째 방법은 $와 evaluate를 활용하는 방법이다
const handler = await page.$("div.some-class-name");
const someText = await page.evaluate((el) => el.textContent, handler);(typescript 활용시 class 선택자만 사용하는 것 보다 위처럼 html element 이름을 명시해주면 type 추론이 되기 때문에 위와 같은 방법을 추천한다)
둘째 방법은 축약형 방법이다
const someText = await page.$eval("div.some-class-name", (el) => el.textContent);여기서 주의할점은 evaluate($eval) 함수내의 콜백 함수의 컨텍스트, 즉 환경이 브라우저라는 점이다. 기본적으로 puppeteer가 실행되는 환경은 node이기 때문에 서로 다름으로 주의할 필요가 있다
const ary = []; // node 환경
await page.$eval("p.selector", (el) => {
// 브라우저 환경
console.log(ary); // undefined
ary.push(el.textContent); // uncaught typeerror 발생(ary는 undefined)
});만약 리스트(querySelectorAll)를 가져오고 싶다면, $$ 키워드를 활용하면 된다
await page.$$eval("li.blah", (els) => {
// 필요한 로직.... els는 li list
});개략적인 정리 포인트는 다음과 같고, 다른 사항은 공식문서를 참고하면 된다(물론 친절한 문서는 아니다)
향후 다룰 내용
다음으로는 puppeteer dockerlizing(mac 환경에서, 생각보다 우여곡절을 겪었다), ECR과 ECS 구성(cluster 구성 및 task defintion)에 대해서 다룰 예정이다
