: 매우 단순한 데이터 파이프라인 패턴 (이 구조에서 응용이 되어 다양한 파이프라인이 생성된다.)
추출 방식
전체 추출 : 원본 데이터 소스에서 추출 작업을 실행할 때마다 전체 데이터를 (레코드의 모든 테이블) 읽어와서, 데이터 웨어하우스에 저장 (원본 데이터를 대체하거나 갱신)
| OrderID | OrderStatus | LastUpdated |
|---|---|---|
| 1 | BackOrdered | 2020-06-01 12:00:00 |
증분 추출 : 추출작업을 할 때마다 데이터의 변경사항만을, 즉 변경하거나 추가된 원본 테이블의 레코드만 추출
| OrderID | OrderStatus | LastUpdated |
|---|---|---|
| 1 | BackOrdered | 2020-06-01 12:00:00 |
| 1 | Shipped | 2020-06-09 12:00:25 |
: 대부분의 경우에는 증분 추출을 사용하는데, 전체 추출과 관련하여 몇 가지 이점이 있기 때문이다.
- 전체 데이터를 대체할 필요가 없어, 실시간 스트리밍 데이터 처리에 유리하다.
- 성능 면에서 전체 추출보다 우세하다.
- 후에 설명할 이진 추출의 경우, 증분 추출 방식을 채용한다. (변경 사항 추출)
각 DB 종류별 추출
: 위 책에서 실습하는 내용은 각 프레임워크별 (MySQL, PostgreSQL, REST API 등) 데이터베이스에서 데이터를 추출한 후, S3 버킷에 적재하는 방식이다.
MySQL (PostgreSQL도 매우 유사함)
: 전체 추출과 증분 추출의 방식이 다르다.
전체 추출
import pymysql
import csv
import boto3
import configparser
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
hostname = parser.get("mysql_config", "hostname")
port = parser.get("mysql_config", "port")
username = parser.get("mysql_config", "username")
dbname = parser.get("mysql_config", "database")
password = parser.get("mysql_config", "password")
conn = pymysql.connect(host=hostname,
user=username,
password=password,
db=dbname,
port=int(port))
if conn is None:
print("Error connecting to the MySQL database")
else:
print("MySQL connection established!")
m_query = "SELECT * FROM Orders;"
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query)
results = m_cursor.fetchall()
with open(local_filename, 'w') as fp:
csv_w = csv.writer(fp, delimiter='|')
csv_w.writerows(results)
fp.close()
m_cursor.close()
conn.close()
# load the aws_boto_credentials values
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
access_key = parser.get("aws_boto_credentials", "access_key")
secret_key = parser.get("aws_boto_credentials", "secret_key")
bucket_name = parser.get("aws_boto_credentials", "bucket_name")
s3 = boto3.client('s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(local_filename, bucket_name, s3_file)- ConfigParser로 pipeline 설정사항을 읽어온다. (pipeline.conf)
parser = configparser.ConfigParser()
parser.read("pipeline.conf") # MySQL 서버와 연결하기 위한 Configuration 설정
hostname = parser.get("mysql_config", "hostname")
port = parser.get("mysql_config", "port")
username = parser.get("mysql_config", "username")
dbname = parser.get("mysql_config", "database")
password = parser.get("mysql_config", "password")⇒ pymysql을 통해 mysql과 연결 과정에서 필요한 정보들을 읽어온다.
- Query문을 실행하여 데이터를 읽어온다.
m_query = "SELECT * FROM Orders;" #전체 추출 쿼리문
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query)
results = m_cursor.fetchall()
with open(local_filename, 'w') as fp:
csv_w = csv.writer(fp, delimiter='|') # '|' 로 열 구분
csv_w.writerows(results)⇒ .csv 파일에 읽어온 데이터들을 구분자 (’|’) 들을 통해 열을 구분하고 로드한다.
- .csv 파일을 (데이터) S3 버킷에 로드한다.
parser = configparser.ConfigParser() #AWS의 S3 버킷과 연결하기 위해 설정
parser.read("pipeline.conf")
access_key = parser.get("aws_boto_credentials", "access_key")
secret_key = parser.get("aws_boto_credentials", "secret_key")
bucket_name = parser.get("aws_boto_credentials", "bucket_name")
s3 = boto3.client('s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(local_filename, bucket_name, s3_file)증분 추출
import pymysql
import csv
import boto3
import configparser
import psycopg2
# get db Redshift connection info
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
dbname = parser.get("aws_creds", "database")
user = parser.get("aws_creds", "username")
password = parser.get("aws_creds", "password")
host = parser.get("aws_creds", "host")
port = parser.get("aws_creds", "port")
# connect to the redshift cluster
rs_conn = psycopg2.connect(
"dbname=" + dbname
+ " user=" + user
+ " password=" + password
+ " host=" + host
+ " port=" + port)
rs_sql = """SELECT COALESCE(MAX(LastUpdated), '1900-01-01')
FROM Orders;"""
rs_cursor = rs_conn.cursor()
rs_cursor.execute(rs_sql)
result = rs_cursor.fetchone()
# there's only one row and column returned
last_updated_warehouse = result[0]
rs_cursor.close()
rs_conn.commit()
# get the MySQL connection info and connect
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
hostname = parser.get("mysql_config", "hostname")
port = parser.get("mysql_config", "port")
username = parser.get("mysql_config", "username")
dbname = parser.get("mysql_config", "database")
password = parser.get("mysql_config", "password")
conn = pymysql.connect(host=hostname,
user=username,
password=password,
db=dbname,
port=int(port))
if conn is None:
print("Error connecting to the MySQL database")
else:
print("MySQL connection established!")
m_query = """SELECT *
FROM Orders
WHERE LastUpdated > %s;"""
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query, (last_updated_warehouse,))
results = m_cursor.fetchall()
with open(local_filename, 'w') as fp:
csv_w = csv.writer(fp, delimiter='|')
csv_w.writerows(results)
fp.close()
m_cursor.close()
conn.close()
# load the aws_boto_credentials values
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
access_key = parser.get(
"aws_boto_credentials",
"access_key")
secret_key = parser.get(
"aws_boto_credentials",
"secret_key")
bucket_name = parser.get(
"aws_boto_credentials",
"bucket_name")
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(
local_filename,
bucket_name,
s3_file)- 변경된 사항만을 저장하므로 가장 마지막으로 업데이트 된 시점으로 부터의 변경사항을 포착하여 데이터 웨어하우스에 적재한다.
rs_sql = """SELECT COALESCE(MAX(LastUpdated), '1900-01-01')
FROM Orders;""" # 데이터 웨어하우스에 가장 마지막으로 데이터가 적재된 시점을 불러온다.
# 이 시점 이후의 변경사항들을 불러와야 하기 때문.
rs_cursor = rs_conn.cursor()
rs_cursor.execute(rs_sql)
result = rs_cursor.fetchone()
#가장 최근 시점만 불러오므로, 한 개의 행만이 반환된다.
last_updated_warehouse = result[0]
rs_cursor.close()
rs_conn.commit()
...
m_query = """SELECT *
FROM Orders
WHERE LastUpdated > %s;"""
m_cursor = conn.cursor()
m_cursor.execute(m_query, (last_updated_warehouse,)) # 최근 시점 이후의 데이터들을 불러온다.
results = m_cursor.fetchall()⇒ 위의 rs_sql 쿼리문은 데이터 웨어하우스에 데이터가 마지막으로 적재된 시점을 가져온다. 그 후, 그 시점 이후로의 데이터들을 원본 데이터베이스에서 불러와 (mysql 데이터베이스에 변경사항이 있다고 가정) 변경 사항들을 가져온다.
- 변경 사항들을 S3 버킷에 적재한다.
with open(local_filename, 'w') as fp:
csv_w = csv.writer(fp, delimiter='|')
csv_w.writerows(results)
fp.close()
m_cursor.close()
conn.close()
...
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(
local_filename,
bucket_name,
s3_file)⇒ 변경 사항들을 .csv로 만든 다음, S3 버킷에 적재한다.
💡 이 과정을 요약하면, 데이터 웨어하우스를 최신화하는 것이 목적이므로, 데이터 웨어하우스의 마지막 변경시점 이후의 모든 변경사항을 추출하여 S3 버킷에 적재하는 것이다.REST API
: API의 엔드포인트에서 JSON 형식의 데이터들을 로드한 후, 데이터 웨어하우스에 적재하는 방식이다. (흔한 방식)
import requests
import json
import configparser
import csv
import boto3
lat = 42.36
lon = 71.05
lat_log_params = {"lat": lat, "lon": lon}
api_response = requests.get(
"http://api.open-notify.org/astros.json", params=lat_log_params
)
requests_json = json.loads(api_response.content)
all_passes = []
for response in requests_json['people']:
current_pass = []
current_pass.append(lat)
current_pass.append(lon)
current_pass.append(response['name'])
current_pass.append(response['craft'])
all_passes.append(current_pass)
export_file = "export_file.csv"
with open(export_file, 'w') as fp:
csvw = csv.writer(fp, delimiter = '|')
csvw.writerows(all_passes)
fp.close()
parser = configparser.ConfigParser()
parser.read('../pipeline.conf')
access_key = parser.get("aws_boto_credentials", "access_key")
secret_key = parser.get("aws_boto_credentials", "secret_key")
bucket_name = parser.get("aws_boto_credentials", "bucket_name")
s3 = boto3.client('s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key)
s3.upload_file(export_file, bucket_name, export_file)- API에서 요구하는 파라미터들을 적절히 기입한 다음, get을 통해 데이터를 수신한다.
lat = 42.36
lon = 71.05
lat_log_params = {"lat": lat, "lon": lon} # API GET을 위한 Parameter 설정
api_response = requests.get(
"http://api.open-notify.org/astros.json", params=lat_log_params
)
requests_json = json.loads(api_response.content) #response를 통해 요청한 후, json을 받아온다.- 원하는 형식으로 데이터들을 추출한 후에 .csv에 저장한다.
all_passes = [] # .csv의 한 행에 넣을 행 데이터 배열
for response in requests_json['people']: #페이지의 json 파싱
current_pass = []
current_pass.append(lat)
current_pass.append(lon)
current_pass.append(response['name']) # {name : ~~}
current_pass.append(response['craft']) #{craft : ~~}
all_passes.append(current_pass)
export_file = "export_file.csv"
with open(export_file, 'w') as fp:
csvw = csv.writer(fp, delimiter = '|') # 열 구분
csvw.writerows(all_passes)
fp.close()- 여기서는 api.open-notify.org의 공식 API를 사용하므로, 해당 JSON을 알맞게 파싱한 후에 .csv에 적재하고, S3 버킷에 로드한다.
Kafka 및 Debezium (Kafka 스트리밍을 이용한 CDC) 을 통한 스트리밍 데이터 수집
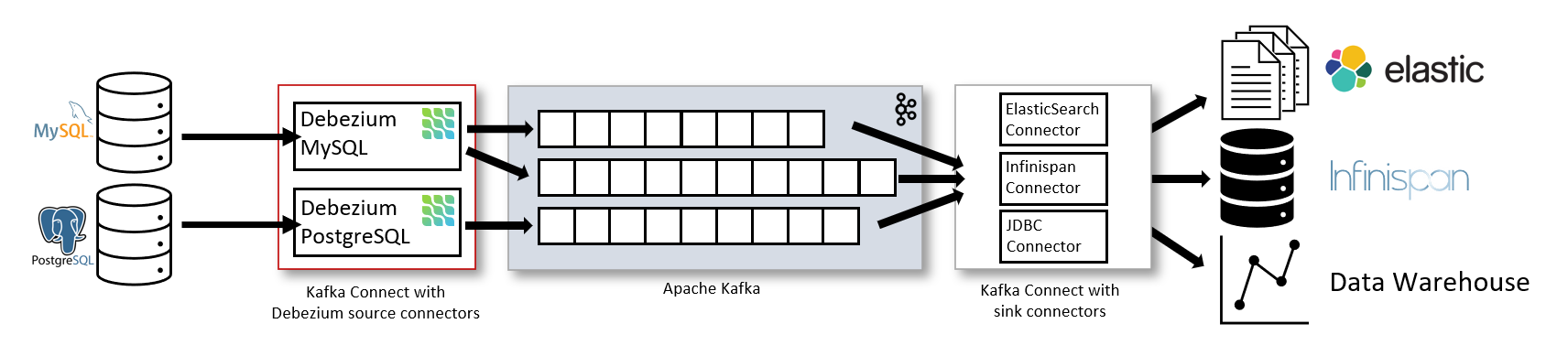
: Kafka의 실시간 스트리밍 데이터 수집을 이용한 CDC 구조
수집 및 적재 과정
- Apache Kafka Connect에서 트랜잭션 로그를 모니터링하며 데이터의 변화를 감지한다.
- 데이터의 변화가 감지될 경우, Apache Kafka Connect는 이를 Kafka의 토픽으로 변환하여 전송한다.
- Kafka 토픽에 변경사항들이 저장되므로, 토픽에서 이를 증분 추출하여 다시 Apache Kafka Connect를 통해 데이터 웨어하우스에 적재하게 된다.
- 보통 Kafka에는 Producer(생산자), Consumer(소비자)로 나뉘어져 있는데, 데이터 웨어하우스가 Consumer 역할을 한다.
