NoSQL
- SQL, RDBMS(관계형 데이터베이스)의 반대
- 관계형 데이터베이스는 정규화를 통해서 중복 데이터를 최대한 줄이는 것이 중요했었음 (스토리지 비용이 비쌌었기 때문에)
- 점차 스토리지 비용이 저렴해지고, 대규모 연산을 빠르게 처리해 내는게 중요해지면서 데이터가 중복되도 좋으니 빠르게 처리하는 것이 중요한 시대가 되었음
- 즉, 스토리지를 희생하더라도 성능을 최대한 끌어올리는 NoSQL이 나옴
- ex. MongoDB, DynamoDB
DynamoDB
- NoSQL 데이터 베이스
- Connectionless
다른 DB Resource들이 TCP Connection 기반에 비해 DynamoDB는 HTTP로 통신을 한다 - Serverless
별도의 서버가 존재하지 않고, 요청한 만큼 비용을 지불하면 된다.
scale-in/out이 용이하다. (AWS Lamda, AppSync 와 잘 맞음) - Key-Value 데이터베이스
key를 제외한 테이블의 Attribute들은 미리 정의될 필요없음.
따라서 유연한 데이터 처리가 가능하다. - key의 구성 방법
5-1. Simple Primary Key
Partition Key 하나만을 Primary Key로 쓰는 것
5-2. Composite Primary Key
Partition Key와 Sort Key의 조홥으로 Primary Key를 쓰는것⭐ 어떤 상황에서 엑세스 하는지 Use Case 를 잘 생각해보고 키를 결정해야함
Handling
1. Item-based actions
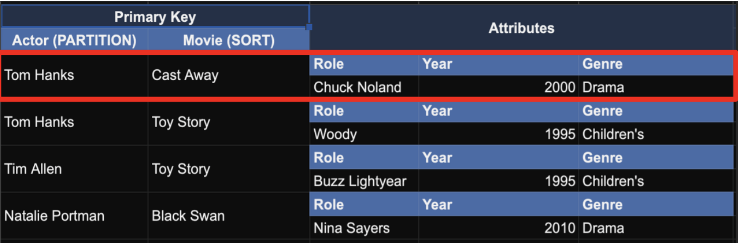
- DynamoDB에서 Item은 관계형 데이터베이스로 치면 Row에 해당하는 것
- Item-based actions에는 Write, Delete, Update 가 가능
- Item을 대상으로 처리하는 것이기 때문에 Primary Key를 제공해야함
- 한번에 여러개 처리가 불가함 (batch request는 안됨)
ex. "톰 행크스가 출연한 모든 영화 삭제해줘" 와 같은 요청은 불가능함 (아이템 하나하나 처리해 줘야함)
2. Query
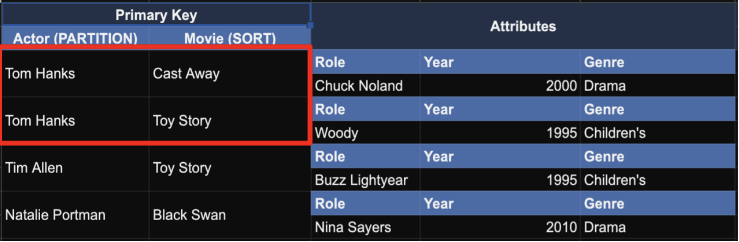
- 데이터를 읽기 위한 액션이며, Read-only action임
- 한번의 요청으로 여러 개의 아이템들을 처리(fetch) 할 수 있다
- "톰 행크스가 출연한 모든 영화 가져와줘" 와 같은 요청이 가능함
- Partition Key를 제공하는 것이 기본인데, 필요에 따라 Sort Key에다가 세부 조건을 적용할 수 있음
ex. "톰 행크스의 영화 중에, 알파벳a~c안에 드는 글자로 시작하는 영화만 가져와줘" 와 같이 요청 할 수 있음
3. Scan
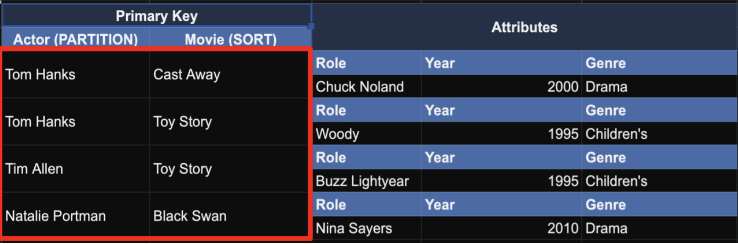
- 관계형 데이터 베이스의 스캔과 동일한 기능
- 모든 아이템을 다 보기때문에 비용이 많이 듦으로, 사용 하지 않는 것이 좋음
Secondary Indexes
- 기존 디자인으로 Primary Key(Partition Key only or Partition Key + Sort Key)를 이용해 두 가지 액세스 패턴은 만족 시킬 수 있으나, 추가적인 액세스 패턴을 만족시키지 못할 것 이다
- 전체 스캔해서 필터링 한다면 성능이 테이블 사이즈가 커질수록 안좋아 질 것
- 이때 사용할 수 있는 것이 Secondary Index이다.
ex. "Toy Story 에 출영한 배우들을 보여줘" 라는 엑세스 패턴이 추가 될 때 현재 Query를 통해 갖울 수 이는 방법은 없음
✍ Global Secondary Index(GSI)를 적용하여 Sort Key 내용을 GSI의 Partition Key로 하고, Partition Key 내용을 GSI의 Sortk Key로 하나면, Query를 통해 Toy Story에 출영한 배우가 누군지 알 수 있게됨
✍ Secondary Index를 적용하면, 그 형태에 맞는 Primary Key의 새로운 테이블이 내부적으로 생긴것과 같음
Modeling
1. Start with an ERD
Entity 들의 관계를 그려야 함. 1:1인지 N:M인지.
2. Define your access patterns
어떤 데이터를 읽을 것인지 정의해야함.
ex. "톰 행크스의 모든 영화를 가져와줘", "Toy Story에 출연한 배우들을 보여줘"
3. Design your primary keys & secondary indexes
1, 2 에서 도출한 내용으로 Write / Delete / Modify에 대한 처리가 가능하면서도, Scan이 아닌 Query로 데이터를 얻고 필터링 할 수 있도록 Key를 디자인 해야함.
📝Practice
1) 애플리케이션은 E-commerce 서비스이다.
2) 사용자들이 주문을 할 수 있다.
3) 하나의 주문은 여러개의 아이템을 가질 수 있다.
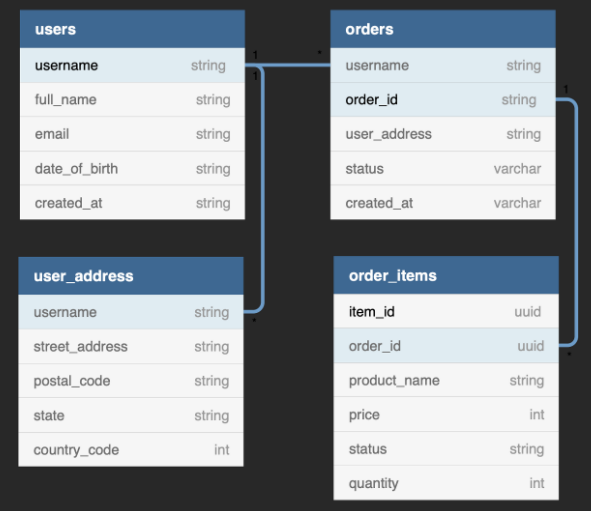
1. Start with an ERD
- User:User Address = 1:N
- User:Order = 1:N
- Order:Item = 1:N
2. Design your access pattern
사용자의 프로필을 가져온다.사용자의 모든주문을 가져온다.- 하나의
주문과 그 주문의아이템들을 가져온다. - 한
사용자의 특정 상태의주문을 가져온다. 사용자의 새로운주문을 가져온다.
3. Design your primary keys & secondary indexes
- 1:1 관계와 1:N 관계를 나누어서 표현하자.
- 1:1 관계

사용자의 프로필은사용자에 종속적인 개념으로 사용자가 Partition Key(PK), 프로파일이 Sort Key (SK) 관계로 표현 될 수 있음. 이때 각 Key 앞에"USER#","PROFILE#"와 같은식으로 어떤 내용의 key인지 Prefix를 붙이면 디버깅하기 용이할 뿐 아니라 값이 중복될 가능성을 낮출 수 있음 - 1:N 관계
다음과 같이 3가지 방법으로 1:N 관계 표현이 가능함
(1) Attribute (list or map)
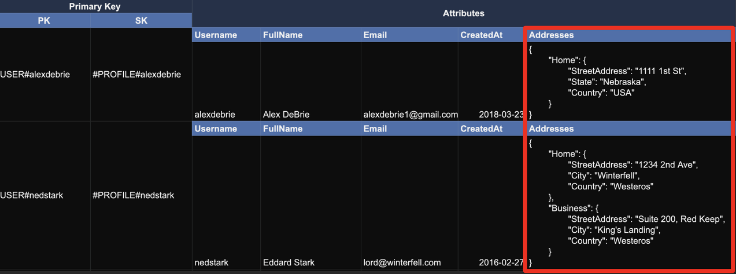
사용자와사용자 주소의 관계에서사용자 주소를 직접 접근할 일 이 없다. 또한 정책적인 이유로 주소 개수에 제한을 둘 수도 있다. 이런것들을 고려했을 때, list나 map을 활용한 de-normalization을 적용 할 수 있다.
(2) Priamry Key + Query
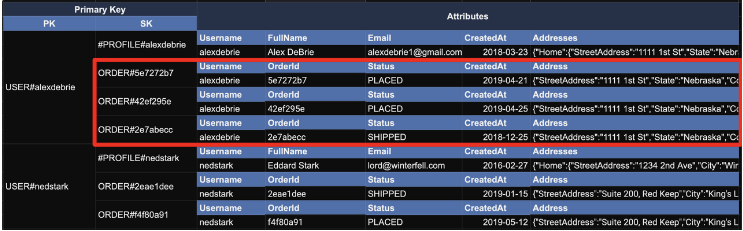
DynamoDB에서 1:N 관계를 나타내는 가장 일반적인 방법인 Sort Key 를 이용하는 것이다.
사용자와 사용자의주문의 관계가 1:N의관계에 있고, 요구조건 상, 사용자의주문의 개수가 제한적이지 않은 상황일 때 Partition Key + Sort Key로 표현할 수 있다.
(❗Order에 해당하는 Attribute를 보면,Profile의 내용과 다르다. 이처럼 DynamoDB는 Attribute들을 Key의 내용에 따라 자유롭게 구성이 가능하다.)
(3) Secondary index + Query
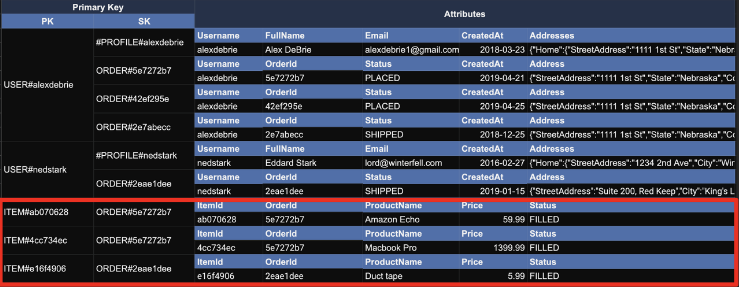
기존의 PK, SK를 이용해서는 Query를 할 수 없을 때 Secondary index를 쓴다.
주문과아이템의 1:N 관계를 표현하기 위해, Secondary index로PK='아이템',SK='주문'을 적용 할 수 있다. (일반적인 접근 방법이라면주문하나에아이템여러개이므로PK='주문',SK='아이템'을 할 것 같지만, 반대로 하게 되면 다음과 같이 서로 다른 Partition Key (User,Item) 이 공통의 Sort Key(Order)를 가질 수 있기 때문이다.)
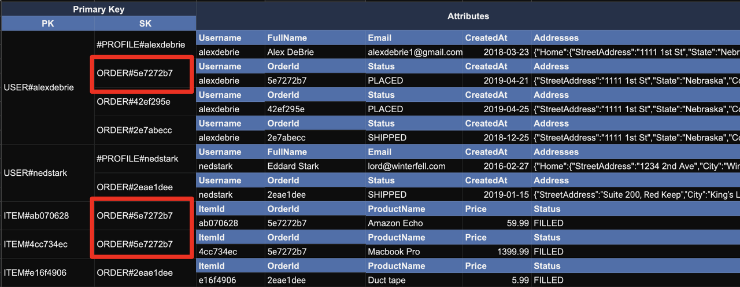
지금의 구조에서 GSI로 SK에 PK를 적용하고, PK에 SK를 적용하면 아래와 같다. (Inverted Index)
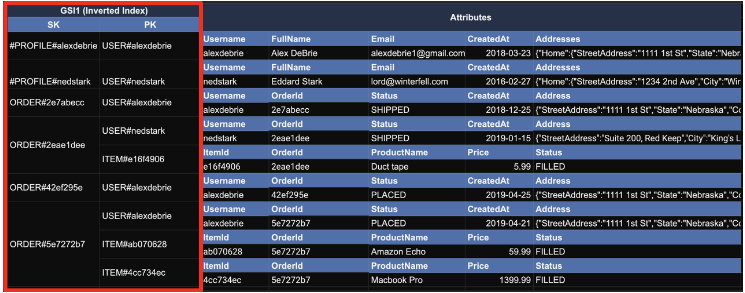
이때 Secondary Index의 PK인주문을 이용해서 Query하면사용자와아이템들이 함께 나온다. 이는 RDBMS에서User-Order테이블과Order-Item테이블을 JOIN한 효과를 낼 수 있다.
즉, DynamoDB에서는 하나의 테이블 안에서 PK, SK, Secondary index를 이용해서 Pre-aggregated된 내용을 JOIN없이 고성능으로 얻을 수 있다.
Filtering
만약 우리가 특정 attribute에 대해서 필터링을 하고 싶을 때 필터링의 대상이 기존의 PK, SK, Secondary Index에 의해 Query로 뽑아낼 수 있는 데이터 이면 문제되지 않을 것이다. 만약 찾고자 하는 대상의 Partition Key가 서로 다르다면..? Scan 후 Filtering 하면 될까? 답은 🙅♀️이다.
DynamoDB의 Filter expression 동작 방식
1. 테이블에서 데이터(아이템 들)을 읽는다. (=Scan)
2. 해당 아이템들을 메모리에 로드하고 나면, DynamoDB는 사용자가 정의한 Filter expression이 있는지 확인한다.
3. 만약에 Filter expression이 있다면, 그 내용에 따라 아이템들을 필터링 한다.
4. Return 한다.
위의 동작 방식에서 문제가 되는 부분은 1번인데, DynamoDB에서 데이터를 한번에 가져올 수 있는 최대 크기는 1MB 이다. 즉, 1GB크기의 테이블을 Scan한다면 요청을 1000번을 보내게 될 것 이다. 때문에 필터링된 데이터를 Primary Key나 Secondary index를 통해 가져올 수 있도록 구성하는 것이 좋다.
필터링된 엑세스 패턴을 Key or Index를 통해 가져오는 방법
1. Primary key
2. Composite sort key
3. Sparse index
1. Primary key
"사용자의 모든 주문(order)을 가져온다."
SELECT * FROM orders WHERE username = 'alexdebrie'
PK='사용자', SK='주문'으로 다음과 같이 필터링 할 수 있다.
"PK=USER#alexdebrie AND BEGINS_WITH(SK, 'ORDER#')"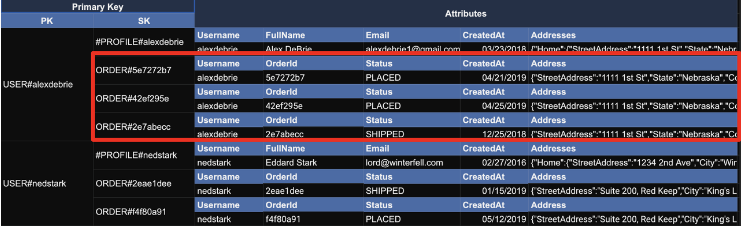
2. Composite sort key
"한 사용자의 특정 상태(status)의 주문을 가져온다."
SELECT * FROM orders WHERE username= 'alexdebrie' AND status='shipped'
현재 테이블을 보면, "status" attribute에 해당하는 내용은 Primary Key나 Secondary index를 통해 직접 접근할 수 없다. 또한 갖오고자 하는 내용이 서로 다른 Partition Key에 속해 있어서 Primary key나 Secondary index를 통해 가져온 데이터에 Filter을 적용하는 것도 불가하다.
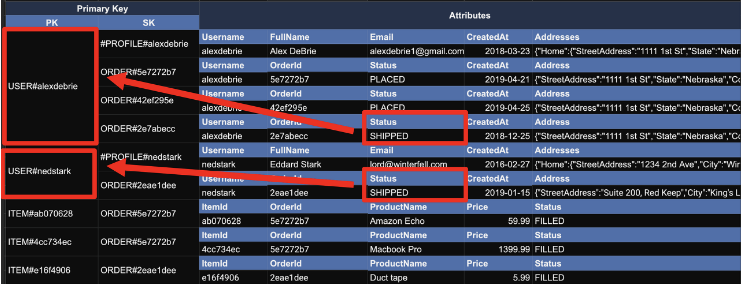
이때 Composite sort key를 다음과 같이 만든다. 기존에 두 개 이상의 attribute를 합치고, 그것을 GSI를 통해 Sort Key로 적용하면 된다.
(1) Status와 CreatedAt를 합쳐서 OrderStatusDate attribute를 추가
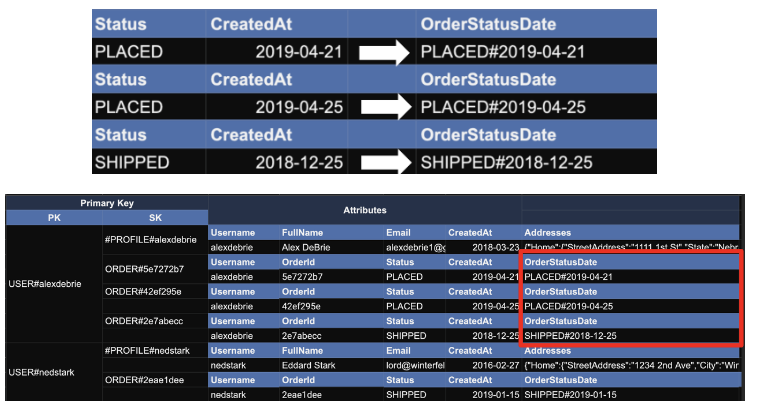
(2) GSI를 이용해, OrderStatusDate를 SK로 적용
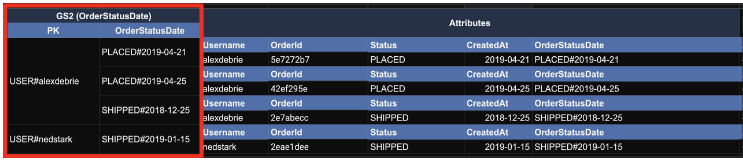
GSI를 통해 PK, SK 구조가 만들어지기 때문에 다음과 같이 Query가 가능해 진다. (CreatedAt 속성도 Composite Key로 만들어지기 때문에 "날짜" 까지 필터링이 가능해진다.)
"PK=USER#alexdebrie AND BEGINS_WITH(OrderStatusDate, 'Shipped#')"3. Sparse index
"사용자의 새로운 주문을 가져온다."
SELECT * FROM orders WHERE status='placed'
이번 패턴은 기존의 PK, SK와 관계없이 특정 attribute값을 기준으로 아이템을 필터링 해서 얻고 싶은 경우이다. 이때는 해당 attribute의 값에 대한 ID를 만들고 그 ID에 대해서 GSI를 적용하면 된다. 이때, Status가 "PLCAED"에 해당하는 아이템은 테이블 전체 중 일부이고, 이것에 대한 Key를 만들기 때문에 Sparse Key라고 한다.
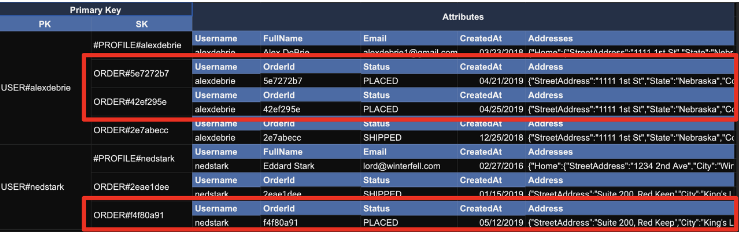
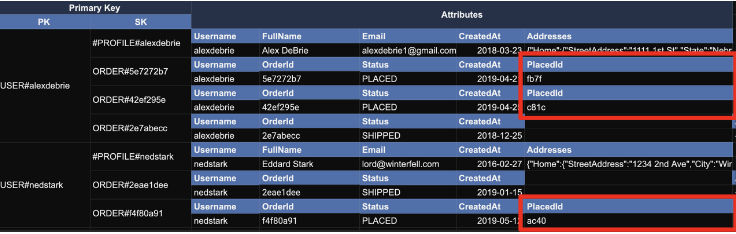
위와 같이 Status가 "PLACED"인 경우만 뽑고 싶다면, PlaceId라는 attribute를 생성하고,
그것이 GSI를 통해 PK로 적용될 수 있도록 Unique한 값을 넣어준다.
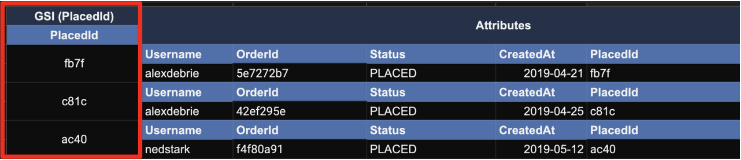
이렇게 만들어진 GSI 테이블은, 원본 테이블의 Subset이며, 특히 "특정 attribute"에 대한 "특정 값"을 대상으로 만들어진 것이기 때문에, 그 사이즈 자체가 크지 않을 것으로 기대할 수 있다. 그래서, 해당 Index를 대상으로 Scan를 수행하는 것도 괜찮다.
🔗참고
https://alphahackerhan.tistory.com/39
https://www.youtube.com/watch?v=DIQVJqiSUkE&feature=youtu.be
