이 포스트는 "밑바닥부터 시작하는 딥러닝2 - 파이썬으로 직접 구현하며 배우는 순환 신경망과 자연어 처리 (한빛미디어, 사이토 고키 지음)" 책을 기반으로 공부해서 정리한 내용이다.
Chapter4: word2vec 속도 개선
4.1 word2vec 개선(1) & 4.2 word2vec 개선(2)
- 앞 장에서 구현한 간단한 word2vec의 CBOW 모델의 문제점: 말뭉치 크기가 많이 크다면 그에 따라 계산량도 굉장히 많아진다 (아래와 같은 예시)
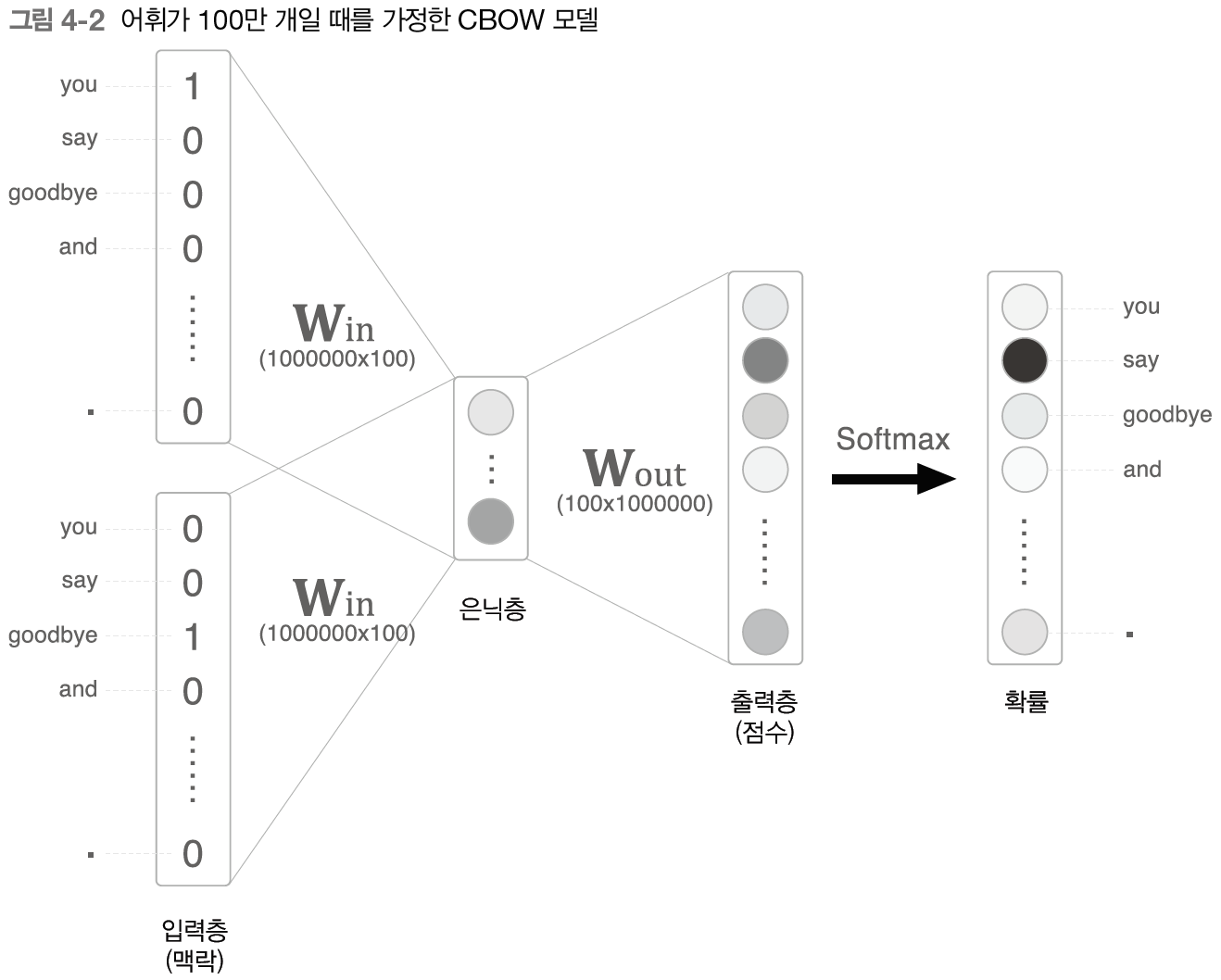
- 입력층의 원핫 표현과 가중치 W_in의 곱 계산 <- Embedding 계층 도입
- 기존의 원핫 표현과 MatMul 계층의 가중치 곱은 결국 가중치 행렬의 특정 행을 추출하는 것

- 사실상 계산이 필요없으므로 가중치 행렬으로부터 단어 id에 해당하는 행을 추출하는 계층인 Embedding 계층을 MatMul 계층 대신 도입
++ 단어의 밀집벡터 표현을 -> 단어 임베딩 or 단어의 분산 표현 (통계기반기법-> distributional representation, 신경망 추론기반기법 -> distributed representation)
- 순전파 & 역전파
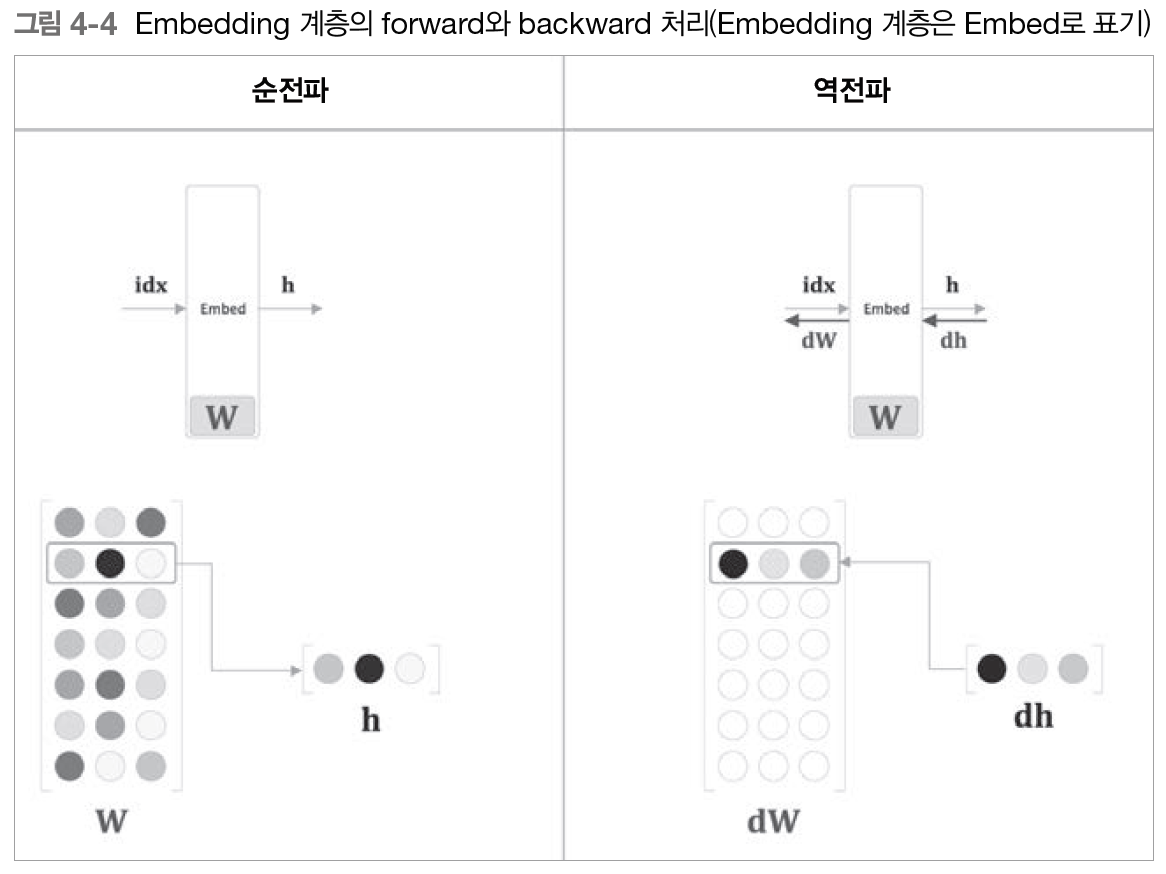 - 미니배치 처리일 때 idx에 중복된 원소가 있을 수 있으므로 역전파시 idx가 가리키는 장소에 할당이 아닌 더하기를 해야 함
- 미니배치 처리일 때 idx에 중복된 원소가 있을 수 있으므로 역전파시 idx가 가리키는 장소에 할당이 아닌 더하기를 해야 함
-> 이렇게 함으로써 메모리 사용량 ⬇️, 계산량도 ⬇️
- 은닉층과 가중치 W_out의 곱 및 softmax 계산 <- Negative Sampling 손실 함수 도입
- softmax 대신 negative sampling 사용하여 말뭉치가 커지더라도 계산량을 낮은 수준에서 일정하게 억제 가능
- 핵심: 다중 분류 -> 이중 분류(출력층 뉴런 하나만 필요)
(ex: "맥락이 'you'와 'goodbye'일 때 타깃 단어는 'say' 입니까?" yes/no)
 - 단어 하나에 대해서만 그 점수를 계산 -> sigmoid 활성화 함수(0~1 사이의 값 출력) -> 확률
- 단어 하나에 대해서만 그 점수를 계산 -> sigmoid 활성화 함수(0~1 사이의 값 출력) -> 확률
++ 다중 분류 경우: softmax, 교차 엔트로피 오차 / 이중 분류 경우: sigmoid, 교차 엔트로피 오차
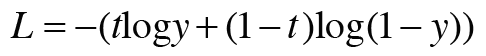 - 정답 레이블 t: 정답이면 1, -logy 출력 / 오답이면 0, -log(1-y) 출력
- 정답 레이블 t: 정답이면 1, -logy 출력 / 오답이면 0, -log(1-y) 출력
 - 역전파의 값 y-t : 정답일 경우 y, 신경망이 출력한 확률이 1(100%)에 가까울수록 오차 감소
- 역전파의 값 y-t : 정답일 경우 y, 신경망이 출력한 확률이 1(100%)에 가까울수록 오차 감소
- 오차가 앞으로 흘러가기 때문에 오차가 크면 크게 학습, 오차가 작으면 작게 학습!
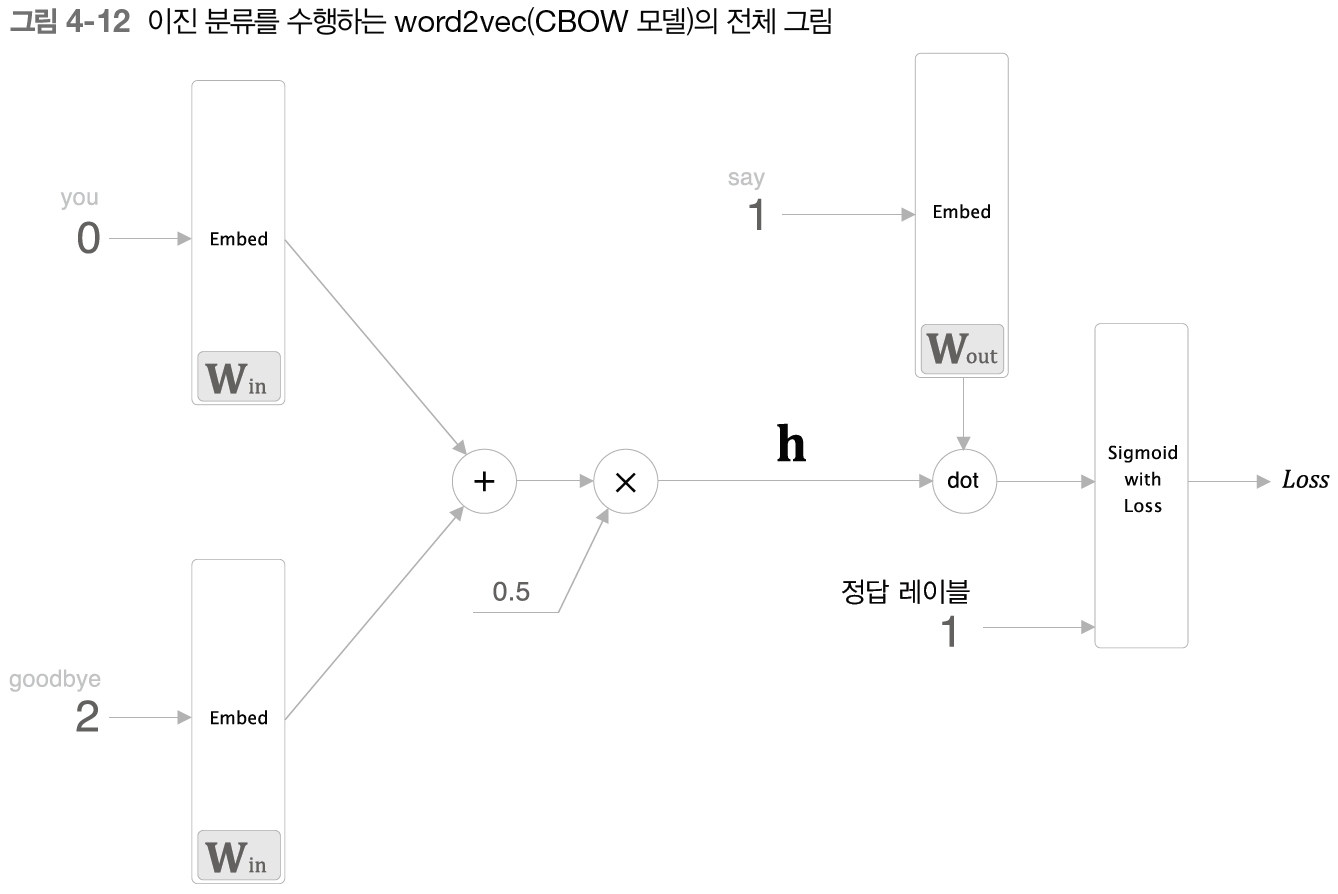 - 이 이진 분류의 답이 오답이라면 정답 레이블에 0 입력
- 이 이진 분류의 답이 오답이라면 정답 레이블에 0 입력
- 정답일 경우 sigmoid 계층 출력이 1에 가깝고 오답일 경우에는 0에 가까워야 한다.
- 하지만 오답인 경우를 모두 학습시키면 어휘 수 증가에 따른 문제점이 또 발생하므로 몇 개의 어휘만을 샘플링 한다 -> negative sampling
- 말뭉치의 통계 데이터를 기초로 샘플링(확률분포대로) -> 자주 등장하면 많이 추출
++이 때 확률 분포에 0.75와 같은 수치를 곱해야 한다 -> 회소한 단어 또한 버리지 않기 위해
++unigram: 하나의 연속된 단어, bigram, trigram
- negative sampling 최종 손실 = 정답인 경우 손실 + 샘플링 된 오답인 경우 손실
4.3 개선판 word2vec 학습
- Embedding 계층, Negative Sampling Loss 계층 적용
- PTB 데이터셋으로 학습
- 맥락의 윈도우 크기 임의로 조정 가능
- W_in, W_out 같은 형상(Negative Sampling Loss에서 Embedding을 사용)
- 원핫 벡터가 아닌 단어 id를 인수로
++ 말뭉치에 따라 다르나 윈도우 크기는 2~10개, 은닉층의 뉴런 수(단어의 분산 표현 차원 수)는 50~500개면 좋은 결과
++python pickle - CBOW 모델 평가
- 동의어, 유의어
- 유추(비유) 문제 (ex. man:king = woman: ?)
- 유추 문제를 벡터의 덧셈과 뺄샘으로 해결
- 벡터 공간에서 man -> woman 벡터와 king -> ? 벡터가 가능한 한 가까워지는 단어 찾기
- 시제 정보, 단수형과 복수형, 비교급 성질(의미 뿐만 아니라 문법적인 패턴도)
4.4 word2vec 남은 주제
- 전이 학습(transfer learning): word2vec의 단어 분산 표현 -> 텍스트 분류, 문서 클러스터링, 감정 분석 등 다양하게 적용 가능
- 단어/문장을 고정 길이 ⭐️벡터⭐️로 변환 가능 (ex. bag-of-words: 단어의 순서를 고려 X)

- 단어의 분산 표현 학습과 머신러닝 시스템의 학습은 서로 다른 데이터셋을 사용해 개별적으로 수행하는 것이 일반적, 직면한 문제의 학습 데이터가 아주 많을 경우 단어 분산 표현과 머신러닝 시스템 학습 모두를 처음부터 수행하는 방안도 고려 가능
- 단어 벡터 평가 방법
- 궁극적으로 원하는 건 정확도 높은 시스템(여러 시스템으로 구성, ex: 단어의 분산 표현 만드는 시스템 + 특정 문제에 대해 분류를 수행하는 시스템)
- 단어의 분산 표현의 차원 수가 시스템에 어떤 영향을 주는지?- 단어의 분산 표현 학습 -> 분산 표현 바탕으로 머신 러닝 시스템 학습 -> 평가, 하이퍼파라미터 조정, 시간 매우 오래 걸림
-> 단어의 분산 표현의 우수성을 실제 전체 시스템과 분리해 평가
- 단어의 분산 표현 학습 -> 분산 표현 바탕으로 머신 러닝 시스템 학습 -> 평가, 하이퍼파라미터 조정, 시간 매우 오래 걸림
- 평가 척도: 단어의 유사성, 유추 문제(단어의 의미나 문법적인 문제를 제대로 이해하고 있는지)
- 모델에 따라 정확도 다름
- 일반적으로 말뭉치가 클수록 결과 좋음
- 단어 벡터 차원 수는 적당한 크기가 좋음
-> 유추 문제에 의한 평가가 높다고 반드시 전체 시스템이 높은 정확도를 갖는다는 것은 아님
학습한 코드는 여기에서
https://github.com/syi07030/NLP_study
위 코드는 이 책의 코드와 아래의 코드를 바탕으로 작성했습니다.
https://github.com/WegraLee/deep-learning-from-scratch-2
사진 출처 또한 여기에서: https://github.com/WegraLee/deep-learning-from-scratch-2

잭과 근나물