5. 1. 선형 SVM 분류
- SVM의 기본 아이디어는 직선 형태의 결정 경계를 이용하여 데이터를 분류하는 것이다.
- SVM 분류기는 클래스 사이에 가장 폭이 넓은 도로(최고의 마진)를 찾는 방향으로 분류를 수행한다. 따라서 도로 바깥쪽에 훈련 샘플을 더 추가해도 결정 경계에는 영향이 가지 않으며, 오히려 도로 경계에 위치한 샘플에 의해 전적으로 결정된다.
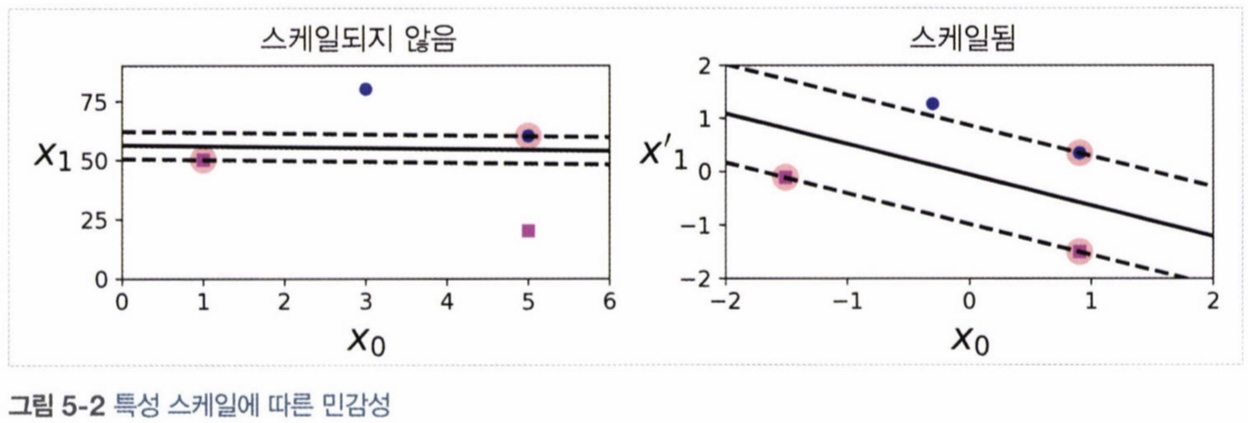
- SVM은 특성 스케일에 민감하기 때문에 Scaler를 사용하여 스케일을 조정하면 좋은 결과를 얻을 수 있다.
5. 1. 1. 소프트 마진 분류
-
하드 마진 분류
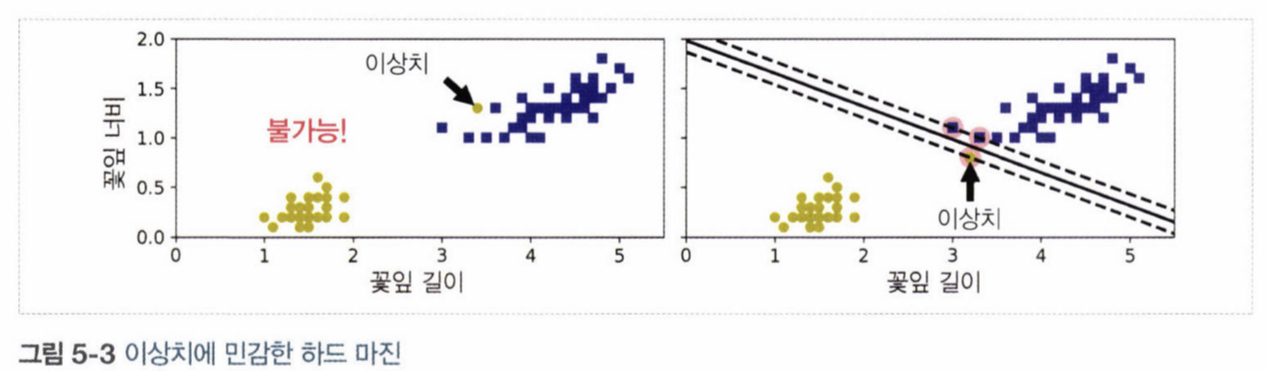
모든 샘플이 모두 도로 바깥쪽에 분류되어 있을 때 발생. 데이터의 선형적으로 구분이 가능해야 한다는 조건이 필수, 이상치에 민감하다는 특징 ⇒ 마진 오류 발생, 일반화가 어렵다.
-
소프트 마진 분류 : 도로의 폭을 가능한 한 넓게 유지하면서 마진 오류를 적절하게 조절해야 한다. ⇒ SVM 모델을 만들 때 여러 하이퍼파라미터를 이용해 조절이 가능하다.
iris = datasets.load_iris()
X = iris['data'][:,(2,3)]
y = (iris['target'] == 2).astype(np.float64)
svm_clf = Pipeline([('scaler', StandardScaler()), ('linear_svc', LinearSVC(C=1, loss='hinge'))])
svm_clf.fit(X, y)
svm_clf.predict([[5.5, 1.7]])- 하이퍼 파라미터
C: 숫자가 높을수록 마진이 더 좁아지는, 반면 마진 오류는 증가 ⇒ 모델이 과대적합일 시, 마진 오류가 많아지더라도 C를 감소시켜 모델 규제한다.
X, y = make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0, n_repeated=0, n_classes=2,random_state=42)
clf_1 = SVC(C=0.1, kernel='linear').fit(X, y)
clf100 = SVC(C=100, kernel='linear').fit(X, y)
fig, axes = plt.subplots(2, 1, figsize=(10, 15))
axes[0].set_title("Linear kernel with C=0.1", fontsize=18)
axes[0].scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='cool')
plot_svc_decision_function(clf_1,ax=axes[0])
axes[1].set_title("Linear kernel with C=100", fontsize=18)
axes[1].scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='cool')
plot_svc_decision_function(clf100,ax=axes[1])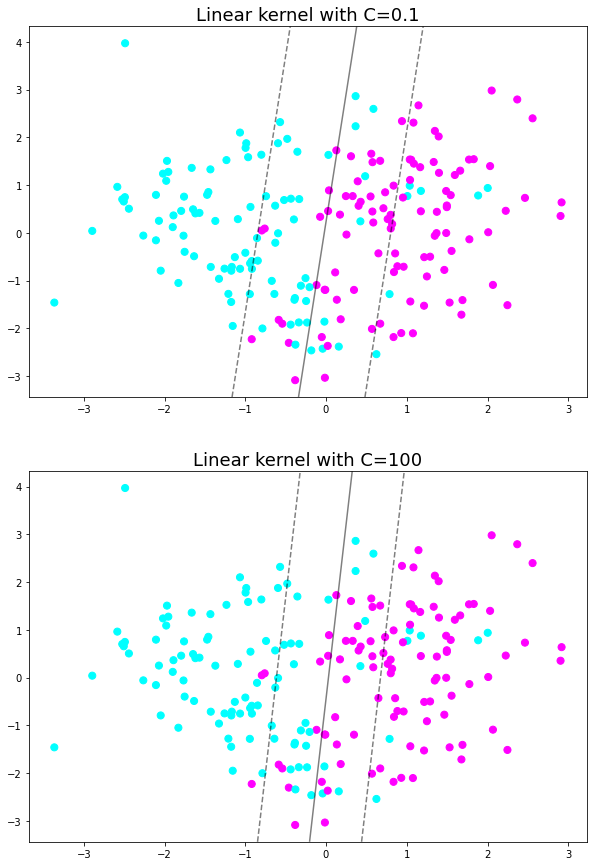
- 소프트 마진 분류 이용 예시
1.LinearSVC(C=1 ,loss="hinge")
2.SVC(kernel="linear", C=1): SVC 모델의 경우 큰 데이터에서는 속도가 느리기 때문에 권장하지 않는다.
3.SGDClassifier(loss="hinge", alpha=1/(m*c)): 선형 SVM 분류기를 훈련시키디 위해 일반적인 확률적 경사 하강법을 적용하는 방식이다. LinearSVC만큼 속도가 많이 빠르진 않지만 데이터가 크고 특성이 많아서 메모리에 적재시켜줄 수 없을 때 유하다.
참고hingeloss function?
마진을 최대화 하는 SVM의 loss function으로 멀리 떨어진 Error case 인스턴스에 가중치를 가하여 구하는 손실
5. 2. 비선형 SVM 분류
- 선형으로 분류할 수 없는 데이터셋의 경우, 선형 SVM을 사용할 수 없음 ⇒ 다항 특성 같은 특성을 더 추가하면 선형 구분이 가능하다.
- PolynomialFeatures 변환기, StandardScaler, LinearSVC를 연결한 파이프라인으로 비선형 데이터를 선형 분류기로 분류한다.
X, y = datasets.make_moons(n_samples=100, noise=0.15)
polynomial_svm_clf = Pipeline([('poly_features', PolynomialFeatures(degree=3)), ('scaler', StandardScaler()), ('svm_clf', LinearSVC(C=10, loss='hinge'))])
polynomial_svm_clf.fit(X, y)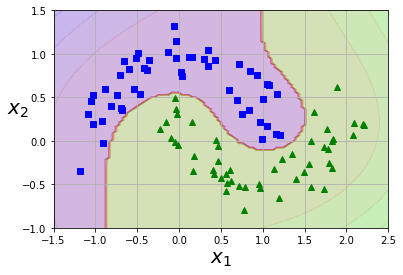
5. 2. 1 다항식 커널
- 다항식 특성을 추가할 때 낮은 차수의 다항식은 복잡한 데이터셋을 잘 표현하지 못하고, 높은 차수의 다항식은 특성이 매우 많아지므로 모델이 느려진다.
kernel='poly': SVM에 적용할 수 있는 커널 트릭으로 실제로는 특성을 추가하지 않지만 다항식 특성을 많이 추가한 것과 같은 결과 구현 가능 ⇒ 실제로는 특성 추가를 하지 않기 때문에 특성 조합이 많이 생기지 않는다.coef0: 다항식 커널의 상수항 r을 뜻함. 다항식 커널은 차수가 높아질수록 1보다 작은 값과 큰 값의 차이가 커지므로 coef0을 적절한 값으로 지정하면 고차항의 영향을 줄일 수 있다.
X, y = datasets.make_moons(n_samples=100, noise=0.15)
poly_kernel_svm_clf = Pipeline([
('scaler', StandardScaler()),
('svm_clf', SVC(C=5, kernel='poly', degree=3, coef0=1))
])
poly_kernel_svm_clf.fit(X, y)
poly100_kernel_svm_clf = Pipeline([
('scaler', StandardScaler()),
('svm_clf', SVC(C=5, kernel='poly', degree=10, coef0=100))
])
poly100_kernel_svm_clf.fit(X, y)
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_predictions(poly_kernel_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.title(r'd = 3, r = 1, C = 5',fontsize=18)
plt.subplot(122)
plot_predictions(poly100_kernel_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.title(r'd = 10, r = 100, C = 5',fontsize=18)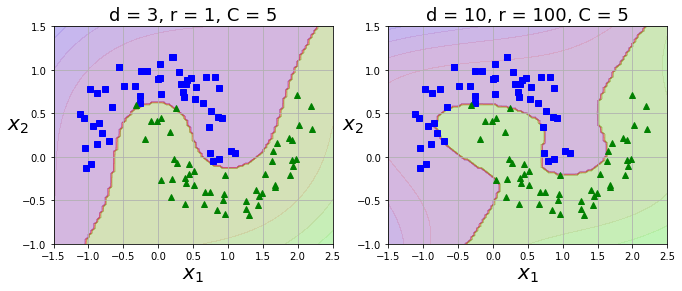
5. 2. 2. 유사도 특성
- 비선형 특성을 다루기 위해 각 샘플이 특정 랜드마크와 얼마나 닮았는지 측정하는 유사도 함수로 계산한 특성을 추가한다.
Example
1차원 데이터셋에 두 개의 랜드마크 𝑥₁ = -2와 𝑥₁ = 1을 추가한 후 𝛾 = 0.3인 가우시안 방사 기저 함수(Radical Basis Function, RBF)를 유사도 함수도 정의할 경우, 가우시안 RBF 함수는 다음과 같이 정의된다.
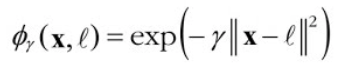
이 함수의 값은 0부터 1까지 변화하며 종 모양으로 나타난다.
𝑥₁ = -1일 때 이 샘플은 첫 번째 랜드마크에서 1만큼 떨어져 있고 두 번째 랜드마크에서 2만큼 떨어져 있습니다. 그러므로 새로 만든 특성은 𝑥₂ = exp(-0.3 × 1²) ≈ 0.74와 𝑥₃ = exp(-0.3 × 2²) ≈ 0.30 이라고 할 수 있다. 가우시안 RBF를 사용한 유사도 특성을 그래프로 그려보면 다음과 같다.
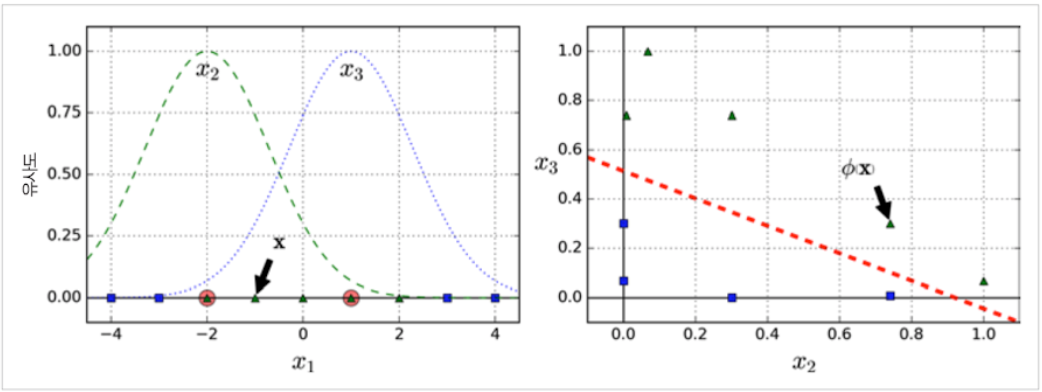
5. 2. 3. 가우시안 RBF 커널
kernel='rbf': SVM에 적용할 수 있는 커널 트릭으로 유사도 특성을 많이 추가하는 것과 같은 비슷한 결과를 얻을 수 있다gamma: gamma가 증가하면 위에서 나타낸 가우시안 RBF를 사용한 유사도 특성의 종 모양 그래프가 좁아져 각 샘플의 영향 범위가 감소 ⇒ C와 마찬가지로 규제 역할을 하며, 모델이 과대적합일 경우에는 감소시키고 반대의 경우에는 증가시켜야 한다.
gamma_lst = [0.1, 0.1, 5, 5]
C_lst = [0.001, 1000, 0.001, 1000]
for g, c in zip(gamma_lst, C_lst):
rbf_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=g, C=c))
])
rbf_kernel_svm_clf.fit(X, y)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
mglearn.plots.plot_2d_separator(rbf_kernel_svm_clf, X)
plt.title('gamma : {}, C : {}'.format(g, c))
plt.show()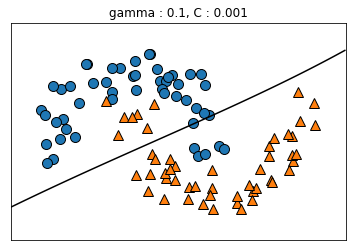
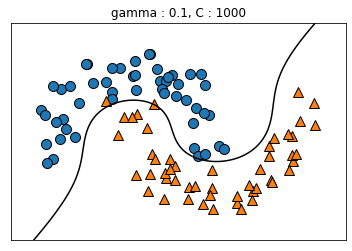
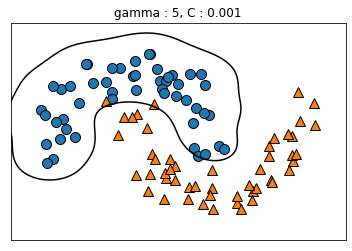
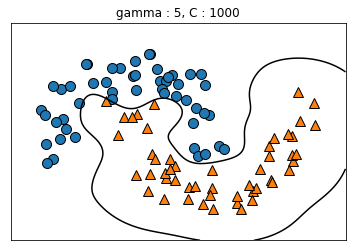
5. 2. 4. 계산 복잡도
LinearSVC 파이썬 클래스는 선형 SVM을 위한 최적화된 알고리즘을 구현한 것으로, 커널 트릭을 지원하지 않지만 훈련 샘플과 특성 수에 거의 선형적으로 늘어나는 경향이 있다. 이 때, 이 알고리즘의 훈련 시간 복잡도는 O(m,n)이며 이와 비슷한 다른 알고리즘과 특징을 비교하면 아래와 같다.

5. 3. SVM 회귀
- SVM 알고리즘은 다목적으로 사용할 수 있는데 선형, 비선형 분류 뿐만 아니라 선형, 비선형 회귀에도 사용이 가능 ⇒ SVM을 분류가 아니라 회귀에 적용하기 위해서는 목표를 반대로 설정해야 한다.
- 기존의 SVM 분류 : 일정한 마진 오류 안에서 두 클래스 간의 도로 폭이 가능한 최대가 되도록 함.
- SVM 회귀 : 제한된 마진 오류 안에서 도로 안에 가능한 한 많은 샘플이 들어가도록 학습
epsilon: 마진의 폭을 조절하는 파라미터로, 마진 안에서는 훈련 샘플이 추가되어도 모델의 예측에는 영향이 없기 때문에, 이 때 모델을 epsilon에 민감하지 않다고 표현한다.
np.random.seed(42)
m = 100
X = 2 * np.random.rand(m, 1) - 1
y = (0.2 + 0.1 * X + 0.5 * X**2 + np.random.randn(m, 1)/10).ravel()
svm_poly_reg1 = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)
svm_poly_reg1.fit(X, y)
svm_poly_reg2 = SVR(kernel="poly", degree=2, C=0.01, epsilon=0.1)
svm_poly_reg2.fit(X, y)
plt.figure(figsize=(12,4))
plt.subplot(121)
plot_svm_regression(svm_poly_reg1, X, y, [-1, 1, 0, 1])
plt.title(r"$degree={}, C={}, \epsilon = {}$".format(svm_poly_reg1.degree, svm_poly_reg1.C, svm_poly_reg1.epsilon), fontsize=18)
plt.ylabel(r"$y$", fontsize=18, rotation=0)
plt.subplot(122)
plot_svm_regression(svm_poly_reg2, X, y, [-1, 1, 0, 1])
plt.title(r"$degree={}, C={}, \epsilon = {}$".format(svm_poly_reg2.degree, svm_poly_reg2.C, svm_poly_reg2.epsilon), fontsize=18)
plt.show()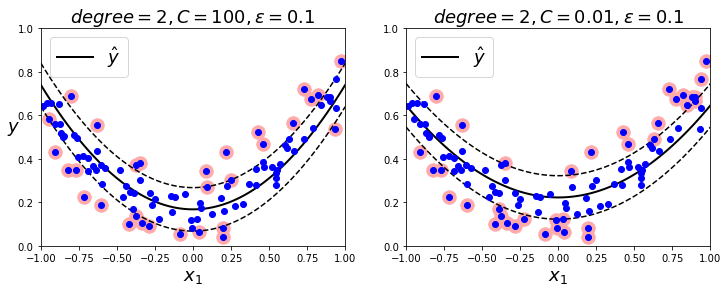
규제가 많을수록(우) 마진이 늘어난다.
