
📌 좋아요 기능
FoodMall 프로젝트의 기능 중에는 좋아요 기능가 있다. 그때는 아무래도 처음 개발을 시작한 때라 동시성보다는 데이터 정합성을 더 중요시 여겼었다. 하지만 사전 과제를 하면서 해당 기능 다시 접할때는 데이터 정합성보다는 동시성이 더 중요하게 여기게 되었고, 좋아요 수를 해당 게시물에 반영하는 기능을 @Scheduled를 이용해 새로 구현했다.(즉, foodmall를 리팩토링했다기 보다는, 새로운 프로젝트를 진행했다. 다만, 두 프로젝트 다 좋아요 기능이 있는데 더 개선하여 realestatecommunity 프로젝트에 반영하였다.)
간단하게 해당 기능을 설명하자면,realEstateCommunity에서는
1. 특정 사람이 게시물에 좋아요를 누른다. → heart 디비 접근
2. 게시물의 총 좋아요 수를 반영하는 작업을 위해, 이전에 체크하지 않은 하트(좋아요)를 확인하고 수집하여 각 게시물의 하트 수를 업데이트한다. → post 디비 접근
시간이 지나고, [ 자바 언어로 배우는 디자인 패턴 입문 - 멀티 쓰레드 편 ]이라는 책을 통해, concurrentHashmap에 대한 내용을 접하면서 해당 기능을 위한 구현 코드 일부가 동시성을 놓친 부분이 있다는 것을 확인하였다.
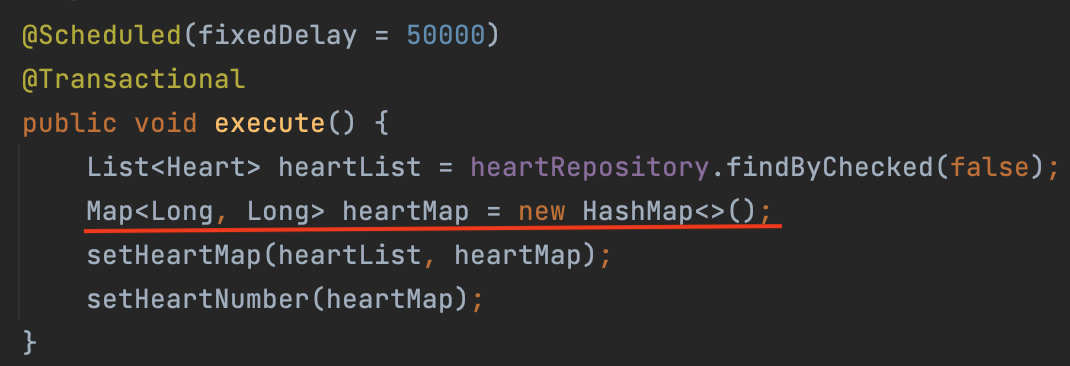
관련 깃허브 링크 : https://github.com/sue4869/RealEstateCommunity
위 코드는 HashMap으로 구현된 코드이다. HashMap은 단일 스레드 환경에서 안전하게 사용할 수 있는 Map이다. 공식 문서에서도 Hashmap이 synchronized를 지원하지 않는다고 써져있다.

그렇다면 코드상에서 ConcurrentHashMap과의 차이점은?
아래 그림에서 왼쪽은 HashMap의 putVal()이고 오른쪽은 ConcurrentHashMap의 putVal()이다.
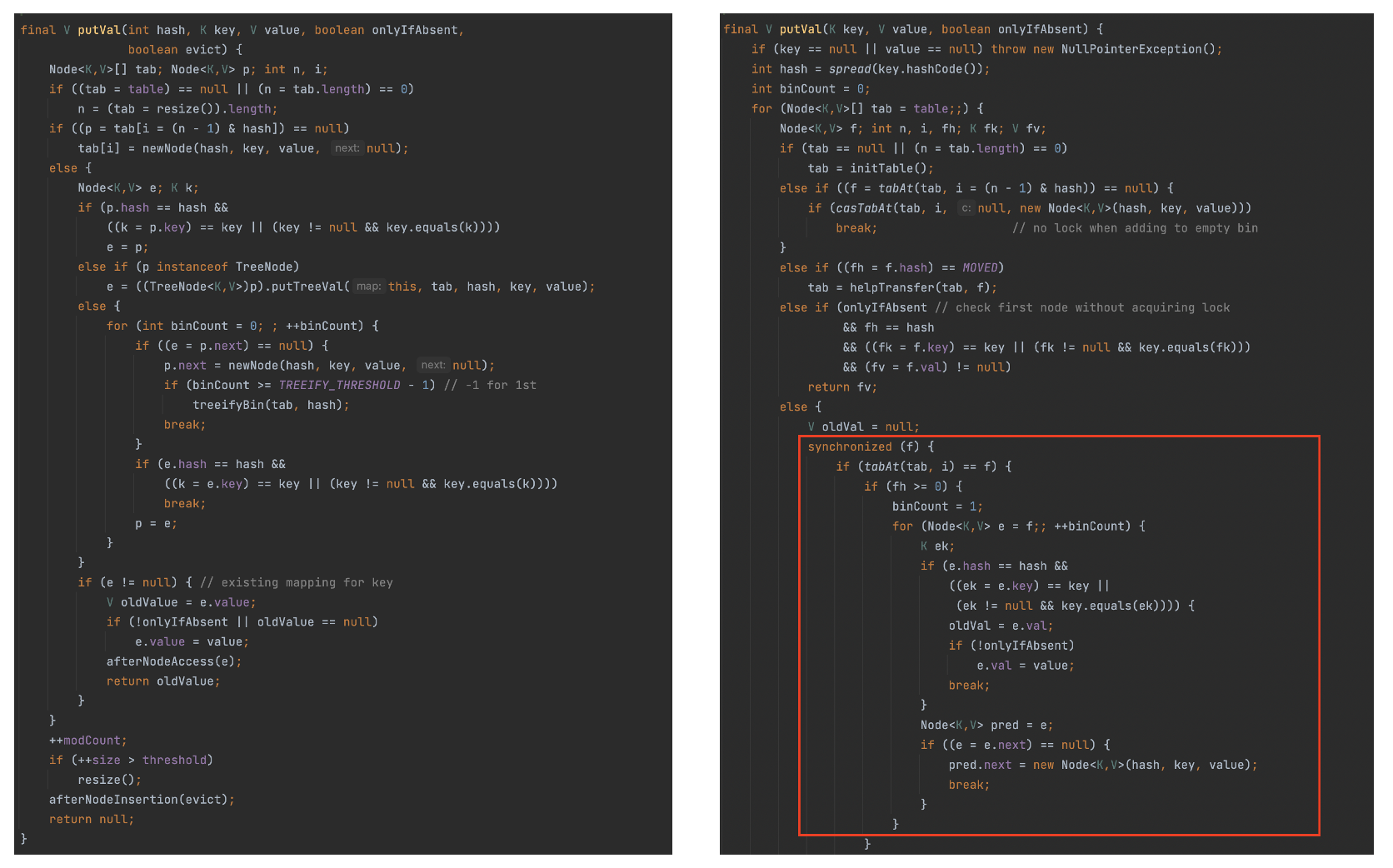
왼쪽의 HashMap의 putVal()과 달리 오른쪽 그림의 ConcurrentHashMap의 putVal()에서는 synchronized를 사용하는 것을 확인할 수 있다.
🐳 ConcurrentHashMap
내부의 데이터 구조를 분할함으로써 구조적으로 간섭하지 않는 쓰레드 사이에 배타제어가 일어나지 않게 한다. 각각의 bucket별로 동기화를 진행하기에 다른 bucket에 속해 있을 경우, 별도의 lock 없이 운용한다. 각 Table bucket을 독립적으로 잠그는 방식이다.
ex) put 메소드
- 빈 Hash Bucket에 노드를 사용할 경우 : lock 사용하지 않고, compare and swap을 사용
💡 여러 쓰레드가 접근하면?
CAS 알고리즘으로 다시 한번 확인한다. 즉, bucket 값이 비어있을 경우 volatile 변수에 접근(가시성 보장)하여 기대값(null)과 일치하는지 한 번 더 확인하여 일치할 경우에만 노드를 생성한다(원자성 보장). 이와 같이 동시성을 처리함으로 Thread-safety를 보장한다
CAS 알고리즘 : CAS 알고리즘은 현재 스레드가 가지고 있는 기존값과 메모리가 가지고 있는 값을 비교해 같은 경우 변경할 값을 메모리에 반영하고 true를 반환한다.
- 이미 Bucket에 노드가 존재할 경우 : synchronized 을 이용해 하나의 thread만 접근하도록 제어한다. 서로 다른 thread가 같은 hash bucket에 접근할 때만 해당 block이 lock된다.
📌 ConcurrentHashMap vs HashMap 성능 테스트 해보자 ! (Apache Jmeter 활용)
해당 코드에서 HashMap으로 구현된 부분을 ConcurrentHashMap으로 바꾸는 것이 성능상 맞을까? 에 대해 의문이 들었고, 이를 테스트해보았다.
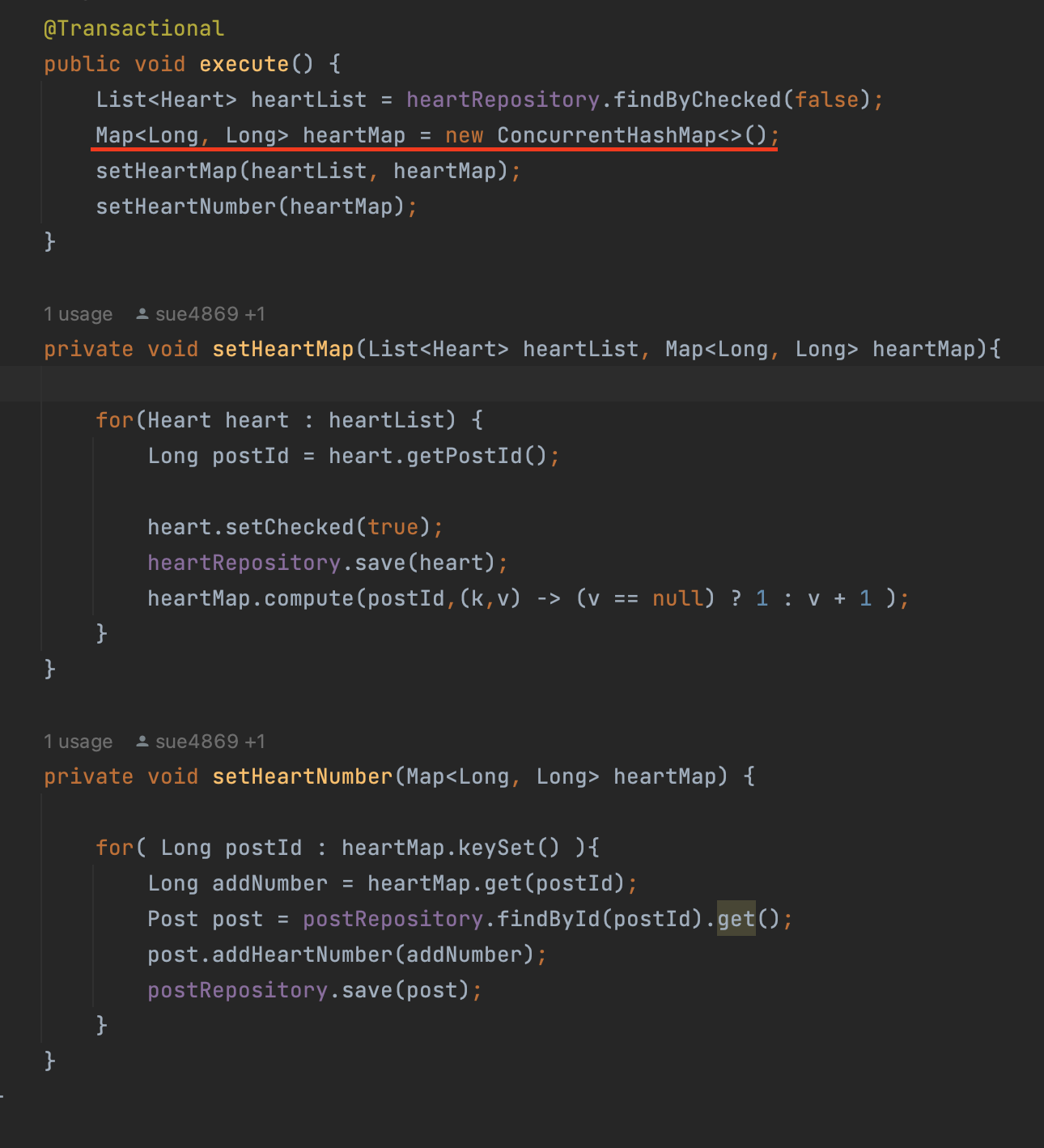
내가 테스트를 위해 바꾼 것은 빨간 밑줄인 ConcurrentHashMap 부분이다.이전에 해당 부분은 HashMap으로 구현되어 있었다. 해당 부분이 ConcurrentHashMap일때와 HashMap일때 멀티쓰레드 환경에서 얼마나 차이를 보이는 지를 직접 눈으로 확인해보고 싶었다.
여러 테스트 도구가 있지만, 진입장벽이 낮으면서도 간편하게 성능테스트를 진행할 수 있는 Jmeter를 이용해서 테스트를 진행하였다.
결과 분석을 위한 각 요소가 의미하는 바에 대해 간략하게 말해보자면,
- Samples : 서버에 요청한 횟수
- Average : 평균응답시간(ms)
- Min : 최소응답시간(ms)
- Max : 최대응답시간(ms)
- Std. Dev. : 표준편차
요청에 대한 응답시간의 일정하고 안정적인가를 확인, 값이 작을수록 안정적이다. - Error : Error율(%)
- Throughput : 처리량(초당 처리건수)
- KB/sec : 처리량(초당 처리 KB)
테스트는

위 그림에 나온 것처럼 1000개의 쓰레드를 이용해 총 2만번 수행하도록 진행하였다.
ConcurrentHashMap일 경우,

HashMap일 경우,

내가 주목한 것은 Std. Dev.(표준편차)와 Throughput(처리량)이었다.
ConcurrentHashMap은
- Std. Dev.(표준편차) : 1266.13
- Throughput(처리량) : 266.4/sec
HashMap은
- Std. Dev.(표준편차) : 1507.92 ,
- Throughput(처리량) : 230.8/sec
으로 ConcurrentHashMap이 HashMap보다 표준편차가 더 낮아서 안정적이고, 처리량은 더 높은것을 알 수 있었다.
📌 결론
사실 내가 예상한 것은 표준편차가 ConcurrentHashMap이 더 낮아서 안정적이지만, 처리량은 HashMap이 더 높게 나오는 것이었다. 코드상 ConcurrentHashMap에서는 일부 synchroized를 사용하여 처리량이 약간 낮게 나올 것이라 생각했기 때문이다. 하지만 막상 테스트를 해보니 예상대로 나온 것이 아니라 ConcurrentHashMap이 안정성에서도 처리량에 있어서도 hashmap보다 더 나은 결과가 나왔다. 테스트를 직접해보니 더 재밋게 성능 비교가 되는 것 같다.
이 테스트를 통해, 해당 코드에서 ConcurrentHashMap으로 바꾸는 것이 맞다는 결론을 내렸다.
