
운영 서버에서 63,000건의 이미지 배치 작업 중 락이 발생하며 장애가 발생했다. 처음 겪는 규모 있는 데이터 처리 이슈였고, 원인은 단순하지만 치명적이었다. 이 글은 그 문제의 원인, 해결, 그리고 회고를 정리한 실무 경험 공유이다.
배경
이번에 회사에서 진행했던 프로젝트는 승인서버 프로젝트이다. 승인서버 프로젝트는 외부 연동으로 들어온 데이터를 우리 관리 시스템으로 들어오기 전에 검수하는 시스템을 구축하는 프로젝트다.

크게 보면 이렇게 볼 수 있다.
여기서 내가 한 일 중 하나는 이미지 배치 처리 기능의 설계 및 구현이다. 주요 작업은 다음과 같다.
S3 이미지 업로드를 위한 비동기 배치 모듈 개발
- 1시간 단위로 실행되는 이미지 배치 작업: INIT, FAIL 상태이며 재시도 횟수가 1 이하인 프로덕트/아이템 이미지를 대상으로 처리
- 특정 프로덕트 단위의 재연동 기능 구현: 선택된 프로덕트의 INIT, FAIL 상태 이미지만 재처리하며, 재시도 제한 없음
이미지 업로드 후 상태 및 재시도 관리
- 업로드 성공 시: retry 횟수 증가 + 상태 COMPLETE로 변경
- 업로드 실패 시: retry 횟수 증가 + 상태 FAIL 유지 및 슬랙 알림 전송
배치를 적용한 이유
2차 승인 단계에서 등록되는 각 프로덕트/아이템은 여러 개의 이미지를 포함하고 있으며, 이 이미지들은 모두 AWS S3에 업로드되어야 한다. 초기에는 등록 시점에 실시간으로 이미지를 업로드하는 방식도 고려했지만, 아래와 같은 이유로 배치 처리 방식을 도입하게 되었다.
성능 이슈
이미지 업로드는 네트워크 I/O와 S3 API 호출이 포함된 작업으로, 처리 시간이 길다. 이를 실시간으로 수행할 경우 등록 속도가 느려지고, 사용자 경험에도 부정적인 영향을 줄 수 있다.
처리 안정성 확보
등록 도중 이미지 업로드에 실패하면 전체 등록이 실패할 수 있다. 배치로 처리하면 실패한 이미지에 한해 재처리할 수 있어 안정적인 처리가 가능하다.
S3 요청 비용 최적화
AWS S3는 요청 건수에 따라 비용이 발생한다. 실시간으로 이미지를 업로드할 경우, 이미지 수만큼 S3 요청이 발생하고, 트래픽이 많아질수록 비용도 크게 증가한다.
배치 처리 방식은 요청을 모아서 처리하기 때문에 네트워크 연결 및 클라이언트 설정을 재사용할 수 있고, 요청 효율을 높여 비용 절감과 처리 흐름 단순화에 기여한다.
이러한 이유로 이미지 업로드 작업을 프로덕트/아이템 등록 시점이 아닌 배치 처리로 전환하게 되었고, 해당 로직의 설계와 구현은 내가 직접 맡아 수행하였다.
장애 발생 및 대응
시원한 음료 한 잔 마시며 한숨 돌리고 있던 그 때
경고가 떴다!!!!!!
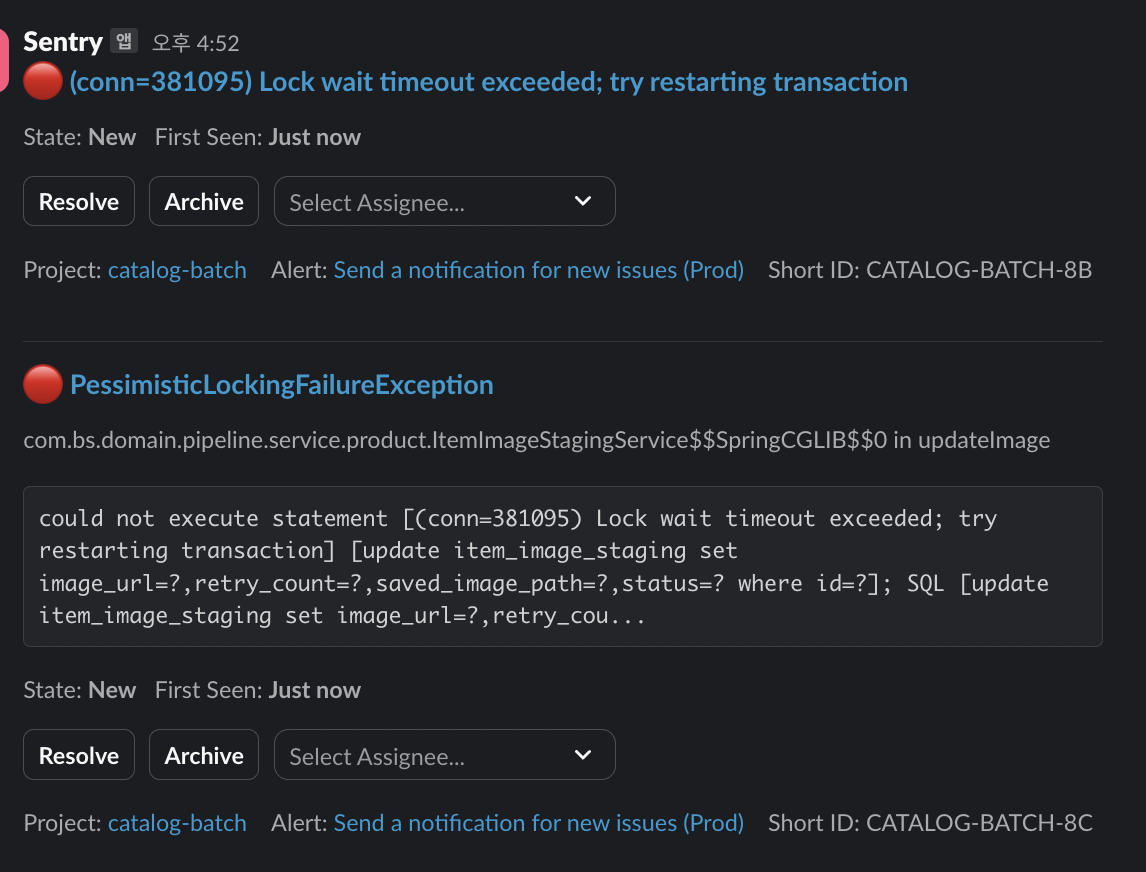
락이 걸린다고? 갑자기?? 배치에서??? 왜???
범인은 나였다. 나야 나...(내가 그 주인공이 될 줄은 몰랐다)
원인
이미지 업로드를 시키는 과정은 사실 단순하다.
1) INIT,FAIL 상태 & 재시도 1 이하인 임시이미지 조회
2) 해당 이미지 S3에 업로드
3) 해당 이미지 상태, 재시도 개수 수정 저장
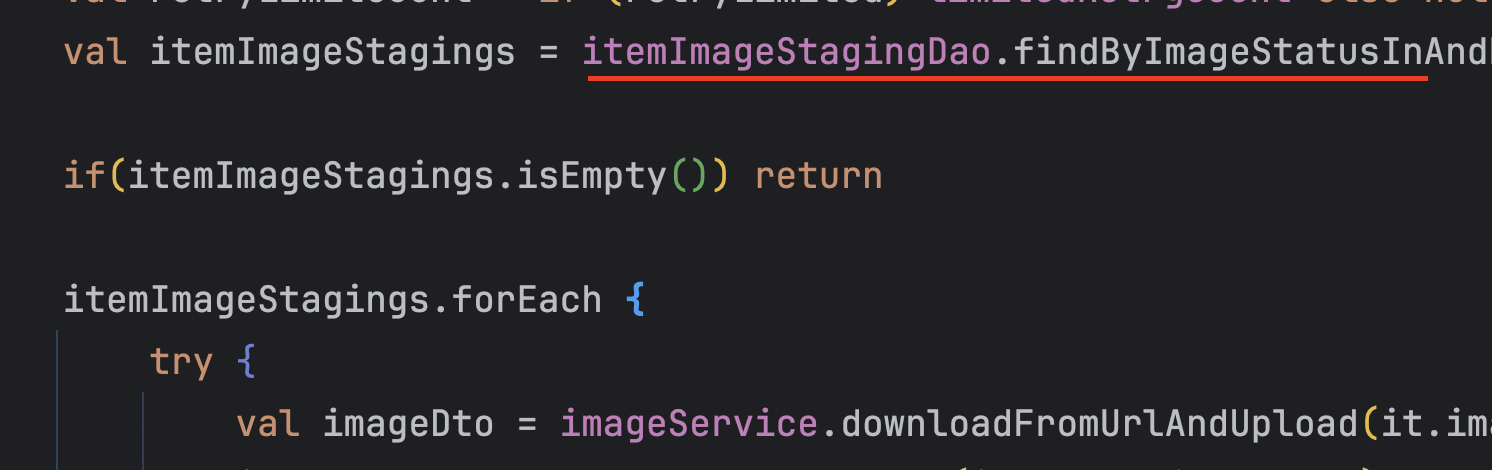
근데 문제는 내가 데이터의 규모를 예상치 못하고 조회시 관련 모든 데이터를 가져오게 만들었다는 것이다. 사실 이것만 봤을때는 뭐가 문제인데 할 수 있다. 관련 모든 데이터를 가져오는게 맞잖아?
그러나.. 데이터의 양이 6만 3천개라면?
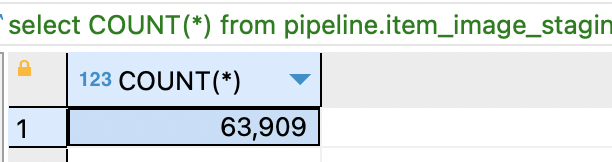
왜 락이 걸렸을까?
쉽게 말하면 6만개의 데이터를 수정하면서도 저장(flush)를 미루니까 트랜잭션이 너무 길어지고 락이 오래 유지되는 상황에서 동시에 같은 row에 접근하려는 다른 트랜잭션과 충돌이 발생하게 된것이다.
정리하면, 다음 세 가지가 문제의 핵심이었다:
- 한 번에 모든 데이터를 불러옴 (6만 건)
- 처리 중간에 flush 없이 트랜잭션을 유지
- DB 업데이트가 지연되면서 row-level lock 충돌 발생
해결법
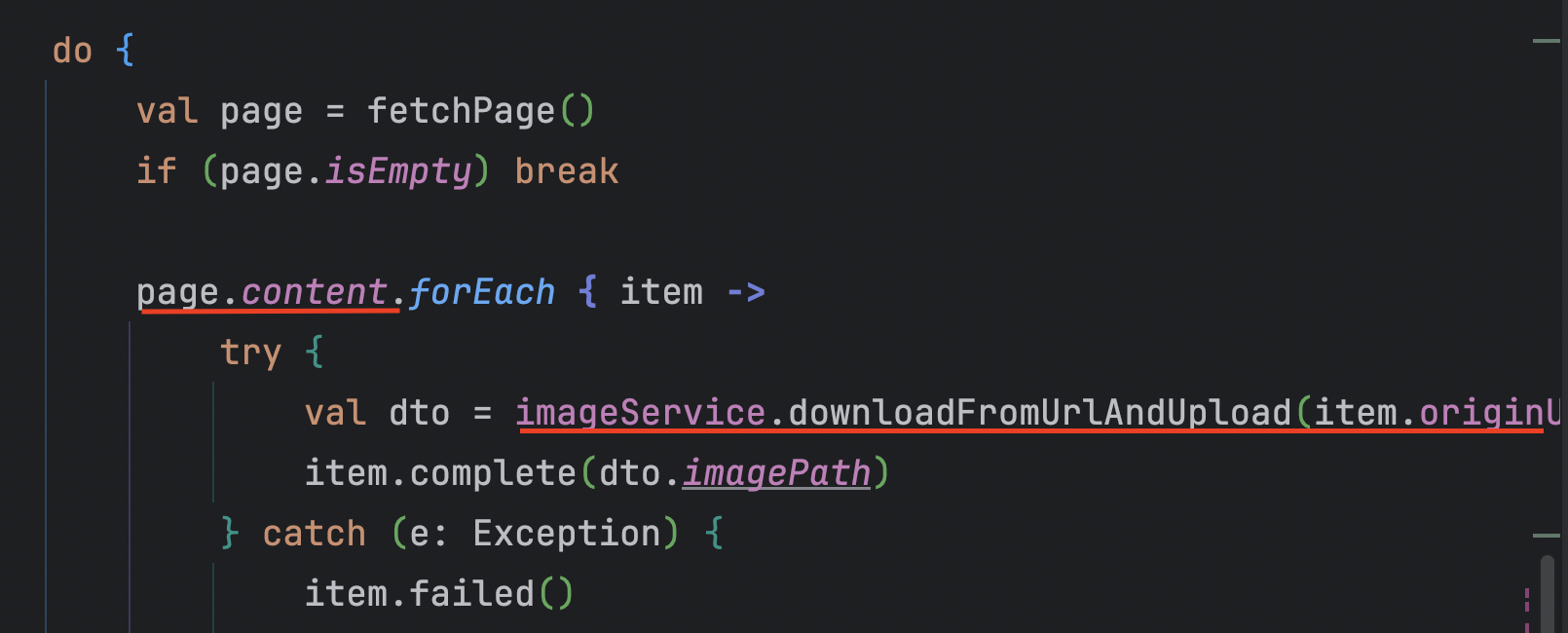
page 단위로 chunk 100개씩 가져와서 락을 빨리 빨리 해제하도록 수정하였다.
-
AS_IS
-
TO_BE
후기
해결 방법은 단순했다. 데이터를 페이지 단위로 나눠서 처리하면 되는 일이었다. 하지만 처음에는 그 방식이 떠오르지 않았다. 테스트 환경에서는 문제없이 동작했고, 실제 운영에서 63,000건이 넘는 데이터가 한 번에 들어올 거라고는 예상하지 못했기 때문이다.
이번 일을 통해 대규모 데이터 처리에서의 사소한 설계 차이가 시스템 안정성에 큰 영향을 줄 수 있다는 점을 몸소 깨달았다. 특히 다음 두 가지를 깊이 체감했다:
-
운영 환경 데이터를 기준으로 사고할 것
-
트랜잭션은 짧고 명확하게 유지할 것
실제 장애는 대량 데이터를 한꺼번에 처리하면서 트랜잭션이 길어지고, 그로 인해 DB 락 충돌이 발생한 것이 원인이었다. 이후 100건 단위로 나눠 처리하는 방식으로 개선하면서 락 점유 시간을 줄일 수 있었다.
단순한 설계 실수도 큰 장애로 이어질 수 있다는 점을 다시금 느꼈고, 앞으로는 더 철저하게 사고하고 검증해야겠다는 다짐을 하게 된 경험이었다.
