* 이 글은 인프런 - [데브원영] 아파치 카프카 for beginners (무료) 강의를 기반으로 작성되었습니다.
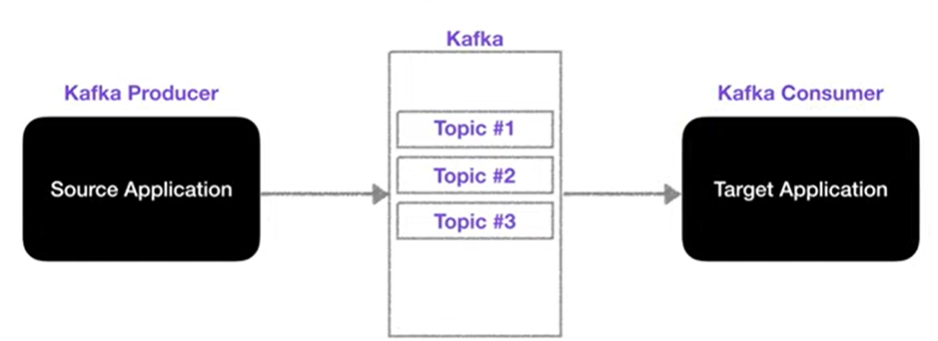
Topic
: 카프카에는 다양한 데이터가 들어갈 수 있는데, 그 데이터가 들어갈 수 있는 공간
카프카 토픽은, 일반적인 AMQP와는 다소 다르게 동작한다. 데이터베이스의 테이블, 파일 시스템의 폴더와 유사한 시스템을 가지고 있다.
마찬가지로 토픽에 데이터를 넣는 것은 프로듀서가, 가져가는 것은 컨슈머가 한다.
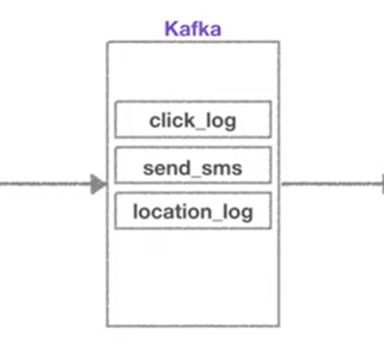
토픽은 이름을 가질 수 있는데, 목적에 따라 click_log, send_sms, location_log 등 무슨 데이터를 담는지 명확하게 명시하면 추후 유지보수 시 편리하게 관리가 가능하다.
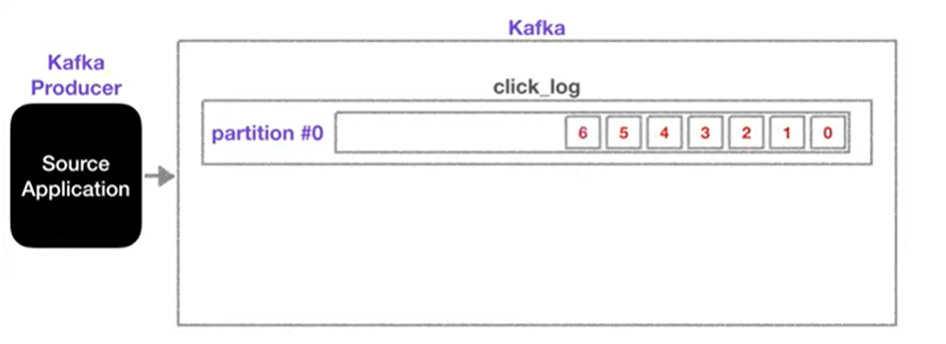
Partition
카프카 토픽 내부를 살펴보면, 하나의 토픽은 여러 개의 파티션으로 구성될 수 있으며 첫 번째 파티션 번호는 0부터 시작한다.
하나의 파티션은 큐와 같이, 내부의 데이터가 파티션 끝에서부터 차곡차곡 쌓이게 된다.
카프카 토픽에 컨슈머가 붙게 되면, 데이터를 가장 오래된 순서대로 가져가게 되며, 더이상 데이터가 들어오지 않으면 컨슈머는 또 다른 데이터가 들어올때까지 기다린다. (무한 loof)
Kafka의 특이한 점으로, 컨슈머가 토픽 내부의 파티션에서 데이터를 가져가더라도 데이터는 삭제되지 않고 파티션에 그대로 남게 된다.
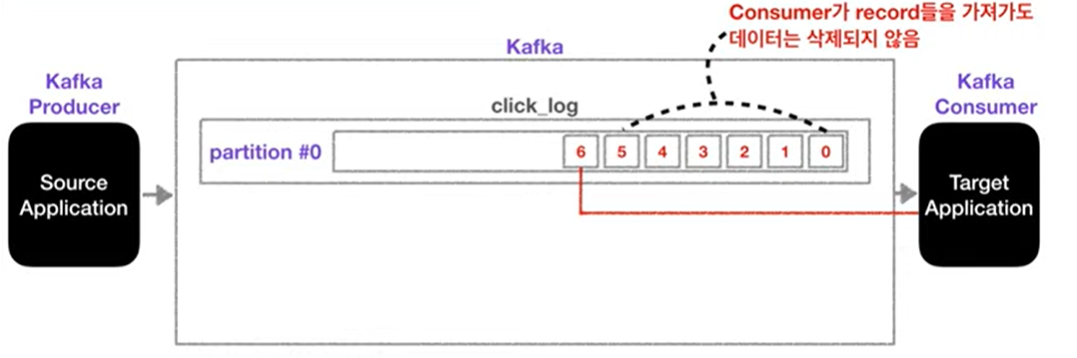
그럼 파티션에 남은 데이터는 누가 들고 가는가? -> 바로, 새로운 컨슈머가 붙었을 때 0번부터 가져가서 사용할 수 있다. 단, 컨슈머 그룹이 달라야 하며, auto.offset.reset=earliest로 세팅되어있어야 한다.
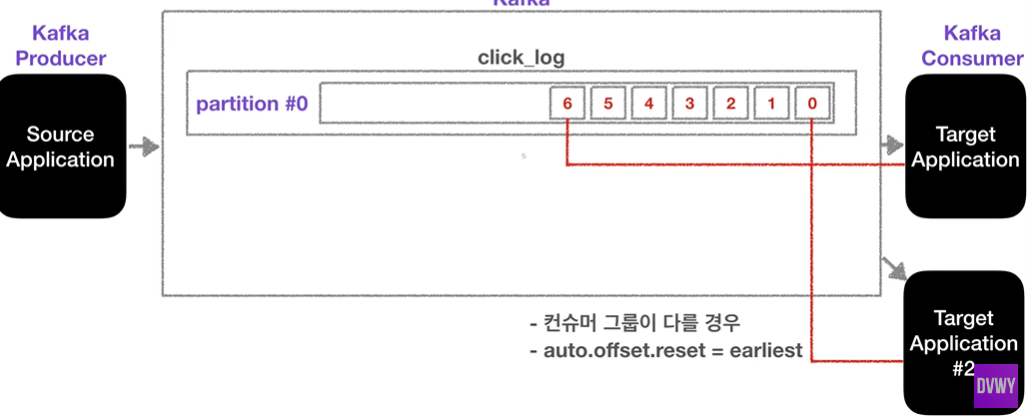
이처럼 사용할 경우, 동일 데이터에 대해 두 번 처리할 수 있는데, 이는 카프카를 사용하는 아주 중요한 이유이기도 하다.
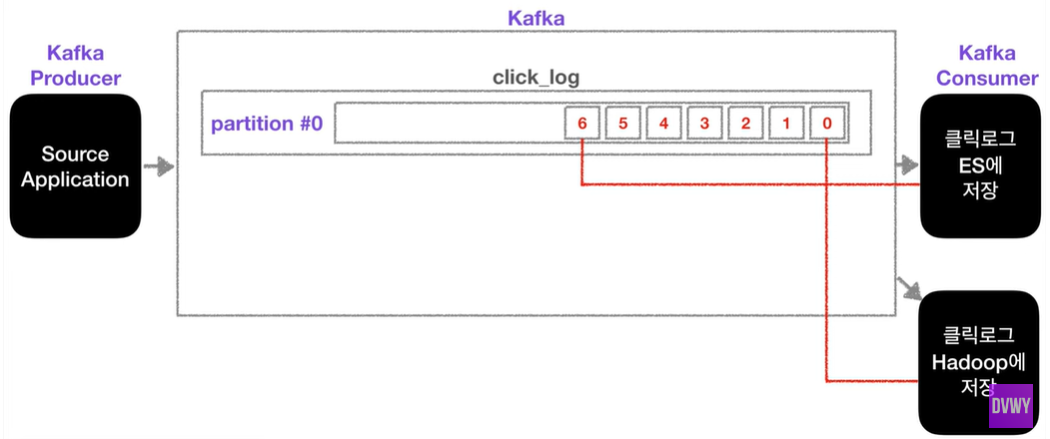
위의 그림처럼 클릭로그를 분석하고 시각화하기 위해 elastic search에 저장하기도 하며, 로그를 백업하기 위해 하드웨어에 저장할 수도 있다.
2개 이상의 Partition일 경우

파티션이 2개 이상일 경우, 데이터는 어디에 들어가는가?
이 때, 옵션이 하나 붙는다. 데이터를 보낼 때, key를 지정할 수 있는데, 이 key를 지정해서 보내는지의 여부에 따라 파티션 지정 방식이 달라진다.
💡 Case 1
key를 지정하지 않고 기본 파티셔너 설정 사용하면, round-robin으로 파티션이 지정된다.
즉, 만약 키가 null이고 기본 파티셔너 사용을 하게 되면 round-robin 방식으로 들어간다는 것이다.
💡 Case 2
key를 지정해서 보냈기 때문에 key가 있고, 기본 파티셔너를 사용할 경우에는 키의 hash값을 구하여 그에 따라 특정 파티션에 할당된다.
⚠ 주의
파티션을 늘리는 것은 아주 조심해야 한다. 파티션을 늘리는 것은 가능하지만, 줄일 수는 없기 때문!!!
따라서 key를 지정하는 방식으로 할 경우, 설계 단계에서 잘 생각하여 파티션을 추후에 늘릴 일이 없도록 하는 것이 현명하다.
Partition의 활용
-
파티션을 늘리면, consumer 개수를 늘려 데이터 처리를 분산시킬 수 있다.
-
데이터가 점점 늘어나면, 파티션의 데이터는 언제 삭제가 되는가?
👉🏻 삭제가 되는 타이밍은 옵션에 따라 다르다.- 레코드가 저장되는 최대 시간과 크기를 지정할 수 있다.
- 즉, 일정한 기간 또는 용량동안 데이터를 저장하고, 적절하게 데이터가 삭제될 수 있도록 설정할 수 있다.
