우선순위 큐(Priority Queue)
이번 포스트에서 다룰 자료구조는 우선순위 큐이다. 앞 포스트에 큐라는 자료구조에 대해 배웠는데, 이와 굉장히 유사하다.
우선순위 큐(Priority Queue)란?
- 일반적인 큐와 동일하게 연산 dequeue, enqueue 을 통해 데이터를 추가/삭제가 가능한 자료구조.
- 다만, 들어간 순서에 관계없이 우선 순위가 높은 데이터가 먼저 나온다.
일반적인 줄서기를 큐에 비유했다면, 우선순위 큐는 병원의 응급실로 비유하면 이해하기 편하다. 병원에 오는 사람들은 우선순위 큐의 enqueue 연산이고, 그 중에서 우선 순위가 높은 데이터 (병원 응급칠로 비유하면 응급한 환자)가 dequeue 연산을 통해 먼저 반환되는 것이다.
우선순위 큐를 구현해볼 건데, 앞서 스택과 큐는 배열기반과 연결리스트 기반으로 다 구현을 해보았다. 하지만, 우선순위 큐 같은 경우는 두 개의 자료구조의 활용이 좋지많은 않다.
1) 배열로 우선순위 큐 구현
- 데이터의 추가, 삭제 시 인덱스를 맞추기 위해 데이터를 한 칸씩 이동시켜야함.
- 삽입의 위치를 찾기 위해 모든 데이터의 우선순위를 비교하는 연산을 해야함.
2) 리스트로 우선순위 큐 구현
- 마찬가지로 삽입의 위치를 찾기 위해 모든 리스트 간의 우선순위를 비교하는 연산을 진행해야함.
그래서 우리는 우선순위 큐를 새로운 자료구조인 힙(Heap)으로 구현해볼 것이다.
힙(Heap)
힙(Heap)이란?
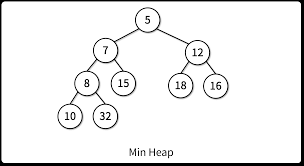
- 이진트리이되, 완전 이진트리인 자료구조
- 모든 노드에 저장된 값은 자식 노드의 값보다 크거나 같아야함.
위 사진이 힙의 모습을 잘 나타내주는 것 같다.
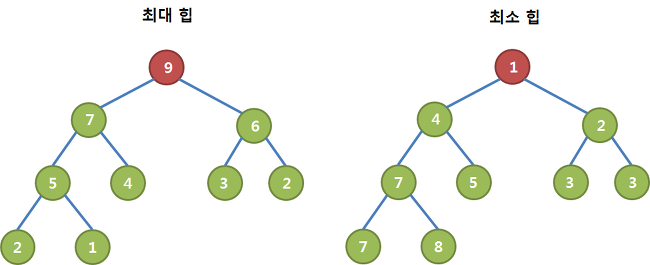
1) 최대 힙
- 루트 노드로 올라갈수록, 값이 커지는 완전 이진 트리
2) 최소 힙
- 루트 노드로 올라갈수록, 값이 작아지는 완전 이진 트리
힙의 데이터 추가 / 삭제 과정
힙에서의 데이터 추가와 삭제 과정을 알아보도록 하겠다.
1) 힙의 데이터 추가 과정
힙에서의 데이터를 추가하는 경우에는 새로운 데이터의 우선순위가 제일 낮다는 가정하에 노드에서의 마지막 위치에 배치한다. 그 이후에 부모 노드와 자식 노드 간의 우선 순위 비교를 통해 필요시 위치를 바꾼다. 그렇기에 힙에서의 트리의 레벨이 올라가도 (자료가 많아져도), 레벨 당 한 번씩의 비교 연산을 진행하기에 성능이 좋게 구현할 수 있다.
(단, 우선순위 비교는 사용자가 필요에 따라 함수를 구현하는 것이 중요)
2) 힙의 데이터 삭제 과정
힙에서의 데이터 삭제 과정은 우선 순위가 가장 높은 노드를 루트 노드라고 가정할 때, 루트 노드가 비워져있는 상태를 하는 것이다. 이러한 경우에는 마지막 노드(완전 이진트리의 마지막 레벨의 오른쪽 노드)를 루트 노드로 이동시킨 후 비교를 통해 제자리르 찾는 방법을 한다. 즉, 루트 노드를 반환하고 그 자리에 마지막 노드의 자리를 바꾸고 난 이후 데이터 추가과정에서처럼 부모/자식 노드만의 비교 연산을 통해 다시 자리를 찾게 하는 것이다. 그 과정에서 루트 노드는 두번째로 우선순위가 높은 노드로 채워지며 다시 힙의 구조가 이어지는 것을 확인할 수 있다.
3) 힙의 성능
배열에서 데이터의 저장의 시간 복잡도는 O(n), 데이터 삭제의 시간 복잡도는 O(1)
연결리스트에서는 저장의 시간 복잡도는 O(n), 삭제의 시간 복잡도는 O(1) 이지만,
힙에서는 저장의 시간 복잡도와 삭제의 시간 복잡도 모두 O(log2n)이다.
왜 O(log2n)인가?
- 트리의 높이가 하나 올라갈 때마다 연산횟수가 1개씩 증가하기 때문
우선순위 큐의 ADT
마지막으로 우선순위 큐의 ADT를 보고 이 포스트를 마무리하려고 한다. 힙의 구현에 있어서는 앞서 다룬 트리의 자료구로를 이해했다면, 인덱스 값을 설정하고 그에 맞게 코드로 구현하는 것이 가능할 것이다.
-
우선순위 큐의 초기화, 제일 먼저 호출되어야하는 함수
(PriorityComp pc => 우선순위를 내려주는 함수로 사용자가 필요에 따라 변해서 사용할 수 있음.)void PQueue Init(PQueue * ppq, Priority pc); -
우선순위 큐가 빈 경우 TRUE(1), 비지 않은 경우 FALSE(0)을 반환
PQIsEmpty(PQueue * ppq); -
우선순위 큐에 매개변수로 받은 데이터의 저장
void PEnqueue(PQueue * ppq, PQData data); -
우선순위가 가장 높은 데이터 삭제 후 반환
(데이터가 하나 이상 있을 때를 확인한 다음에 사용해야하는 함수)PQData PDequeue(PQueue * ppq);
이상 우선순위 큐의 ADT까지 알아보면서 이 포스트를 마치도록 하겠다. 사실, 스택과 큐 부터는 눈으로 보이며 쉽게 구현할 수 있지만, 트리부터는 생각해야하는 부분이 많기에 자료구조를 구현해보려는 연습을 한다면 노트나 연습장에 그림을 그려서 어떻게 구현할 것인지 그려보고 연습하는 것이 필요할 것 같다. 다음 포스트는 정렬 알고리즘에 대해 학습하고 다시 작성하도록 하겠다.
