연결 리스트
이 전 'Data Structure # 03 연결리스트 1' 에서 다뤘던 내용은 배열을 기반으로 한 연결리스트이다. 이번 포스트에 작성할 리스트는 연결 기반 리스트와, 이를 기반으로 한 원형리스트 그리고 양 방향 리스트에 대해 설명하려고 한다. 연결 기반 리스트의 구현을 앞서기 위해서는 우리는 free 함수를 기반으로 하는 메모리의 동적 할당에 대한 이해가 있어야한다. 연결 기반 리스트의 주 특징을 나타내는 구조체를 보여주도록 하겠다. 총 보여줄 연결 리스트의 종류는 3개이다. 하나씩 살펴 보겠다.
단순 연결 리스트 (Singly LinkedList)
typedef struct _node
{
int data; // 데이터를 담을 공간
struct _node * next; // 연결의 도구
} Node;이렇게 나타낼 수 있다. 여기서 포인터 변수인 next는 Node형 구조체 변수로 그 노드 안에다른 구조체 변수를 연결한다고 표현 할 수 있다. 그림으로 표현하면 다음과 같다.
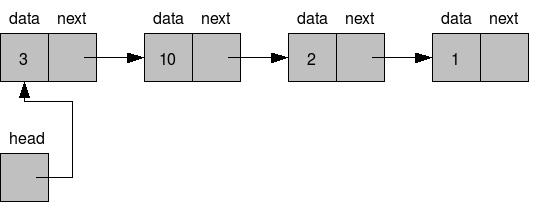
즉, 요약하면 한 노드에 그 노드에 들어가야할 데이터 공간을 가지고 있고, 각 노드의 포인터는 다음 노드를 가리킨다.
이중 연결 리스트 (Doubly LinkedList)
앞서 본, 단순 연결 리스트 같은 경우는 현재 참조하고 있는 노드에서 다음노드로 갈 수는 있었지만, 이전 노드로 가야하는 경우에는 참조하는 노드의 이전 노드를 참조하는 또 하나의 변수가 더 필요했다. 이러한 단점을 해결해주는 노드가 이중 연결 리스트이다. 이중 연결 리스트의 구조를 한번 보자.
typedef struct _node
{
int data;
struct _node * next;
struct _node * prev;
} Node;앞서 본 리스트와의 차이점인 'struct _node *prev'가 포함된 것을 확인할 수 있다. 이는 아래 그림과 같이, 노드를 생성할때 앞 노드와 뒤에 있는 노드를 next와 prev로 연결해주면서 뒤에 있는 노드도 참조하기 편하게 할 수 있음을 확인할 수 있다.

원형 연결 리스트 (Circular LinkedList)
원형 연결 리스트는 먼저 그림부터 보여주고 설명을 진행하도록 하겠다. 원래 단순 연결리스트의 구조에서 head부터 데이터를 추가했다고 가정하였을 때, 마지막 노드의 포인터는 NULL을 가리키는 것을 확인할 수 있는데, NULL이 아닌 헤드를 가리키도록(즉 순환하는 것처럼 보일 수 있다.) 한 형태의 리스트이다. 따라서 리스트의 끝이 존재하지 않기에 참조하는 중간에 탈출 조건을 잘 구성해주지 않으면 무한 루프를 도는 것을 확인할 수 있다.
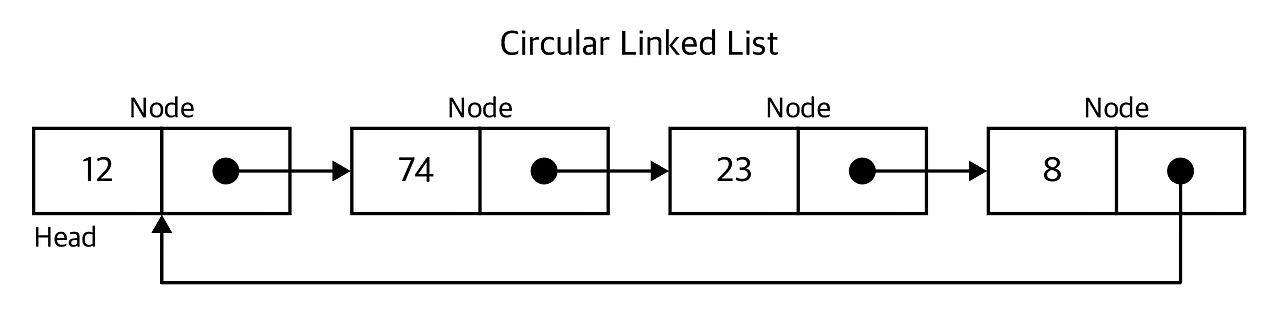
얘는 따로 구조체 코드를 작성하지 않겠다. 그 이유로 하여금 단순 연결 리조트에 생성 하는 코드에 'list->tail->next = list->head' 위와 같은 코드를 적음으로써(tail이라는 변수 없이 참조하는 변수로도 head와 연결할 수 있음.) 해결할 수 있기 때문이다.
다음은 연결 기반 리스트와 배열 기반 리스트의 차이점을 한번 알아보고, 연결 리스트의 시간 복잡도를 알아보도록 하겠다.
연결 기반 리스트 VS 배열 기반 리스트
시간 복잡도
우선, 가장 크게 대표할 수 있는 시간 복잡도의 차이가 존재한다. 자세한 설명은 밑에 더 첨부하도록 하겠다.가장 크게 말하자면, 데이터에 접근하는 경우는 배열을 기반으로 한 리스트가 더 빠르게 접근은 하나(배열 기반 O(1), 연결 기반 O(n)) 데이터를 삽입하거나 삭제하는 경우에는 시간 복잡도는 연결기반이 더 빠르다.
메모리 사용
저번, 배열 기반 리스트의 설명에서 배열 기반 리스트의 단점을 얘기한 바가 있다. 먼저, 배열의 크기를 코드를 시작하기 전에 정의해주어야하기 때문에 남는 공간이 불필요하게 있을 수도 있고, 배열의 크기를 중간에 크게 수정하는 것이 어렵다고 했다. 하지만, 연결 기반 리스트 같은 경우는 필요할 때마다 노드를 생성하며 메모리를 효율적으로 사용함이 가능하다. 다만, 배열 기반에서는 연속적으로 데이터가 저장되어 있기에 데이터를 저장한 공간만 있으면 되지만, 연결 기반은 그 다음 노드의 주소를 저장하는 포이넡를 꼭 추가적으로 필요한다는 차이점이 존재한다.
연결 기반 리스트의 시간복잡도
접근 , 시간 복잡도 : O(n)
head를 기준으로 원하는 인덱스만큼 이동하기 위해 최악의 경우 N번을 이동하는 경우가 생긴다. 만약, 원하는 인덱스가 맨 마지막에 있다면 마지막 노드에 접근하기 위해 Head에서부터 n-1 만큼 이동해야 하기에 시간 복잡도는 n이라고 표현할 수 있다.
탐색 , 시간 복잡도 : O(n)
탐색은 배열과 같은 방법이다. 가장 앞에 있는 노드부터 원하는 데이터를 하나씩 비교하는 선형 탐색 과정을 거쳐야한다. 즉, 최선의 경우 맨 앞에 있는 노드의 데이터가 맞는 경우가 생기겠지만, 찾으려는 데이터가 없거나 맨 마지막에 있는 경우 접근의 경우와 마찬가지로 n개의 노드를 다 확인해야하는 경우가 생길 수 있다. 즉, 최악의 경우 총 n 번의 경우를 다 봐야하기에 시간 복잡도는 n이라고 표현할 수 있다.
삽입/삭제 , 시간 복잡도 : O(1)
삽입, 삭제하는 경우는 주변 노드들의 link를 수정하면 된다. 실행되는 시간은 항상 일정하기에, 시간복잡도는 O(1)로 표현할 수 있다.
이렇게, 두 포스트에 걸쳐 배열 기반, 연결 기반 리스트에 대해 알아봤고, 연결 기반 리스트도 종류를 자세히 알아보았다. 다음은 스택에 대해 학습하고 오도록 하겠다.!
